| Oracle® Database VLDB and Partitioning Guide 11g Release 2 (11.2) Part Number E25523-01 |
|
|
PDF · Mobi · ePub |
| Oracle® Database VLDB and Partitioning Guide 11g Release 2 (11.2) Part Number E25523-01 |
|
|
PDF · Mobi · ePub |
This section discusses the types of parallelism in the following topics:
You can use parallel queries and parallel subqueries in SELECT statements and execute in parallel the query portions of DDL statements and DML statements (INSERT, UPDATE, and DELETE). You can also query external tables in parallel.
Parallelization has two components: the decision to parallelize and the degree of parallelism (DOP). These components are determined differently for queries, DDL operations, and DML operations. To determine the DOP, Oracle Database looks at the reference objects:
Parallel query looks at each table and index, in the portion of the query to be executed in parallel, to determine which is the reference table. The basic rule is to pick the table or index with the largest DOP.
For parallel DML (INSERT, UPDATE, MERGE, and DELETE), the reference object that determines the DOP is the table being modified by and insert, update, or delete operation. Parallel DML also adds some limits to the DOP to prevent deadlock. If the parallel DML statement includes a subquery, the subquery's DOP is equivalent to that for the DML operation.
For parallel DDL, the reference object that determines the DOP is the table, index, or partition being created, rebuilt, split, or moved. If the parallel DDL statement includes a subquery, the subquery's DOP is equivalent to the DDL operation.
This section contains the following topics:
For information about the query operations that Oracle Database can execute in parallel, refer to "Operations That Can Use Parallel Execution". For an explanation of how the processes perform parallel queries, refer to "Parallel Execution of SQL Statements". For examples of queries that reference a remote object, refer to "Distributed Transaction Restrictions". For information about the conditions for executing a query in parallel and the factors that determine the DOP, refer to "Rules for Parallelizing Queries".
The following parallel scan methods are supported on index-organized tables:
Parallel fast full scan of a nonpartitioned index-organized table
Parallel fast full scan of a partitioned index-organized table
Parallel index range scan of a partitioned index-organized table
These scan methods can be used for index-organized tables with overflow areas and for index-organized tables that contain LOBs.
Parallel query on a nonpartitioned index-organized table uses parallel fast full scan. The DOP is determined, in decreasing order of priority, by:
A PARALLEL hint (if present)
An ALTER SESSION FORCE PARALLEL QUERY statement
The parallel degree associated with the table, if the parallel degree is specified in the CREATE TABLE or ALTER TABLE statement
Work is allocated by dividing the index segment into a sufficiently large number of block ranges and then assigning the block ranges to parallel execution servers in a demand-driven manner. The overflow blocks corresponding to any row are accessed in a demand-driven manner only by the process, which owns that row.
Both index range scan and fast full scan can be performed in parallel. For parallel fast full scan, parallelization is the same as for nonpartitioned index-organized tables. For a parallel index range scan on a partitioned index-organized table, the DOP is the minimum of the degree obtained from the previous priority list (such as in parallel fast full scan) and the number of partitions in the index-organized table. Depending on the DOP, each parallel execution server gets one or more partitions, each of which contains the primary key index segment and the associated overflow segment, if any.
Parallel queries can be performed on object type tables and tables containing object type columns. Parallel query for object types supports all of the features that are available for sequential queries on object types, including:
Methods on object types
Attribute access of object types
Constructors to create object type instances
Object views
PL/SQL and Oracle Call Interface (OCI) queries for object types
There are no limitations on the size of the object types for parallel queries.
The following restrictions apply to using parallel query for object types:
A MAP function is needed to execute queries in parallel for queries involving joins and sorts (through ORDER BY, GROUP BY, or set operations). Without a MAP function, the query is automatically executed serially.
Parallel DML and parallel DDL are not supported with object types, and such statements are always performed serially.
In all cases where the query cannot execute in parallel because of any of these restrictions, the whole query executes serially without giving an error message.
This section discusses the following rules for executing queries in parallel.
A SELECT statement can be executed in parallel only if the following conditions are satisfied:
The query includes a parallel hint specification (PARALLEL or PARALLEL_INDEX) or the schema objects referred to in the query have a PARALLEL declaration associated with them.
At least one table specified in the query requires one of the following:
A full table scan
An index range scan spanning multiple partitions
No scalar subqueries are in the SELECT list.
