| Oracle® Database 2 Day DBA 11g Release 2 (11.2) Part Number E10897-10 |
|
|
PDF · Mobi · ePub |
| Oracle® Database 2 Day DBA 11g Release 2 (11.2) Part Number E10897-10 |
|
|
PDF · Mobi · ePub |
This chapter discusses the creation and management of schema objects. It contains the following sections:
A schema is a collection of database objects. A schema is owned by a database user and shares the same name as the user. Schema objects are logical structures created by users. Some objects, such as tables or indexes, hold data. Other objects, such as views or synonyms, consist of a definition only.
Note:
There is no relationship between a tablespace and a schema. Objects in the same schema can use storage in different tablespaces, and a tablespace can contain data from different schemas.Every object in the database belongs to one schema and has a unique name within that schema. Multiple database objects can share the same name, if they are in different schemas. You can use the schema name to unambiguously refer to objects. For example, hr.employees refers to the table named employees in the hr schema. (The employees table is owned by hr.) The terms database object and schema object are used interchangeably.
When you create a database object, you must ensure that you create it in the intended schema. One method is to log in to the database as the user who owns the schema and then create the object. Generally, you place all the objects that belong to a single application in the same schema.
A schema object name must abide by certain rules. In addition to being unique within a schema, a schema object name cannot be longer than 30 bytes and must begin with a letter. If you attempt to create an object with a name that violates any of these rules, then the database raises an error.
You can create and manipulate schema objects with SQL or with Oracle Enterprise Manager Database Control (Database Control).
When creating schema objects using Database Control, you can click the Show SQL button to display the SQL statement that is the equivalent of the schema object properties that you specified with the graphical user interface. Database Control submits this SQL statement to create the schema object. This option shows the statement even if it is incomplete, so you must enter all specifications for the schema object to see the complete SQL statement that Database Control submits.
See Also:
Oracle Database Concepts for more detailed information about schema objects, object names, and data types
As a database administrator (DBA), you can create, modify, and delete schema objects in your own schema and in any other schema. For purposes of this discussion, a database administrator is defined as any user who is granted the DBA role. This includes the SYS and SYSTEM users by default. Oracle recommends granting the DBA role only to those users who require administrative type access.
You can enable other users to manage schema objects without necessarily granting them DBA privileges. For example, a common scenario is to enable an application developer to create, modify, and delete schema objects in his or her own schema. To do so, you grant the RESOURCE role to the application developer.
As described in "Granting Access to Database Control for Nonadministrative Users", you must also grant the developer access to Database Control before he or she can log in to Database Control to manage schema objects. If you do not grant access to Database Control, then the developer must manage schema objects with SQL*Plus or SQL Developer.
The following topics discuss database tables and how to create and modify them:
The table is the basic unit of data storage in an Oracle database. It holds all user-accessible data. Each table is made up of columns and rows. In the employees table, for example, there are columns called last_name and employee_id. Each row in the table represents a different employee, and contains a value for last_name and employee_id.
When you create a table, you specify the table type, and define its columns and constraints. Constraints are rules that help preserve data integrity.
This section contains the following topics:
The most common type of table in an Oracle database is a relational table, which is structured with simple columns similar to the employees table. Two other table types are supported: object tables and XMLType tables. Any of the three table types can be defined as permanent or temporary. Temporary tables hold session-private data that exists only for the duration of a transaction or session. They are useful in applications where a results set must be held temporarily in memory, perhaps because the results set is constructed by running multiple operations.
You can build relational tables in either heap or index-organized structures. In heap structures, the rows are not stored in any particular order. In index-organized tables, the row order is determined by the values in one or more selected columns. For some applications, index-organized tables provide enhanced performance and more efficient use of disk space.
This section describes permanent, heap-organized tables. For information about other table types and when to use them, see Oracle Database Administrator's Guide, Oracle Database Concepts, and Oracle Database Performance Tuning Guide. For the syntax required to create and alter tables with SQL, see Oracle Database SQL Language Reference.
You define table columns to hold your data. When you create a column, you specify the following attributes:
The data type attribute defines the kind of data to be stored in the column. When you create a table, you must specify a data type for each of its columns.
Data types define the domain of values that each column can contain. For example, DATE columns cannot accept the value February 29 (except for a leap year) or the values 2 or SHOE. Each value subsequently inserted in a column assumes the column data type. For example, if you insert 17-JAN-2004 into a date column, then Oracle Database treats that character string as a date value after verifying that it converts to a valid date.
Table 8-1 lists some common Oracle Database built-in data types.
| Data Type | Description |
|---|---|
|
Variable-length character string having a maximum length of You can use the See Oracle Database Globalization Support Guide for more information. |
|
|
Number having precision |
|
|
A composite value that includes both a date and time component. For each |
|
|
A character large object (CLOB) containing single-byte or multibyte characters. Both fixed-width and variable-width character sets are supported, both using the database character set. The maximum size is (4 gigabytes - 1) * (database block size). For example, for a block size of 32K, the maximum CLOB size is 128 terabytes. |
Constraints determine valid values for the column. In Oracle Enterprise Manager Database Control (Database Control), the only constraint you can define at the column level on the Create Table page is the NOT NULL constraint, which requires that a value be included in the column whenever a row is inserted or updated. Unlike other constraints described in "About Table-Level Constraints", which can be defined as part of the column definition or part of the table definition, the NOT NULL constraint must be defined as part of the column definition.
Use a NOT NULL constraint when data must be supplied for a column for the integrity of the database. For example, if all employees must belong to a specific department, then the column that contains the department identifier must be defined with a NOT NULL constraint. However, do not define a column as NOT NULL if the data can be unknown or may not exist when rows are added or changed. An example of a column for which you must not use a NOT NULL constraint is the second, optional line in a mailing address.
The database automatically adds a NOT NULL constraint to the column or columns included in the primary key of a table.
This value is automatically stored in the column whenever a new row is inserted without a value being provided for the column. You can specify a default value as a literal or as an expression. However, there are limitations on how you construct the expression. See Oracle Database SQL Language Reference for details.
You can enable automatic encryption for column data. See the discussion of transparent data encryption in Oracle Database 2 Day + Security Guide for more information.
In an Oracle database, you can apply rules to preserve the integrity of your data. For example, in a table that contains employee data, the employee name column cannot accept NULL as a value. Similarly, in this table, you cannot have two employees with the same ID.
