| Oracle® Warehouse Builder Data Modeling, ETL, and Data Quality Guide 11g Release 2 (11.2) Part Number E10935-05 |
|
|
PDF · Mobi · ePub |
| Oracle® Warehouse Builder Data Modeling, ETL, and Data Quality Guide 11g Release 2 (11.2) Part Number E10935-05 |
|
|
PDF · Mobi · ePub |
This chapter provides details on how to use operators as sources and targets in an Oracle Warehouse Builder mapping.
This chapter contains the following topics:
Oracle source and target operators refer to operators that are bound to Oracle data objects in the workspace. Use these operators in a mapping to load data into or source data from Oracle data objects.
The Property Inspector displays the properties of the selected operator. It contains the following categories of parameters for source and target operators:
Change Data Capture: This category is displayed only for tables and views. It contains the following properties: "Capture Consistency", "Change Data Capture Filter", "Enabled", and "Trigger Based Capture".
Conditional Loading: You can set the following properties: "Target Filter for Update", "Target Filter for Delete", and "Match By Constraint".
Data Chunking: This category is displayed for tables, views, and materialized views. It contains the following properties: Chunk Filter Condition, Chunking Enabled, and Parallel Chunk Filter Condition. For information about these properties, see "Chunking for Table Operators".
Error Table: You can set the "Error Table Name", "Roll up Errors", and "Select Only Errors from this Operator" properties. This section of properties is displayed only for the following mapping operators: Table, View, Materialized View, External Table, and Dimension.
General: Under the General node, you can set "Primary Source", "Target Load Order", and the Loading Type. Depending upon the type of target, you can set different values for the Loading Type as described in "Loading Types for Oracle Target Operators" and "Loading Types for Flat Files".
Keys (read-only): You can view the "Key Name", "Key Type", and "Referenced Keys". If the operator functions as a source, then the key settings are used with the Join operator. If the operator functions as a target, then the key settings are used with the "Match By Constraint" parameter.
File Properties: Under the file properties, you can view the "Bound Name".
Temp Stage Table: This category is displayed for tables, views, materialized views, and external tables.It contains the following properties: Extra DDL Clauses, Is Temp Staging Table, and Temp Stage Table ID. These properties are described in "Creating Temporary Tables While Performing ETL".
The Capture Consistency determines the type of Change Data Capture performed. Select one of the following options:
Consistent Set: Performs consistent set Change Data Capture.
Non Consistent Set: Performs non consistent set Change Data Capture.
None: Does not perform Change Data Capture.
The Change Data Capture Filter property represents the filter used to capture changes for a particular subscriber.
Select the Enabled property to enable the functionality that performs Change Data Capture.
Select the Trigger Based Capture property to indicate changes are captured and propagated using triggers on the source tables.
Oracle Application Embedded Data Warehouse (EDW) users, refer to EDW documentation. All other users can disregard this parameter.
Select a loading type for each target operator using the Loading Type property.
For all Oracle target operators, except for dimensions and cubes, select one of the following options.
CHECK/INSERT: Checks the target for existing rows. If there are no existing rows, then the incoming rows are inserted into the target.
DELETE: The incoming row sets are used to determine which of the rows on the target are to be deleted.
DELETE/INSERT: Deletes all rows in the target and then inserts the new rows.
INSERT: Inserts the incoming row sets into the target. The insert operation fails if a row exists with the same primary or unique key.
INSERT/UPDATE: For each incoming row, the insert operation is performed first. If the insert fails, then an update operation occurs. If there are no matching records for update, then the insert is performed. If you select INSERT/UPDATE and the "Default Operating Mode" is set to Row based, then you must set unique constraints on the target. If the operating mode is set to Set based, then Oracle Warehouse Builder generates a MERGE statement.
NONE: No operation is performed on the target. This setting is useful for testing. Extraction and transformations run but have no effect on the target.
TRUNCATE/INSERT: Truncates the target and then inserts the incoming row set. If you select this option, then the operation cannot be rolled back even if the execution of the mapping fails. Truncate permanently removes the data from the target.
UPDATE: Uses the incoming row sets to update existing rows in the target. If no rows exist for the specified match conditions, then no changes are made.
If you set the configuration parameter PL/SQL Generation Mode of the target module to Oracle 10g, Oracle 10g Release 2, Oracle 11g Release 1, or Oracle 11g Release 2, the target is updated in set-based mode. The generated code includes a MERGE statement without an insert clause. For modules configured to generate Oracle9i and earlier versions of PL/SQL code, the target is updated in row-based mode.
UPDATE/INSERT: If the "Default Operating Mode" is set to Row based, for each incoming row, the update is performed first followed by an insert if no rows are updated. If the "Default Operating Mode" is set to Set based, then a MERGE statement is generated. Set-based mode can only be generated if the PL/SQL Generation Mode parameter of the target module is Oracle 10g or higher.
For dimensions and cubes, the Loading Type property has the following options: Load and Remove. Use Load to load data into the dimension or cube. Use Remove to remove data from the dimension or cube.
Configure SQL*Loader parameters to define SQL*Loader options for your mapping. The values chosen during configuration directly affect the content of the generated SQL*Loader and the run time control files. SQL*Loader provides two methods for loading data:
Conventional Path Load: Runs a SQL INSERT statement to populate tables in Oracle Database.
Direct Path Load: Eliminates much of the Oracle Database overhead by formatting Oracle data blocks and writing the data blocks directly to the database files. Because a direct load does not compete with other users for database resources, it can usually load data at or near disk speed.
Certain considerations such as restrictions, security, and backup implications are inherent to each method of access to database files. For more information, see Oracle Database Utilities.