The DOP for a query is determined by the following rules:
The query uses the maximum DOP taken from all of the table declarations involved in the query and all of the potential indexes that are candidates to satisfy the query (the reference objects). That is, the table or index that has the greatest DOP determines the query's DOP maximum query directive.
If a table has both a parallel hint specification in the query and a parallel declaration in its table specification, the hint specification takes precedence over parallel declaration specification. See Table 8-2 for precedence rules.
This section discusses the following topics on parallelism for DDL statements:
You can execute DDL statements in parallel for tables and indexes that are nonpartitioned or partitioned. Table 8-2 summarizes the operations that can be executed in parallel in DDL statements.
The parallel DDL statements for nonpartitioned tables and indexes are:
CREATE INDEX
CREATE TABLE ... AS SELECT
ALTER INDEX ... REBUILD
The parallel DDL statements for partitioned tables and indexes are:
CREATE INDEX
CREATE TABLE ... AS SELECT
ALTER TABLE ... [MOVE|SPLIT|COALESCE] PARTITION
ALTER INDEX ... [REBUILD|SPLIT] PARTITION
This statement can be executed in parallel only if the (global) index partition being split is usable.
All of these DDL operations can be performed in NOLOGGING mode for either parallel or serial execution.
The CREATE TABLE statement for an index-organized table can be executed in parallel either with or without an AS SELECT clause.
Different parallelism is used for different operations (see Table 8-2). Parallel CREATE TABLE ... AS SELECT statements on partitioned tables and parallel CREATE INDEX statements on partitioned indexes execute with a DOP equal to the number of partitions.
Parallel DDL cannot occur on tables with object columns. Parallel DDL cannot occur on nonpartitioned tables with LOB columns.
Parallel execution lets you execute the query in parallel and create operations of creating a table as a subquery from another table or set of tables. This can be extremely useful in the creation of summary or rollup tables.
Clustered tables cannot be created and populated in parallel.
Figure 8-4 illustrates creating a summary table from a subquery in parallel.
Figure 8-4 Creating a Summary Table in Parallel
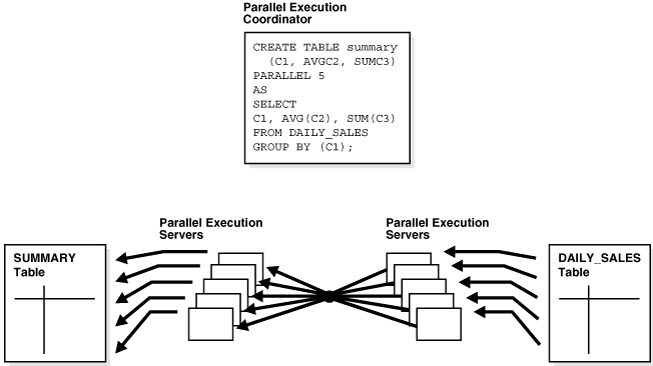
Parallel DDL is often used to create summary tables or do massive data loads that are standalone transactions, which do not always need to be recoverable. By switching off Oracle Database logging, no undo or redo log is generated, so the parallel DML operation is likely to perform better, but becomes an all or nothing operation. In other words, if the operation fails, for whatever reason, you must completely redo the operation, it is not possible to restart it.
If you disable logging during parallel table creation (or any other parallel DDL operation), you should back up the tablespace containing the table after the table is created to avoid loss of the table due to media failure.
Use the NOLOGGING clause of the CREATE TABLE, CREATE INDEX, ALTER TABLE, and ALTER INDEX statements to disable undo and redo log generation.
Creating a table or index in parallel has space management implications that affect both the storage space required during a parallel operation and the free space available after a table or index has been created.
When creating a table or index in parallel, each parallel execution server uses the values in the STORAGE clause of the CREATE statement to create temporary segments to store the rows. Therefore, a table created with a NEXT setting of 4 MB and a PARALLEL DEGREE of 16 consumes at least 64 megabytes (MB) of storage during table creation because each parallel server process starts with an extent of 4 MB. When the parallel execution coordinator combines the segments, some segments may be trimmed, and the resulting table may be smaller than the requested 64 MB.
When you create indexes and tables in parallel, each parallel execution server allocates a new extent and fills the extent with the table or index data. Thus, if you create an index with a DOP of 4, the index has at least four extents initially. This allocation of extents is the same for rebuilding indexes in parallel and for moving, splitting, or rebuilding partitions in parallel.