Oracle Database enables you to apply data integrity rules called constraints, both at the table level and at the column level. Any SQL statement that attempts to insert or update a row that violates a constraint results in an error, and the statement is rolled back. Likewise, any attempt to apply a new constraint to a populated table also results in an error if any existing rows violate the new constraint.
The types of constraints that you can apply at the table level are as follows:
Primary Key—Requires that a column (or combination of columns) be the unique identifier of the row. A primary key column does not allow NULL values.
Unique Key—Requires that no two rows can have duplicate values in a specified column or combination of columns. The set of columns is considered to be a unique key.
Check—Requires that a column (or combination of columns) satisfy a condition for every row in the table. A check constraint must be a Boolean expression. It is evaluated each time that a row is inserted or updated. An example of a check constraint is: SALARY > 0.
Foreign Key—Requires that for a particular column (or combination of columns), all column values in the child table exist in the parent table. The table that includes the foreign key is called the dependent or child table. The table that is referenced by the foreign key is called the parent table. An example of a foreign key constraint is where the department column of the employees table must contain a department ID that exists in the parent department table.
Constraints can be created and usually modified with different statuses. The options include enabled or disabled, which determine if the constraint is checked when rows are added or modified, and deferred or immediate, which cause constraint validation to occur at the end of a transaction or at the end of a statement, respectively.
See Also:
Oracle Database Concepts for more information about constraints
This section describes some additional considerations for creating tables. It contains the following topics:
Your new table can include one or more columns defined with user-defined types. User-defined types enable a single column in a single row to contain multiple values. The multiple values can be represented as arrays, nested tables, or objects, where an object type represents a real-world entity such as a purchase order. (Retrieving a purchase order–type column value could return a record that contains purchase order number, customer number, amount, and so on.) User-defined types are created with the CREATE TYPE statement and are described in detail in Oracle Database SQL Language Reference.
Large object (LOB) columns are used to contain unstructured data (such as text or streaming video), and can hold terabytes of information. In Oracle Database 11g, you can use SecureFiles, the next generation LOB data type, which provide high performance, easier manageability, and full backward compatibility with existing LOB interfaces. SecureFiles also offer advanced features such as intelligent data compression, deduplication and transparent encryption. The LOB implementation available in Oracle Database 10g Release 2 and prior releases is still supported for backward-compatibility reasons and is now referred to as BasicFiles. If you add a LOB column to a table, then you can specify whether it should be created as a SecureFile or a BasicFile. If you do not specify the storage type, then the LOB is created as a BasicFile to ensure backward compatibility.
When creating a table that contains one or more LOB columns, select the LOB column, then click Advanced Attributes on the General subpage of the Create Table page to specify the storage type (BasicFile or SecureFile) and the storage options for the LOB column. To specify the same storage type and storage options for all LOB columns in a table, click Set Default LOB Attributes.
You can partition tables and indexes. Partitioning helps to support very large tables and indexes by enabling you to divide the tables and indexes into smaller and more manageable pieces called partitions. SQL queries and DML statements do not have to be modified to access partitioned tables and indexes. Partitioning is transparent to the application.
After partitions are defined, certain operations become more efficient. For example, for some queries, the database can generate query results by accessing only a subset of partitions, rather than the entire table. This technique (called partition pruning) can provide order-of-magnitude gains in improved performance. In addition, data management operations can take place at the partition level, rather than on the entire table. This results in reduced times for operations such as data loads; index creation and rebuilding; and backup and recovery.
Each partition can be stored in its own tablespace, independent of other partitions. Because different tablespaces can be on different disks, this provides a table structure that can be better tuned for availability and performance. Storing partitions in different tablespaces on separate disks can also optimize available storage usage, because frequently accessed data can be placed on high-performance disks, and infrequently retrieved data can be placed on less expensive storage.
Partitioning is useful for many types of applications that manage large volumes of data. Online transaction processing (OLTP) systems often benefit from improvements in manageability and availability, while data warehousing systems benefit from increased performance and manageability.
You can specify several storage attributes for a table. For example, you can specify the initial size of the table on disk. For more information about setting storage attributes for a table, see Oracle Database Administrator's Guide and Oracle Database SQL Language Reference.
Table Compression is suitable for both OLTP applications and data warehousing applications. Compressed tables require less disk storage and result in improved query performance due to reduced I/O and buffer cache requirements. Compression is transparent to applications and incurs minimal overhead during bulk loading or regular DML operations such as INSERT, UPDATE or DELETE. You can configure table compression on the Storage subpage of the Create Table page.
See Also:
Oracle Database Administrator's Guide for design and management considerations for different table types
Oracle Database Concepts and Oracle Database VLDB and Partitioning Guide for more information about partitioned tables and indexes
Oracle Database Concepts for more information about LOBs, SecureFiles and BasicFiles
You can use Database Control to list all the tables in a specified schema, and to view the definitions of individual tables.
Go to the Database Home page, logging in as user SYSTEM.
At the top of the page, click Schema to view the Schema subpage.
In the Database Objects section, click Tables.
The Tables page appears.
In the Schema field, enter the name of a schema. Alternatively, click the flashlight icon adjacent to the Schema field to search for a schema.
Examples of schema names include SYS and hr.
Leave the Object Name field blank to search for and display all tables in the schema. Alternatively, enter a table name or partial table name to limit the search.
If you enter a search string in the Object Name field, then all tables that have names that start with the search string are displayed. If you precede the search string with an asterisk (*), then all tables that have the search string anywhere in the table name are displayed.
Click Go.
The tables in the specified schema are displayed.
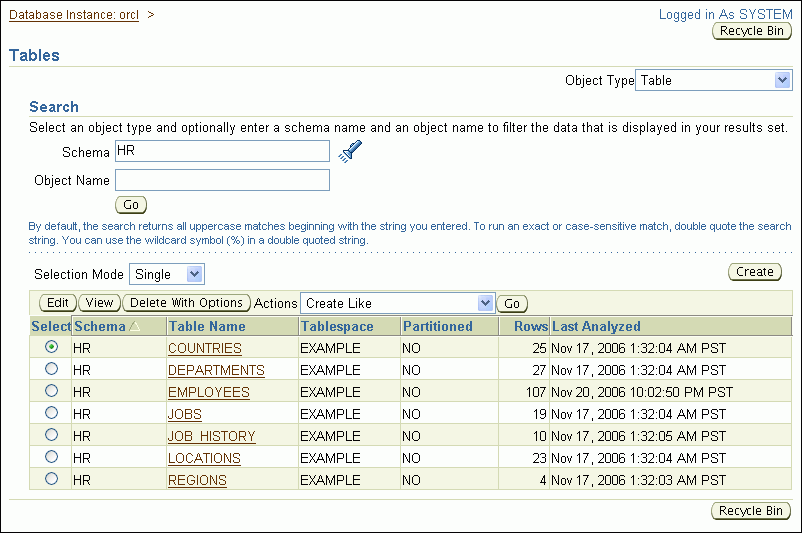
To view the definition of a particular table, select the table and then click View. Alternatively, click the table name.
The View Table page appears.
See Also:
Besides viewing table names and table definitions, you can view the data stored in the table, and the SQL statement used to display the data. You can also change the SQL statement to alter the results set.
Search for a table as described in "Viewing Tables". For example, search for the tables in the hr schema.
Select the table that contains the data.
For example, select employees.
In the Actions list, select View Data, and then click Go.
The View Data for Table page appears.
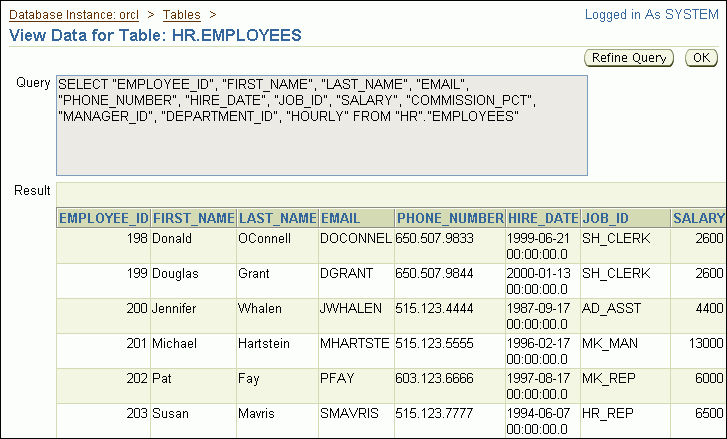
The Query field displays the SQL query that was run to view the data for the table. The Result section shows the data in the table. You may have to use the horizontal scroll bar at the bottom of the page to view all columns.
(Optional) Click a column name to sort the data by that column.
(Optional) Click Refine Query to change the query and redisplay the data.
The Refine Query for Table page appears. This page enables you to select the columns to display. It also enables you to specify a WHERE clause for the SQL SELECT statement to limit the results.
You can also write and submit your own SQL SELECT statement to see the contents of a table. You can run SQL statements by starting a SQL Worksheet session in Database Control. To do so, click SQL Worksheet in the Related Links section of the Database Home page.
A detailed description of the SELECT statement is in Oracle Database SQL Language Reference.
See Also:
You can use Database Control to create a table. Before you create and populate a table, you can estimate its size to ensure that you have sufficient space to hold its data.
In the following example, you create a table called purchase_orders in the nick schema that you created in Chapter 7, "Administering User Accounts and Security". The table has the following columns:
| Column Name | Data Type | Size | Not NULL |
|---|---|---|---|
PO_NUMBER |
NUMBER |
Yes | |
PO_DESCRIPTION |
VARCHAR2 |
200 | No |
PO_DATE |
DATE |
Yes | |
PO_VENDOR |
NUMBER |
Yes |
To create the PURCHASE_ORDERS table in the NICK schema:
Go to the Database Home page, logging in as user nick or as user SYSTEM.
At the top of the page, click Schema to view the Schema subpage.
In the Database Objects section, click Tables.
The Tables page appears.
Click Create.
The Create Table: Table Organization page appears.
Select Standard, Heap Organized, and then click Continue.
The Create Table page appears.
In the Name field, enter purchase_orders as the table name, and in the Schema field, enter nick.
Because a default tablespace was specified when creating the user nick in the section "Example: Creating a User Account", accept the default tablespace setting for the table.
In the Columns section, enter column information for the purchase_orders table as specified in the table in the introduction to this topic. For example, for the first column in the purchase_orders table, enter the name PO_NUMBER and the data type NUMBER, and select the Not NULL check box.
For all purchase_orders columns, you can leave Scale and Default Value blank.
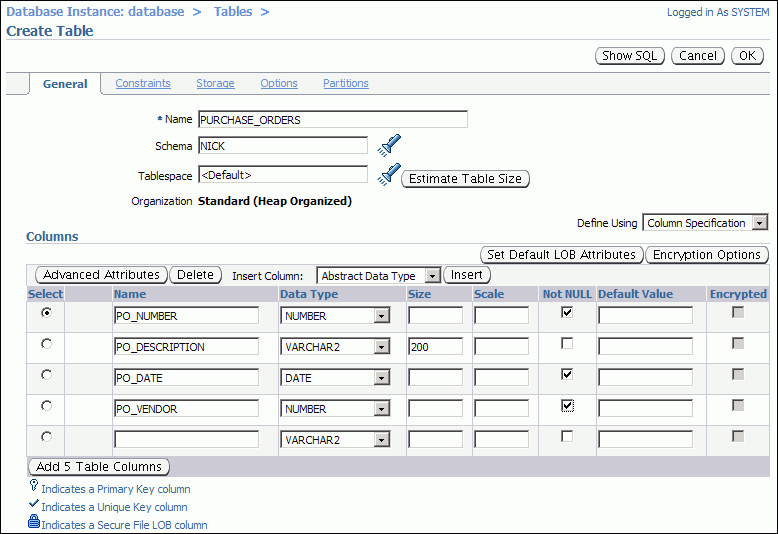
Note:
To create the table with partitions, click Partitions at the top of the page during this step.(Optional) Obtain an estimate of the table size by completing the following steps:
Click Estimate Table Size.
The Estimate Table Size page appears.
In the Projected Row Count field, enter 400000 (four hundred thousand), and then click Estimate Table Size.
The estimated results are calculated and displayed.
Click OK to return to the Create Table page.
The estimate of the table size can help you determine what values to use when specifying the storage parameters for the table.
Click Constraints to view the Constraints subpage, where you can designate a primary key for the table.
In the Constraints list, select PRIMARY, then click Add.