Serial operations require the schema object to have at least one extent. Parallel creations require that tables or indexes have at least as many extents as there are parallel execution servers creating the schema object.
When you create a table or index in parallel, it is possible to create areas of free space. This occurs when the temporary segments used by the parallel execution servers are larger than what is needed to store the rows.
If the unused space in each temporary segment is larger than the value of the MINIMUM EXTENT parameter set at the tablespace level, then Oracle Database trims the unused space when merging rows from all of the temporary segments into the table or index. The unused space is returned to the system free space and can be allocated for new extents, but it cannot be coalesced into a larger segment because it is not contiguous space (external fragmentation).
If the unused space in each temporary segment is smaller than the value of the MINIMUM EXTENT parameter, then unused space cannot be trimmed when the rows in the temporary segments are merged. This unused space is not returned to the system free space; it becomes part of the table or index (internal fragmentation) and is available only for subsequent insertions or for updates that require additional space.
For example, if you specify a DOP of 3 for a CREATE TABLE ... AS SELECT statement, but there is only one data file in the tablespace, then internal fragmentation may occur, as shown in Figure 8-5. The areas of free space within the internal table extents of a data file cannot be coalesced with other free space and cannot be allocated as extents.
See Oracle Database Performance Tuning Guide for more information about creating tables and indexes in parallel.
Figure 8-5 Unusable Free Space (Internal Fragmentation)
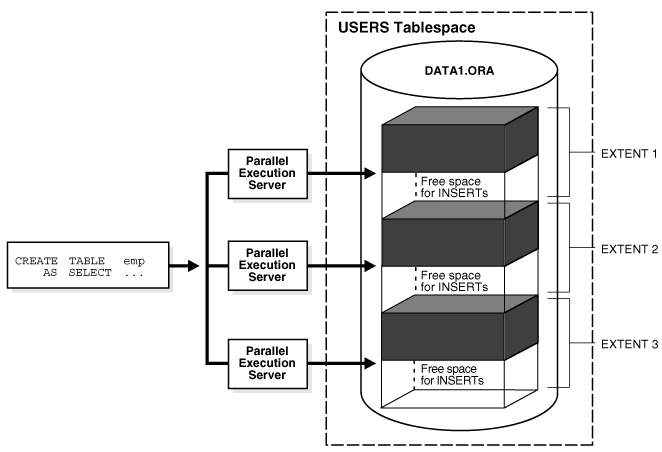
You must consider the following topics when parallelizing DDL statements:
DDL operations can be executed in parallel if a PARALLEL clause (declaration) is specified in the syntax. For CREATE INDEX and ALTER INDEX ... REBUILD or ALTER INDEX ... REBUILD PARTITION, the parallel declaration is stored in the data dictionary.
You can use the ALTER SESSION FORCE PARALLEL DDL statement to override the parallel clauses of subsequent DDL statements in a session.
The DOP is determined by the specification in the PARALLEL clause, unless it is overridden by an ALTER SESSION FORCE PARALLEL DDL statement. A rebuild of a partitioned index is never executed in parallel.
Parallel clauses in CREATE TABLE and ALTER TABLE statements specify table parallelism. If a parallel clause exists in a table definition, it determines the parallelism of DDL statements and queries. If the DDL statement contains explicit parallel hints for a table, however, those hints override the effect of parallel clauses for that table. You can use the ALTER SESSION FORCE PARALLEL DDL statement to override parallel clauses.
The rules for creating and altering indexes are discussed in the following topics:
The CREATE INDEX and ALTER INDEX ... REBUILD statements can be parallelized only by a PARALLEL clause or an ALTER SESSION FORCE PARALLEL DDL statement.
The ALTER INDEX ... REBUILD statement can be parallelized only for a nonpartitioned index, but ALTER INDEX ... REBUILD PARTITION can be parallelized by a PARALLEL clause or an ALTER SESSION FORCE PARALLEL DDL statement.
The scan operation for ALTER INDEX ... REBUILD (nonpartitioned), ALTER INDEX ... REBUILD PARTITION, and CREATE INDEX has the same parallelism as the REBUILD or CREATE operation and uses the same DOP. If the DOP is not specified for REBUILD or CREATE, the default is the number of CPUs.