The Add PRIMARY Constraint page appears.
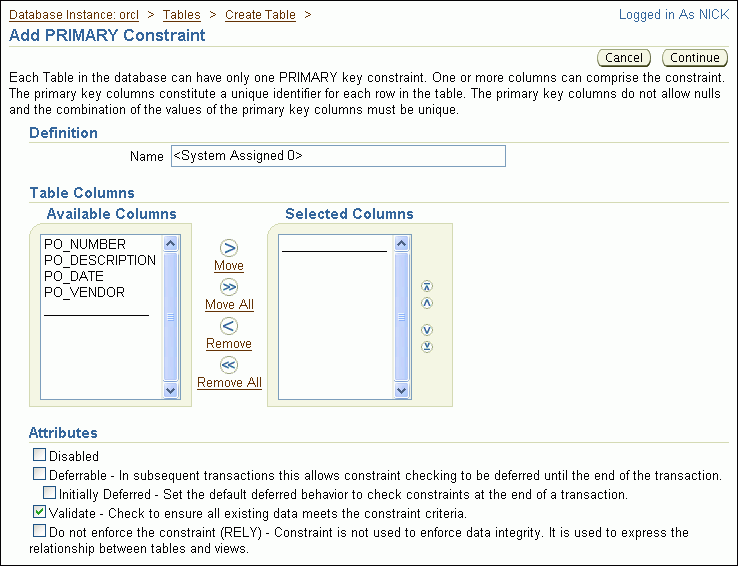
In the Available Columns list, select PO_NUMBER, and then click Move.
Note:
You can also double-clickPO_NUMBER.The po_number column moves to the Selected Columns list.
Click Continue to return to the Constraints subpage of the Create Table page.
Click OK.
The Tables page returns, showing a confirmation message and listing the new table in the tables list. The purchase_orders table is now created with po_number as its primary key.
See Also:
You can use Database Control to add and delete table columns and to manage table constraints. This section contains the following topics:
See Also:
In this example, you add columns to the purchase_orders table that you created previously in "Example: Creating a Table". The two new columns are named po_date_received and po_requestor_name.
To add columns to the PURCHASE_ORDERS table:
Go to the Database Home page, logging in as user nick or as user SYSTEM.
At the top of the page, click Schema to view the Schema subpage.
In the Database Objects section, click Tables.
The Tables page appears.
In the Schema field, enter nick, and then click Go.
All tables owned by user nick are displayed.
Select the PURCHASE_ORDERS table, and then click Edit.
The Edit Table page appears.
In the Columns section, in the first available row, enter the following information about the new po_date_received column:
| Field Name | Value |
|---|---|
Name |
PO_DATE_RECEIVED |
Data Type |
DATE |
You can leave Size, Scale, Not NULL, and Default Value blank.
In the next available row, enter the following information about the new po_requestor_name column:
| Field Name | Value |
|---|---|
Name |
PO_REQUESTOR_NAME |
Data Type |
VARCHAR2 |
Size |
40 |
You can leave Scale, Not NULL, and Default Value blank.
Click Apply.
An update message appears indicating that the table has been modified successfully.
See Also:
In this example, you delete the po_requestor_name column that you added to the purchase_orders table in "Example: Adding Table Columns".
To delete the PO_REQUESTOR_NAME column:
Go to the Database Home page, logging in as user nick or as user SYSTEM.
At the top of the page, click Schema to view the Schema subpage.
In the Database Objects section, click Tables.
The Tables page appears.
In the Schema field, enter nick and then click Go.
All tables owned by user nick are displayed.
Select the PURCHASE_ORDERS table, and then click Edit.
The Edit Table page appears.
In the Columns section, select the PO_REQUESTOR_NAME column, and then click Delete.
The row that contained the information for the deleted column becomes blank.
Click Apply.
An update message appears indicating that the table has been modified successfully.
See Also:
In this example, you add a table constraint to the purchase_orders table that you created in "Example: Creating a Table". To enforce the rule that the po_date_received value must be either the same day as, or later than, the value of po_date, you add a check constraint.
Note:
You can also add constraints during table creation, as shown in "Example: Creating a Table". In that example, you added a primary key constraint.To add a table constraint to the PURCHASE_ORDERS table:
Go to the Database Home page, logging in as user nick or as user SYSTEM.
At the top of the page, click Schema to view the Schema subpage.
In the Database Objects section, click Tables.
The Tables page appears.
In the Schema field, enter nick and then click Go.
All tables owned by user nick are displayed.
Select the PURCHASE_ORDERS table, and then click Edit.
The Edit Table page appears.
Click Constraints to display the Constraints subpage.
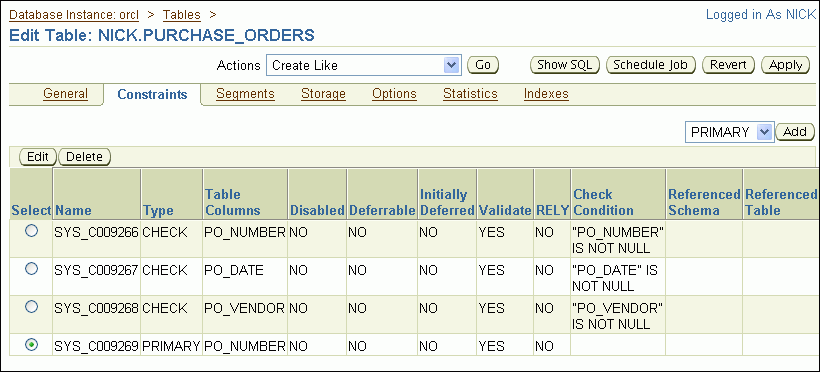
In the list adjacent to the Add button, select CHECK, and then click Add.
The Add CHECK Constraint page appears.
In the Name field, enter po_check_rcvd_date, overwriting the system-assigned default name.
In the Check Condition field, enter the following:
po_date_received >= po_date
This expression indicates that po_date_received must be greater than or equal to po_date. For date columns, this is equivalent to stating that po_date_received must be on the same day as, or later than, po_date.
Click Continue
The new constraint appears on the Constraints subpage.
Click Apply.
A confirmation message appears.
There are a few ways in which you can modify a table constraint. You can change the status of an existing table constraint, for example, from an enabled state to a disabled state. In this example, you disable the check constraint that you created for the purchase_orders table in "Example: Adding a New Table Constraint".
To disable a constraint for the PURCHASE_ORDERS table:
Go to the Database Home page, logging in as user nick or as user SYSTEM.
At the top of the page, click Schema to view the Schema subpage.
In the Database Objects section, click Tables.
The Tables page appears.
In the Schema field, enter nick and then click Go.
All tables owned by user nick are displayed.
Select the purchase_orders table, and then click Edit.
The Edit Table page appears.
Click Constraints to display the Constraints subpage.
Select the constraint named PO_CHECK_RCVD_DATE, and then click Edit.
The Edit CHECK Constraint page appears.
In the Attributes section, select Disabled, and then click Continue.
Click Apply.
A confirmation message appears. The Disabled column shows that the check constraint has been disabled.
You can delete constraints from a table with Database Control. Deleting a table constraint may cause the deletion of other constraints. For example, if you delete the primary key constraint from a table (the parent table) that is referenced in a foreign key constraint in another table (the child table), then the foreign key constraint in the child table is also deleted through a cascading delete mechanism.
In this example, you delete the check constraint that you created for the purchase_orders table in "Example: Adding a New Table Constraint".
To delete a constraint from the PURCHASE_ORDERS table:
Go to the Database Home page, logging in as user nick or as user SYSTEM.
At the top of the page, click Schema to view the Schema subpage.
In the Database Objects section, click Tables
The Tables page appears.
In the Schema field, enter NICK and then click Go.
All tables owned by user NICK are displayed.
Select the PURCHASE_ORDERS table, and then click Edit.
The Edit Table page appears.
Click Constraints to display the Constraints subpage.
Select the constraint named PO_CHECK_RCVD_DATE, and then click Delete.
The check constraint is removed from the list.
Click Apply.
A confirmation message appears.
See Also:
Oracle Database Concepts for more information about the cascading delete mechanism
You can use Database Control to load data into a table. You can load data from a source file that is on your local computer—the one where your browser is running—or from a source file that is on the database host computer—the computer on which the Oracle instance is running. Because Database Control invokes the Oracle SQL*Loader utility to load the data, the format of the data in the source file can be of any format that is supported by SQL*Loader. In this example, you use a comma-delimited text file as the source file. In SQL*Loader terminology, the source file is referred to as the data file.
SQL*Loader also uses a control file to control the loading of data from the data file. The control file is a text file that contains statements written in the SQL*Loader command language. These statements specify where to find the data, how to parse and interpret the data, where to insert the data, and more. Database Control contains a Load Data wizard that takes you through the steps of preparing and running a data load job with SQL*Loader. (A wizard is an online, guided workflow.) The Load Data wizard can automatically create the SQL*Loader control file for you.
Note:
The SQL*Loader control file is unrelated to the database control files described in "About Control Files".In this example, you load data into the PURCHASE_ORDERS table that you created in "Example: Creating a Table". For simplicity, this example loads only three rows.
To prepare for this example, you must create a text file named load.dat on the file system of the database host computer or on the file system of your local computer. The contents of the file should be as follows:
1, Office Equipment, 25-MAY-2006, 1201, 13-JUN-2006 2, Computer System, 18-JUN-2006, 1201, 27-JUN-2006 3, Travel Expense, 26-JUN-2006, 1340, 11-JUL-2006
Note:
This example assumes that the columns in thePURCHASE_ORDERS table are the following: PO_NUMBER, PO_DESCRIPTION, PO_DATE, PO_VENDOR, and PO_DATE_RECEIVED. If your PURCHASE_ORDERS table does not have all these columns (or has additional columns), then modify the data in the text file accordingly.To load data into the PURCHASE_ORDERS table:
Go to the Database Home page, logging in as user SYSTEM.
At the top of the page, click Data Movement.
The Data Movement subpage appears.
In the Move Row Data section, click Load Data from User Files.
The Load Data: Generate or Use Existing Control File page appears.
Select Automatically Generate Control File, and enter host computer credentials (user name and password) for the database host computer.
Click Continue.
The first page of the Load Data wizard appears. Its title is Load Data: Data Files.
Follow the steps in the wizard, clicking Next to proceed to each new step.
For information about using any of the wizard pages, click Help on that page. At the conclusion of the wizard, you submit a job that runs SQL*Loader. A job status page is then displayed. If necessary, refresh the status page until you see a succeeded (or failed) status.
If the job succeeded, then confirm that the data was successfully loaded by doing one of the following:
View the table data.
See "Viewing Table Data".
Examine the SQL*Loader log file, which is written to the host computer directory that you designated for the SQL*Loader data file.
Note:
If the job succeeds, then it means only that Database Control was able to run the SQL*Loader utility. It does not necessarily mean that SQL*Loader ran without errors. For this reason, you must confirm that the data loaded successfully.If the job failed, then examine the SQL*Loader log file, correct any errors, and try again.
See Also:
Oracle Database Utilities for more information about SQL*Loader
If you no longer need a table, then you can delete it using Database Control. When you delete a table, the database deletes the data and dependent objects of the table (such as indexes), and removes the table from the data dictionary.
When you delete a table from a locally managed tablespace that is not the SYSTEM tablespace, the database does not immediately reclaim the space associated with the table. Instead, it places the table and any dependent objects in the recycle bin. You can then restore the table, its data, and its dependent objects from the recycle bin if necessary. You can view the contents of the recycle bin by clicking Recycle Bin on the Tables page. Note that users can see only tables that they own in the recycle bin. See Oracle Database Administrator's Guide for more information about the recycle bin, including how to view, purge, and recover tables for which you are not the owner.
Search for the table to delete, as explained in "Viewing Tables".
Select the table, and then click Delete With Options.
The Delete With Options page appears.
Select Delete the table definition, all its data, and dependent objects (DROP).
Select Delete all referential integrity constraints (CASCADE CONTRAINTS).
Click Yes.
The Tables page returns and displays a confirmation message.
See Also:
The following topics describe how to create and manage indexes:
Indexes are optional schema objects that are associated with tables. You create indexes on tables to improve query performance. Just as the index in a guide helps you to quickly locate specific information, an Oracle Database index provides quick access to table data.
You can create as many indexes on a table as you need. You create each index on one or more columns of a table. For example, in a purchase orders table, if you create an index on the vendor number column, then you can then sequentially access the rows of the table in vendor number order, without having to actually sort the rows. Additionally, you can directly access all purchase orders issued to a particular vendor without having to scan the entire table.