The ALTER INDEX ... MOVE PARTITION and ALTER INDEX ...SPLIT PARTITION statements can be parallelized only by a PARALLEL clause or an ALTER SESSION FORCE PARALLEL DDL statement. Their scan operations have the same parallelism as the corresponding MOVE or SPLIT operations. If the DOP is not specified, the default is the number of CPUs.
Note:
IfPARALLEL_DEGREE_POLICY is set to AUTO, then statement-level parallelism is ignored.The CREATE TABLE ... AS SELECT statement contains two parts: a CREATE part (DDL) and a SELECT part (query). Oracle Database can parallelize both parts of the statement. The CREATE part follows the same rules as other DDL operations.
This section contains the following topics:
The query part of a CREATE TABLE ... AS SELECT statement can be parallelized only if the following conditions are satisfied:
The query includes a parallel hint specification (PARALLEL or PARALLEL_INDEX) or the CREATE part of the statement has a PARALLEL clause specification or the schema objects referred to in the query have a PARALLEL declaration associated with them.
At least one table specified in the query requires either a full table scan or an index range scan spanning multiple partitions.
The DOP for the query part of a CREATE TABLE ... AS SELECT statement is determined by one of the following rules:
The query part uses the values specified in the PARALLEL clause of the CREATE part.
If the PARALLEL clause is not specified, the default DOP is the number of CPUs.
If the CREATE is serial, then the DOP is determined by the query.
Note that any values specified in a hint for parallelism are ignored.
The CREATE operation of CREATE TABLE ... AS SELECT can be parallelized only by a PARALLEL clause or an ALTER SESSION FORCE PARALLEL DDL statement.
When the CREATE operation of CREATE TABLE ... AS SELECT is parallelized, Oracle Database also parallelizes the scan operation if possible. The scan operation cannot be parallelized if, for example:
The SELECT clause has a NO_PARALLEL hint.
The operation scans an index of a nonpartitioned table.
When the CREATE operation is not parallelized, the SELECT can be parallelized if it has a PARALLEL hint or if the selected table (or partitioned index) has a parallel declaration.
The DOP for the CREATE operation, and for the SELECT operation if it is parallelized, is specified by the PARALLEL clause of the CREATE statement, unless it is overridden by an ALTER SESSION FORCE PARALLEL DDL statement. If the PARALLEL clause does not specify the DOP, the default is the number of CPUs.
Parallel DML (PARALLEL INSERT, UPDATE, DELETE, and MERGE) uses parallel execution mechanisms to speed up or scale up large DML operations against large database tables and indexes.
Note:
Although DML generally includes queries, in this chapter the term DML refers only toINSERT, UPDATE, MERGE, and DELETE operations.This section discusses the following parallel DML topics:
Parallel DML is useful in a decision support system (DSS) environment where the performance and scalability of accessing large objects are important. Parallel DML complements parallel query in providing you with both querying and updating capabilities for your DSS databases.
The overhead of setting up parallelism makes parallel DML operations not feasible for short OLTP transactions. However, parallel DML operations can speed up batch jobs running in an OLTP database.
Several scenarios where parallel DML is used include:
In a data warehouse system, large tables must be refreshed (updated) periodically with new or modified data from the production system. You can do this efficiently by using the MERGE statement.
In a DSS environment, many applications require complex computations that involve constructing and manipulating many large intermediate summary tables. These summary tables are often temporary and frequently do not need to be logged. Parallel DML can speed up the operations against these large intermediate tables. One benefit is that you can put incremental results in the intermediate tables and perform parallel updates.
In addition, the summary tables may contain cumulative or comparative information which has to persist beyond application sessions; thus, temporary tables are not feasible. Parallel DML operations can speed up the changes to these large summary tables.
Many DSS applications score customers periodically based on a set of criteria. The scores are usually stored in large DSS tables. The score information is then used in making a decision, for example, inclusion in a mailing list.
This scoring activity queries and updates a large number of rows in the table. Parallel DML can speed up the operations against these large tables.
Historical tables describe the business transactions of an enterprise over a recent time interval. Periodically, the DBA deletes the set of oldest rows and inserts a set of new rows into the table. Parallel INSERT ... SELECT and parallel DELETE operations can speed up this rollover task.
Dropping a partition can also be used to delete old rows. However, the table has to be partitioned by date and with the appropriate time interval.
Batch jobs executed in an OLTP database during off hours have a fixed time during which the jobs must complete. A good way to ensure timely job completion is to execute their operations in parallel. As the workload increases, more computer resources can be added; the scaleup property of parallel operations ensures that the time constraint can be met.
A DML statement can be parallelized only if you have explicitly enabled parallel DML in the session, as in the following statement:
ALTER SESSION ENABLE PARALLEL DML;
This mode is required because parallel DML and serial DML have different locking, transaction, and disk space requirements and parallel DML is disabled for a session by default.
When parallel DML is disabled, no DML is executed in parallel even if the PARALLEL hint is used.
When parallel DML is enabled in a session, all DML statements in this session are considered for parallel execution. However, even if parallel DML is enabled, the DML operation may still execute serially if there are no parallel hints or no tables with a parallel attribute or if restrictions on parallel operations are violated.
The session's PARALLEL DML mode does not influence the parallelism of SELECT statements, DDL statements, and the query portions of DML statements. Thus, if this mode is not set, the DML operation is not parallelized, but scans or join operations within the DML statement may still be parallelized.
For more information, refer to "Space Considerations for Parallel DML" and "Restrictions on Parallel DML".
You have two ways to specify parallel directives for UPDATE, MERGE, and DELETE operations (if PARALLEL DML mode is enabled):
Use a parallel clause in the definition of the table being updated or deleted (the reference object).
Use an update, merge, or delete parallel hint in the statement.
Parallel hints are placed immediately after the UPDATE, MERGE, or DELETE keywords in UPDATE, MERGE, and DELETE statements. The hint also applies to the underlying scan of the table being changed.
You can use the ALTER SESSION FORCE PARALLEL DML statement to override parallel clauses for subsequent UPDATE, MERGE, and DELETE statements in a session. Parallel hints in UPDATE, MERGE, and DELETE statements override the ALTER SESSION FORCE PARALLEL DML statement.
For possible limitations, see "Limitation on the Degree of Parallelism".
The following rule determines whether the UPDATE, MERGE, or DELETE operation should be executed in parallel:
The UPDATE or DELETE operation is parallelized if and only if at least one of the following is true:
The table being updated or deleted has a PARALLEL specification.
The PARALLEL hint is specified in the DML statement.
An ALTER SESSION FORCE PARALLEL DML statement has been issued previously during the session.
If the statement contains subqueries or updatable views, then they may have their own separate parallel hints or clauses. However, these parallel directives do not affect the decision to parallelize the UPDATE, MERGE, or DELETE operations.
The parallel hint or clause on the tables is used by both the query and the UPDATE, MERGE, DELETE portions to determine parallelism, the decision to parallelize the UPDATE, MERGE, or DELETE portion is independent of the query portion, and vice versa.
The DOP is determined by the same rules as for the queries. Note that, for UPDATE and DELETE operations, only the target table to be modified (the only reference object) is involved. Thus, the UPDATE or DELETE parallel hint specification takes precedence over the parallel declaration specification of the target table. In other words, the precedence order is: MERGE, UPDATE, DELETE hint, then Session, and then Parallel declaration specification of target table. See Table 8-2 for precedence rules.
If the DOP is less than the number of partitions, then the first process to finish work on one partition continues working on another partition, and so on until the work is finished on all partitions. If the DOP is greater than the number of partitions involved in the operation, then the excess parallel execution servers have no work to do.
Example 8-4 illustrates an update operation that might be executed in parallel. If tbl_1 is a partitioned table and its table definition has a parallel clause and if the table has multiple partitions with c1 greater than 100, then the update operation is parallelized even if the scan on the table is serial (such as an index scan).
Example 8-4 Parallelization: Example 1
UPDATE tbl_1 SET c1=c1+1 WHERE c1>100;
Example 8-5 illustrates an update operation with a PARALLEL hint. Both the scan and update operations on tbl_2 are executed in parallel with degree four.
An INSERT ... SELECT statement parallelizes its INSERT and SELECT operations independently, except for the DOP.
You can specify a parallel hint after the INSERT keyword in an INSERT ... SELECT statement. Because the tables being queried are usually different than the table being inserted into, the hint enables you to specify parallel directives specifically for the insert operation.