After an index is created, it is automatically maintained and used by the database. Changes to the data or structure of a table, such as adding new rows, updating rows, or deleting rows, are automatically incorporated into all relevant indexes. This is transparent to the user.
Some indexes are created implicitly through constraints that are placed on a table. For example, the database automatically creates an index on the columns of a primary key constraint or unique key constraint.
The following topics provide more background information about indexes:
Indexes generally improve the performance of queries and DML statements that operate on a single, existing row or a small number of existing rows. However, too many indexes can increase the processing overhead for statements that add, modify, or delete rows.
To determine if you can improve application performance with more indexes, you can run the SQL Access Advisor in Oracle Enterprise Manager Database Control (Database Control). See "Running the SQL Access Advisor".
Before you add additional indexes, examine the performance of your database for queries and DML. You can then compare performance after the new indexes are added.
See Also:
Oracle Database Real Application Testing User's Guide for information about using the SQL Performance Analyzer to analyze the SQL performance impact of any type of schema or system changes
Indexes can be created in several ways, using various combinations of index attributes. The primary index attributes are the following:
A standard, B-tree index contains an entry for each value in the index key along with a disk address of the row where the value is stored. A B-tree index is the default and most common type of index in an Oracle database.
A bitmap index uses strings of bits to encapsulate values and potential row addresses. It is more compact than a B-tree index and can perform some types of retrieval more efficiently. For general use, however, a bitmap index requires more overhead during row operations on the table and should be used primarily for data warehouse environments, as described in Oracle Database Data Warehousing Guide.
The default search through an index is from lowest to highest value, where character data is sorted by ASCII values, numeric data from smallest to largest number, and date from the earliest to the latest value. This default search method is performed in indexes created as ascending indexes. You can cause index searches to reverse the search order by creating the related index with the descending option.
Typically, an index entry is based on the value or values found in the column or columns of a table. This is a column index. Alternatively, you can create a function-based index in which the indexed value is derived from the table data. For example, to find character data that can be in various combinations of upper and lowercase letters, you can use a function-based index based on the UPPER() function to look for the values as if they were all in uppercase characters.
Single-Column and Concatenated
You can create an index on just one column, which is called a single-column index, or on multiple columns, which is called a concatenated index. Concatenated indexes are useful when all the index columns are likely to be included in the WHERE clause of frequently executed SQL statements.
Nonpartitioned and Partitioned
As with tables, you can partition an index. In most situations, it is useful to partition an index when the associated table is partitioned, and to partition the index using the same partitioning scheme as the table. (For example, if the table is range-partitioned by sales date, then you create an index on sales date and partition the index using the same ranges as the table partitions.) This is known as a local partitioned index. However, you do not have to partition an index using the same partitioning scheme as its table. You can also create a nonpartitioned, or global, index on a partitioned table.
See Also:
Oracle Database Concepts for design and management considerations of different index types
Oracle Database SQL Language Reference for the syntax to create indexes
Oracle Database VLDB and Partitioning Guide for more information about partitioned tables and indexes
You use the Indexes page of Database Control to view the indexes in your database.
Go to the Database Home page, logging in as user SYSTEM.
At the top of the page, click Schema to view the Schema subpage.
In the Database Objects section, click Indexes.
The Indexes page appears.
In the Search By list, do one of the following:
Select Index Name to search for indexes by name.
Every index has a system-assigned or user-assigned name.
Select Table Name to search for indexes that belong to a particular table.
In the Schema field, enter the name of a schema. Alternatively, click the flashlight icon adjacent to the Schema field to search for a schema.
Do one of the following:
If you are searching by index name, then leave the Object Name field blank to search for and display all indexes in the schema. Alternatively, enter an index name or partial index name as a search string.
If you enter a search string in the Object Name field, then all indexes that have names that start with the search string are displayed. If you precede the search string with an asterisk (*), then all indexes that have the search string anywhere in the index name are displayed.
If you are searching by table name, then enter a table name or partial table name in the Object Name field.
If you enter a partial table name as a search string, then indexes are displayed for all tables that have names that start with the search string. If you precede the search string with an asterisk (*), then indexes are displayed for all tables that have the search string anywhere in the table name.
Click Go.
The indexes in the specified schema are displayed.
To view the definition of a particular index, select the index and then click View. Alternatively, double-click the index name.
The View Index page appears. This page includes basic information about the index, including its status, the table and column or columns on which it is built, the space used by the index, the options used in its definition, and index statistics.
See Also:
When you create an index, you specify one or more table columns to be indexed and the type of index to create.
In this example, you create a standard B-tree index on the SUPPLIER_ID column in the SH.PRODUCTS table. (The SH schema is part of the sample schemas.)
To create a supplier index on the SH.PRODUCTS table:
View the tables in the SH schema, by following the instructions in the section "Viewing Tables".
Select the PRODUCTS table.
In the Actions list, select Create Index, and then click Go.
The Create Index page appears.
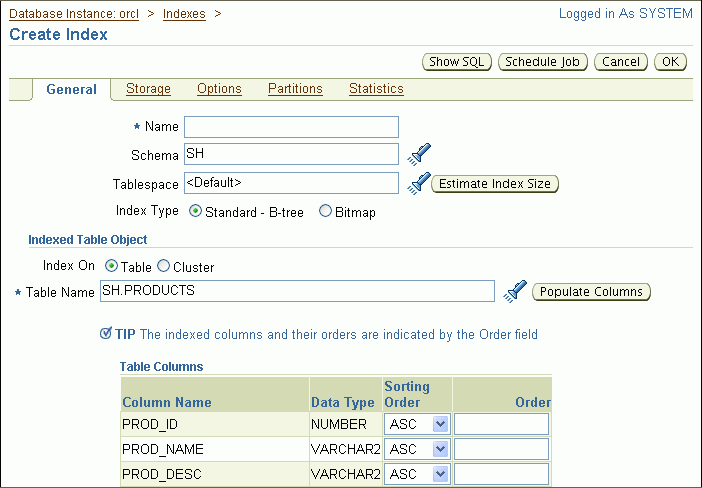
Enter the following information:
In the Name field, enter PRODUCTS_SUPPLIER_IDX.
For the Tablespace field, accept the default value.
For Index Type, select Standard - B-tree.