You have the following ways to specify parallel directives for an INSERT ... SELECT statement (if PARALLEL DML mode is enabled):
SELECT parallel hints specified at the statement
Parallel clauses specified in the definition of tables being selected
INSERT parallel hint specified at the statement
Parallel clause specified in the definition of tables being inserted into
You can use the ALTER SESSION FORCE PARALLEL DML statement to override parallel clauses for subsequent INSERT operations in a session. Parallel hints in insert operations override the ALTER SESSION FORCE PARALLEL DML statement.
The following rule determines whether the INSERT operation should be parallelized in an INSERT ... SELECT statement:
The INSERT operation is executed in parallel if and only if at least one of the following is true:
The PARALLEL hint is specified after the INSERT in the DML statement.
The table being inserted into (the reference object) has a PARALLEL declaration specification.
An ALTER SESSION FORCE PARALLEL DML statement has been issued previously during the session.
The decision to parallelize the INSERT operation is independent of the SELECT operation, and vice versa.
After the decision to parallelize the SELECT or INSERT operation is made, one parallel directive is picked for deciding the DOP of the whole statement, using the following precedence rule Insert hint directive, then Session, then Parallel declaration specification of the inserting table, and then Maximum query directive.
In this context, maximum query directive means that among multiple tables and indexes, the table or index that has the maximum DOP determines the parallelism for the query operation.
In Example 8-6, the chosen parallel directive is applied to both the SELECT and INSERT operations.
To execute a DML operation in parallel, the parallel execution coordinator acquires parallel execution servers, and each parallel execution server executes a portion of the work under its own parallel process transaction.
Note the following conditions:
Each parallel execution server creates a different parallel process transaction.
If you use rollback segments instead of Automatic Undo Management, you may want to reduce contention on the rollback segments by limiting the number of parallel process transactions residing in the same rollback segment. See Oracle Database SQL Language Reference for more information.
The coordinator also has its own coordinator transaction, which can have its own rollback segment. To ensure user-level transactional atomicity, the coordinator uses a two-phase commit protocol to commit the changes performed by the parallel process transactions.
A session that is enabled for parallel DML may put transactions in the session in a special mode: If any DML statement in a transaction modifies a table in parallel, no subsequent serial or parallel query or DML statement can access the same table again in that transaction. The results of parallel modifications cannot be seen during the transaction.
Serial or parallel statements that attempt to access a table that has been modified in parallel within the same transaction are rejected with an error message.
If a PL/SQL procedure or block is executed in a parallel DML-enabled session, then this rule applies to statements in the procedure or block.
If you use rollback segments instead of Automatic Undo Management, there are some restrictions when using parallel DML. See Oracle Database SQL Language Reference for information about restrictions for parallel DML and rollback segments.
The time required to roll back a parallel DML operation is roughly equal to the time it takes to perform the forward operation.
Oracle Database supports parallel rollback after transaction and process failures, and after instance and system failures. Oracle Database can parallelize both the rolling forward stage and the rolling back stage of transaction recovery.
See Oracle Database Backup and Recovery User's Guide for details about parallel rollback.
A user-issued rollback in a transaction failure due to statement error is performed in parallel by the parallel execution coordinator and the parallel execution servers. The rollback takes approximately the same amount of time as the forward transaction.
Recovery from the failure of a parallel execution coordinator or parallel execution server is performed by the PMON process. If a parallel execution server or a parallel execution coordinator fails, PMON rolls back the work from that process and all other processes in the transaction roll back their changes.
Recovery from a system failure requires a new startup. Recovery is performed by the SMON process and any recovery server processes spawned by SMON. Parallel DML statements may be recovered using parallel rollback. If the initialization parameter COMPATIBLE is set to 8.1.3 or greater, Fast-Start On-Demand Rollback enables terminated transactions to be recovered, on demand, one block at a time.
Parallel UPDATE uses the existing free space in the object, while direct-path INSERT gets new extents for the data.
Space usage characteristics may be different in parallel than serial execution because multiple concurrent child transactions modify the object.
The following restrictions apply to parallel DML (including direct-path INSERT):
Intra-partition parallelism for UPDATE, MERGE, and DELETE operations require that the COMPATIBLE initialization parameter be set to 9.2 or greater.
The INSERT VALUES statement is never executed in parallel.
A transaction can contain multiple parallel DML statements that modify different tables, but after a parallel DML statement modifies a table, no subsequent serial or parallel statement (DML or query) can access the same table again in that transaction.
This restriction also exists after a serial direct-path INSERT statement: no subsequent SQL statement (DML or query) can access the modified table during that transaction.
Queries that access the same table are allowed before a parallel DML or direct-path INSERT statement, but not after.
Any serial or parallel statements attempting to access a table that has been modified by a parallel UPDATE, DELETE, or MERGE, or a direct-path INSERT during the same transaction are rejected with an error message.
Parallel DML operations cannot be done on tables with triggers.
Replication functionality is not supported for parallel DML.
Parallel DML cannot occur in the presence of certain constraints: self-referential integrity, delete cascade, and deferred integrity. In addition, for direct-path INSERT, there is no support for any referential integrity.
Parallel DML can be done on tables with object columns provided the object columns are not accessed.
Parallel DML can be done on tables with LOB columns provided the table is partitioned. However, intra-partition parallelism is not supported.
A transaction involved in a parallel DML operation cannot be or become a distributed transaction.
Clustered tables are not supported.
Parallel UPDATE, DELETE, and MERGE operations are not supported for temporary tables.
Violations of these restrictions cause the statement to execute serially without warnings or error messages (except for the restriction on statements accessing the same table in a transaction, which can cause error messages).
You can only update the partitioning key of a partitioned table to a new value if the update does not cause the row to move to a new partition. The update is possible if the table is defined with the row movement clause enabled.
The function restrictions for parallel DML are the same as those for parallel DDL and parallel query. See "About Parallel Execution of Functions" for more information.
This section describes the interactions of integrity constraints and parallel DML statements.
These types of integrity constraints are allowed. They are not a problem for parallel DML because they are enforced on the column and row level, respectively.
Restrictions for referential integrity occur whenever a DML operation on one table could cause a recursive DML operation on another table. These restrictions also apply when, to perform an integrity check, it is necessary to see simultaneously all changes made to the object being modified.
Table 8-1 lists all of the operations that are possible on tables that are involved in referential integrity constraints.
Table 8-1 Referential Integrity Restrictions
| DML Statement | Issued on Parent | Issued on Child | Self-Referential |
|---|---|---|---|
|
|
(Not applicable) |
Not parallelized |
Not parallelized |
|
|
(Not applicable) |
Not parallelized |
Not parallelized |
|
|
Supported |
Supported |
Not parallelized |
|
|
Supported |
Supported |
Not parallelized |
|
|
Not parallelized |
(Not applicable) |
Not parallelized |
Deletion on tables having a foreign key with delete cascade is not parallelized because parallel execution servers attempt to delete rows from multiple partitions (parent and child tables).
DML on tables with self-referential integrity constraints is not parallelized if the referenced keys (primary keys) are involved. For DML on all other columns, parallelism is possible.
A DML operation is not executed in parallel if the affected tables contain enabled triggers that may get invoked as a result of the statement. This implies that DML statements on tables that are being replicated are not parallelized.
Relevant triggers must be disabled to parallelize DML on the table. Note that, if you enable or disable triggers, the dependent shared cursors are invalidated.
A DML operation cannot be executed in parallel if it is in a distributed transaction or if the DML or the query operation is on a remote object.
This section contains several examples of distributed transaction processing.
In Example 8-7, the DML statement queries a remote object. The query operation is executed serially without notification because it references a remote object.
Example 8-7 Distributed Transaction Parallelization
INSERT /*+ APPEND PARALLEL (t3,2) */ INTO t3 SELECT * FROM t4@dblink;
In Example 8-8, the DML operation is applied to a remote object. The DELETE operation is not parallelized because it references a remote object.
In Example 8-9, the DML operation is in a distributed transaction. The DELETE operation is not executed in parallel because it occurs in a distributed transaction (which is started by the SELECT statement).
SQL statements can contain user-defined functions written in PL/SQL, in Java, or as external procedures in C that can appear as part of the SELECT list, SET clause, or WHERE clause. When the SQL statement is parallelized, these functions are executed on a per-row basis by the parallel execution server process. Any PL/SQL package variables or Java static attributes used by the function are entirely private to each individual parallel execution process and are newly initialized when each row is processed, rather than being copied from the original session. Because of this process, not all functions generate correct results if executed in parallel.
User-written table functions can appear in the statement's FROM list. These functions act like source tables in that they produce row output. Table functions are initialized once during the statement at the start of each parallel execution process. All variables are entirely private to the parallel execution process.