In the Table Columns list, select the SUPPLIER_ID column by entering 1 in the Order column.
If your index were to consist of multiple columns (a concatenated index), then you would enter 2 in the next column to include, and so on. These numbers indicate the order in which the columns are to be concatenated, from left to right, or from most significant in the sort order to least significant.
For Sorting Order, accept the default selection of ASC (ascending).
Click OK to create the index.
The Indexes page returns and displays a confirmation message. The new index is listed in the table of indexes.
See Also:
If you no longer need an index, then you can delete it using Database Control.
In this example, you delete the PRODUCTS_SUPPLIER_IDX index that you created previously on the SH.PRODUCTS table in "Example: Creating an Index".
Note:
You cannot delete an index that is currently used to enforce a constraint. You must disable or delete the constraint and then, if the index is not deleted as a result of that action, delete the index.To delete the supplier index on the SH.PRODUCTS table:
Go to the Database Home page, logging in as user SYSTEM.
At the top of the page, click Schema to view the Schema subpage.
In the Database Objects section, click Indexes.
The Indexes page appears.
In the Search By list, select Table Name.
In the Schema field, enter SH.
In the Object Name field, enter PROD.
You can enter only the first few letters of the table name.
Click Go.
All indexes on the PRODUCTS table are displayed.
Select the PRODUCTS_SUPPLIER_IDX index, and then click Delete.
A confirmation page appears.
Click Yes to delete the index.
The Indexes page returns and displays a confirmation message.
See Also:
The following topics describe how to create and manage views:
Views are customized presentations of data in one or more tables or other views. You can think of them as stored queries. Views do not actually contain data, but instead derive their data from the tables upon which they are based. These tables are referred to as the base tables of the view.
Similar to tables, views can be queried, updated, inserted into, and deleted from, with some restrictions. All operations performed on a view actually affect the base tables of the view. Views can provide an additional level of security by restricting access to a predetermined set of rows and columns of a table. They can also hide data complexity and store complex queries.
Many important views are in the SYS schema. There are two types: static data dictionary views and dynamic performance views. Complete descriptions of the views in the SYS schema are in Oracle Database Reference.
The data dictionary views are called static views because they change infrequently, only when a change is made to the data dictionary. Examples of data dictionary changes include creating a new table or granting a privilege to a user.
Many data dictionary tables have three corresponding views:
A DBA_ view displays all relevant information in the entire database. DBA_ views are intended only for administrators.
An example of a DBA_ view is DBA_TABLESPACES, which contains one row for each tablespace in the database.
An ALL_ view displays all the information accessible to the current user, including information from the schema of the current user, and information from objects in other schemas, if the current user has access to those objects through privileges or roles.
An example of an ALL_ view is ALL_TABLES, which contains one row for every table for which the user has object privileges.
A USER_ view displays all the information from the schema of the current user. No special privileges are required to query these views.
An example of a USER_ view is USER_TABLES, which contains one row for every table owned by the user.
The columns in the DBA_, ALL_, and USER_ views are usually nearly identical.
Dynamic performance views monitor ongoing database activity. They are available only to administrators. The names of dynamic performance views start with the characters V$. For this reason, these views are often referred to as V$ views.
An example of a V$ view is V$SGA, which returns the current sizes of various System Global Area (SGA) memory components.
You can use Oracle Enterprise Manager Database Control (Database Control) to list the views in a specified schema. You can also display the view definitions.
Go to the Database Home page, logging in as user SYSTEM.
At the top of the page, click Schema to view the Schema subpage.
In the Database Objects section, click Views.
The Views page appears.
In the Schema field, enter the name of a schema. Alternatively, click the flashlight icon adjacent to the Schema field to search for a schema.
Examples of schema names include SYS and hr.
Leave the Object Name field blank to search for and display all views in the schema. Alternatively, enter a view name or partial view name to limit the search.
If you enter a search string in the Object Name field, then all views that have names that start with the search string are displayed. If you precede the search string with an asterisk (*), then all views that have the search string anywhere in the view name are displayed.
Click Go.
The views in the specified schema are displayed.
To view the definition of a particular view, select the view and then click View. Alternatively, double-click the view name.
The View page appears.
See Also:
In this example, you create a view named king_view, which uses the hr.employees table as its base table. (The hr schema is part of the sample schemas.) This view filters the table data so that only employees who report directly to the manager King, whose employee ID is 100, are returned in queries. In an application scenario, this view adds an additional level of security to the hr.employees table while providing a suitable presentation of relevant information for manager King.
To create the KING_VIEW view on the HR.EMPLOYEES table:
Go to the Database Home page, logging in as user hr or as user SYSTEM.
At the top of the page, click Schema to view the Schema subpage.
In the Database Objects section, click Views.
The Views page appears.
Click Create.
The Create View page appears.
Enter the following information:
In the Name field, enter king_view.
In the Schema field, enter hr.
In the Query Text field, enter the following SQL statement:
SELECT * FROM hr.employees WHERE manager_id = 100
Click OK.
The Views page returns and displays a confirmation message. The new view appears in the list of views.
To test the new KING_VIEW view:
On the Views page, select king_view and then select View Data from the Actions list.
Click Go.
The View Data for View page appears. The data selected by the view appears in the Result section.
(Optional) You can also test the view by submitting the following SQL statement in SQL*Plus or SQL Developer:
SELECT * FROM king_view
See Also:
If you no longer need a view, then you can delete it using Database Control.
In this example, you delete the hr.king_view view that you created previously in "Example: Creating a View".
To delete the HR.KING_VIEW view:
Go to the Database Home page, logging in as user SYSTEM.
At the top of the page, click Schema to view the Schema subpage.
In the Database Objects section, click Views.
The Views page appears.
In the Schema field, enter hr.
In the Object Name field, enter king.
You can enter just the first few letters of the view name.
Click Go.
KING_VIEW is displayed in the list of views.
Select KING_VIEW, and then click Delete.
A Confirmation page appears.
Click Yes to delete the view.
The Views page returns and displays a confirmation message.
See Also:
This section describes your responsibilities as a database administrator (DBA) for program code that is stored in the database. It contains the following topics:
Oracle Database offers the ability to store program code in the database. Developers write program code in PL/SQL or Java, and store the code in schema objects. You, as the DBA, can use Oracle Enterprise Manager Database Control (Database Control) to manage program code objects such as:
PL/SQL packages, procedures, functions, and triggers
Java source code (Java sources) and compiled Java classes
The actions that you can perform include creating, compiling, creating synonyms for, granting privileges on, and showing dependencies for these code objects. You access administration pages for these objects by clicking links in the Programs section of the Schema subpage.