This section contains the following topics:
In a SELECT statement or a subquery in a DML or DDL statement, a user-written function may be executed in parallel in any of the following cases:
If it has been declared with the PARALLEL_ENABLE keyword
If it is declared in a package or type and has a PRAGMA RESTRICT_REFERENCES clause that indicates all of WNDS, RNPS, and WNPS
If it is declared with CREATE FUNCTION and the system can analyze the body of the PL/SQL code and determine that the code neither writes to the database nor reads or modifies package variables
Other parts of a query or subquery can sometimes execute in parallel even if a given function execution must remain serial.
Refer to Oracle Database Advanced Application Developer's Guide for information about the PRAGMA RESTRICT_REFERENCES clause and Oracle Database SQL Language Reference for information about the CREATE FUNCTION statement.
In a parallel DML or DDL statement, as in a parallel query, a user-written function may be executed in parallel in any of the following cases:
If it has been declared with the PARALLEL_ENABLE keyword
If it is declared in a package or type and has a PRAGMA RESTRICT_REFERENCES clause that indicates all of RNDS, WNDS, RNPS, and WNPS
If it is declared with the CREATE FUNCTION statement and the system can analyze the body of the PL/SQL code and determine that the code neither reads nor writes to the database or reads or modifies package variables
For a parallel DML statement, any function call that cannot be executed in parallel causes the entire DML statement to be executed serially. For an INSERT ... SELECT or CREATE TABLE ... AS SELECT statement, function calls in the query portion are parallelized according to the parallel query rules described in this section. The query may be parallelized even if the remainder of the statement must execute serially, or vice versa.
In addition to parallel SQL execution, Oracle Database can use parallelism for the following types of operations:
Parallel recovery
Parallel propagation (replication)
Parallel load (external tables and the SQL*Loader utility)
Like parallel SQL, parallel recovery, propagation, and external table loads are performed by a parallel execution coordinator and multiple parallel execution servers. Parallel load using SQL*Loader, however, uses a different mechanism.
The behavior of the parallel execution coordinator and parallel execution servers may differ, depending on what kind of operation they perform (SQL, recovery, or propagation). For example, if all parallel execution servers in the pool are occupied and the maximum number of parallel execution servers has been started:
In parallel SQL and external table loads, the parallel execution coordinator switches to serial processing.
In parallel propagation, the parallel execution coordinator returns an error.
For a given session, the parallel execution coordinator coordinates only one kind of operation. A parallel execution coordinator cannot coordinate, for example, parallel SQL and parallel recovery or propagation at the same time.
See Also:
Oracle Database Utilities for information about parallel load and SQL*Loader
Oracle Database Backup and Recovery User's Guide for information about parallel media recovery
Oracle Database Performance Tuning Guide for information about parallel instance recovery
Oracle Database Advanced Replication for information about parallel propagation
Table 8-2 shows how various types of SQL statements can be executed in parallel and indicates which methods of specifying parallelism take precedence.
The priority (1) specification overrides priority (2) and priority (3).
The priority (2) specification overrides priority (3).
Table 8-2 Parallelization Priority Order: By Clause, Hint, or Underlying Table or Index Declaration
| Parallel Operation | PARALLEL Hint | PARALLEL Clause | ALTER SESSION | Parallel Declaration |
|---|---|---|---|---|
|
Parallel query table scan (partitioned or nonpartitioned table) |
(Priority 1) |
(Priority 2) |
(Priority 3) of table |
|
|
Parallel query index range scan (partitioned index) |
(Priority 1) |
(Priority 2) |
(Priority 2) of index |
|
|
Parallel |
(Priority 1) |
(Priority 3) of table being updated or deleted from |
||
|
|
(Priority 1) |
(Priority 3) of table being inserted into |
||
|
|
Takes degree from |
Takes degree from |
Takes degree from |
Takes degree from |
|
|
(Priority 1) |
(Priority 2) of table being selected from |
||
|
|
Note: Hint in the |
(Priority 2) |
||
|
|
Takes degree from |
Takes degree from |
Takes degree from |
Takes degree from |
|
|
(Priority 1) |
(Priority 2) of querying tables or partitioned indexes |
||
|
Parallel |
(Priority 2) |
|||
|
Parallel |
(Priority 2) |
(Priority 1) |
||
|
|
||||
|
Parallel |
(Priority 2) |
(Priority 1) |
||
|
Parallel |
(Priority 2) |
|
Copyright © 2008, 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|