Note that creating and managing program code objects is primarily the responsibility of application developers. However, as a DBA you might have to assist in managing these objects. Your most frequent task for program code objects might be to revalidate (compile) them, because they can become invalidated if the schema objects on which they depend change or are deleted.
Note:
Other types of schema objects besides program code objects can become invalid. For example, if you delete a table, then any views that reference that table become invalid.See Also:
Oracle Database Concepts for an overview of using PL/SQL and Java for server-side programming
Oracle Database 2 Day + Java Developer's Guide for more information about Java sources and Java classes
Oracle Database PL/SQL Language Reference to learn about PL/SQL code
Oracle Database Administrator's Guide for more information about object invalidation
As a database administrator (DBA), you may be asked to revalidate schema objects that have become invalid. Schema objects (such as triggers, procedures, or views) might be invalidated when changes are made to objects on which they depend. For example, if a PL/SQL procedure contains a query on a table and you modify table columns that are referenced in the query, then the PL/SQL procedure becomes invalid. You revalidate schema objects by compiling them.
Note:
It is not always possible to revalidate a schema object that stores program code by compiling it. You may have to take remedial actions first. For example, if a view becomes invalid because a table that it references is deleted, then compiling the view produces an error message that indicates that the table does not exist. You cannot validate the view until you re-create the table or retrieve it from the recycle bin.Database Control notifies you when schema objects become invalid by displaying an alert in the Alerts section of the Database Home page.
There are two ways to display schema objects that require validation: by following an alert on the Database Home page, or by viewing the appropriate object page (Views page, Procedures page, and so on) and searching for the objects.
To validate schema objects starting from an alert:
Go to the Database Home page, logging in as user SYSTEM.
In the Alerts section, search for alerts with the following message:
n object(s) are invalid in the schema_name schema.
An example of such a message is the following:
4 object(s) are invalid in the HR schema.
There is a separate message for each schema that contains invalid objects.

In the Message column, click an invalid object message.
The Owner's Invalid Object Count page appears.
Under Related Links, click Invalid Objects Details.
The Invalid Object Details page appears, showing a list of invalid objects.
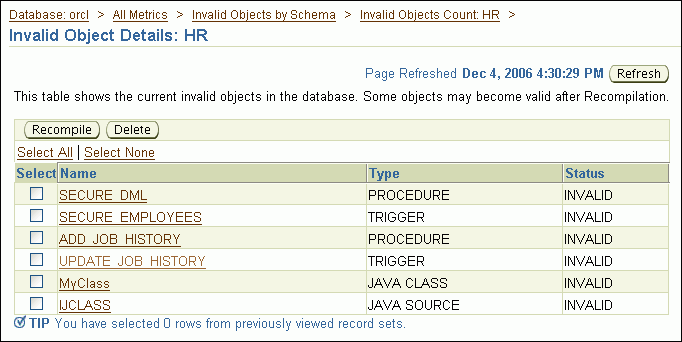
Select one or more objects, and then click Recompile.
A confirmation message appears, and the newly validated objects are removed from the list.
To validate a schema object starting from an object page:
Go to the Database Home page, logging in as user SYSTEM.
At the top of the page, click Schema to view the Schema subpage.
In the Database Objects section, click the link for the object type to validate.
For example, to validate a view, click Views.
On the object page (for example, the Views page), enter a schema name and, optionally, an object name or partial object name, and then click Go.
The schema objects are displayed.
Select the schema object to validate.
In the Actions list, select Compile, and then click Go.
A confirmation message appears.
See Also:
Oracle Database Concepts for more information about schema object dependencies
Oracle Database Administrator's Guide for information about managing object dependencies
You can manage other schema objects with Oracle Enterprise Manager Database Control (Database Control), including the following:
A sequence is a database object that generates unique integers. Each time that you query the sequence, it increments its current value by a designated amount and returns the resulting integer. Sequences can be simultaneously queried by multiple users, and each user receives a unique value. For this reason, using a sequence to provide the value for a primary key in a table is an easy way to guarantee that the key value is unique, regardless of the number of users inserting data into the table.
A synonym is an alias for any schema object, such as a table or view. Synonyms provide an easy way to hide the underlying database structure from an application or a user. Synonyms can be private or public. A public synonym does not have to be qualified with a schema name, whereas a private synonym does, if the user referencing the private synonym is not the synonym owner. For example, consider the following query, issued by a user who has been granted the SELECT object privilege on the hr.employees table:
SELECT employee_id, salary FROM hr.employees ORDER BY salary
Now suppose you create a public synonym named personnel as an alias for the hr.employees table, and you grant the SELECT privilege on the hr.employees table to PUBLIC (all database users). With the public synonym in place, any user can issue the following simpler query:
SELECT employee_id, salary FROM personnel ORDER BY salary
The user who created this query did not need to know the name of the schema that contains the personnel data.
Note:
If a user owns a table namedpersonnel, then that table is used in the query. If no such table exists, then the database resolves the public synonym and uses the hr.employees table.An additional benefit of synonyms is that you can use the same synonym in a development database as in the production database, even if the schema names are different. This technique enables application code to run unmodified in both environments. For example, the preceding query would run without errors in a development database that had the employees table in the dev1 schema, if the personnel synonym is defined in the development database to point to the dev1 schema.
Because a synonym is simply an alias, it requires no storage other than its definition in the data dictionary. To reference a synonym in a query, you must have privileges on the object to which it points. Synonyms themselves cannot be secured. If you grant object privileges on a synonym to a user, then you are granting privileges on the object to which the synonym points.
A database link is a schema object that points to another Oracle database. You use a database link to query or update objects in a remote database. Database links are used in distributed database environments, which are described in Oracle Database Administrator's Guide.
Oracle By Example (OBE) has a series on the Oracle Database 2 Day DBA guide. This OBE steps you through the tasks in this chapter and includes annotated screenshots.
To view the Schemas OBE, in your browser, enter the following URL:
http://www.oracle.com/webfolder/technetwork/tutorials/obe/db/11g/r2/2day_dba/schema/schema.htm
|
Copyright © 2004, 2012, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|