When designing and implementing a mapping that extracts data from a flat file using SQL*Loader, you can configure different properties affecting the generated SQL*Loader script. Each load operator in a mapping has an operator property called Loading Type. The value contained by this property affects how the SQL*Loader INTO TABLE clause for that load operator is generated. Although SQL*Loader can append, insert, replace, or truncate data, it cannot update any data during its processing.
Table 25-1 lists the INTO TABLE clauses associated with each load type and their affect on data in the existing targets.
Table 25-1 Loading Types and INTO TABLE Relationship
| Loading Types | INTO TABLE Clause | Affect on Target with Existing Data |
|---|---|---|
|
INSERT/UPDATE |
APPEND |
Adds additional data to target |
|
DELETE/INSERT |
REPLACE |
Removes existing data and replaces with new (DELETE trigger fires) |
|
TRUNCATE/INSERT |
TRUNCATE |
Removes existing data and replaces with new (DELETE trigger fires) |
|
CHECK/INSERT |
INSERT |
Assumes target table is empty |
|
NONE |
INSERT |
Assumes target table is empty |
This property enables you to specify the order in which multiple targets within the same mapping are loaded. Oracle Warehouse Builder determines a default load order based on the foreign key relationships. Use this property to overrule the default order.
If the condition evaluates to true, the row is included in the update loading operation.
If the condition evaluates to true, the row is included in the delete loading operation.
When loading target operators with the UPDATE or the DELETE conditions, you can specify matching criteria. You can set matching and loading criteria manually or choose from several built-in options. Use Match By Constraint to indicate whether unique or primary key information on a target overrides the manual matching and loading criteria set on its attributes. When you click the property Match By Constraint, Oracle Warehouse Builder displays a list containing the constraints defined on that operator and the built-in loading options.
If you select All Constraints, all manual attribute load settings are overruled and the data is loaded as if the load and match properties of the target attributes were set as displayed in Table 25-2.
When you select All Constraints, the load setting Load Column when Updating Row is not automatically assumed to be No for key attributes. However, when performing MERGE generation, this is validated and a validation warning is displayed when certain attributes that are used for UPDATE matching are also used for UPDATE loading.
Table 25-2 All Constraints Target Load Settings
| Load Setting | Key Attribute | All Other Attributes |
|---|---|---|
|
Match Column when Updating Row |
YES |
NO |
|
Match Column when Deleting Row |
YES |
NO |
If you select No Constraints, all manual load settings are honored, and the data is loaded accordingly.
If you select a constraint previously defined for the operator, all manual attribute load settings are overruled, and the data is loaded as if the load and match properties of the target were set as displayed in Table 25-3.
When you select a previously defined constraint, the load setting Load Column when Updating Row is not automatically assumed to be No for key attributes. However, when performing MERGE generation, a validation warning is displayed when certain attributes that are used for UPDATE matching are also used for UPDATE loading
If you made changes at the attribute level and you want to default all settings, click Advanced. A list containing the loading options is displayed. Oracle Warehouse Builder defaults the settings based on the constraint type that you select.
For example, to reset the match properties for all key attributes, click Advanced, select No Constraints, and click OK. The manual load settings are overwritten and the data is loaded based on the settings displayed in Table 25-4.
Table 25-4 Default Load Settings for Advanced No Constraints
| Load Setting | All Key Attributes | All Other Attributes |
|---|---|---|
|
Load Column when Inserting Row |
YES |
NO |
|
Load Column when Updating Row |
YES |
YES |
|
Match Column when Updating Row |
NO |
NO |
|
Match Column when Deleting Row |
NO |
NO |
Alternatively, if you click Advanced and select All Constraints, the manual load settings are overwritten and data is loaded based on the settings displayed in Table 25-5.
The name used by the code generator. If an operator is currently bound and synchronized, then this property is read-only. If an operator is not yet bound, then you can edit the bound name within the Mapping Editor before you synchronize it to a workspace object.
Name of the primary, foreign, or unique key.
Local columns that define this key. Each key column is comma-delimited if the operator contains multiple key column.
Type of key, either primary, foreign, or unique.
If the operator contains a foreign key, Referenced Keys displays the primary key or unique key for the referenced object.
The name of the error table that stores the invalid records during a load operation.
Select Yes to roll up records selected from the error table by the error name. Thus all errors generated by a particular input record are rolled up into a single record with the error names concatenated in the error name attribute.
Rows selected from the error table contains only errors created by this operator in this map execution.
For each attribute in a source and target operator, parameters are categorized into the following types:
General: Under the General properties, you can view the "Bound Name" property, the Business name, and Physical name.
Chunking_column: This category is displayed only for attributes in Table, View, and Materialized View operators. It contains one property "Chunking Number Column".
Code Template Metadata Tags: This category contains the following properties: "SCD", "UD1", "UD2", "UD3", "UD4", "UD5", and "UPD".
Data Type Information: The data type properties are applicable to all operators. They include "Data Type", "Precision", "Scale", "Length", and "Fractional Seconds Precision".
Loading Properties: The operators for tables, dimensions, cubes, views, and materialized views have a Loading Properties category. This category contains the following settings: "Load Column When Inserting Row", "Load Column When Updating Row", "Match Column When Updating Row", "Update: Operation", and "Match Column When Deleting Row".
Certain operators contain properties that are specific to that particular operator. These properties are listed under the Operator Specific Properties node and are described in the sections that discuss that operator.
Name used by the code generator to identify this item. By default, it is the same name as the item. This is a read-only setting when the operator is bound.
Data type of the attribute.
The maximum number of digits this attribute has if the data type of this attribute is a number or a float. This is a read-only setting.
The number of digits to the right of the decimal point. This only applies to number attributes.
The maximum length for a CHAR, VARCHAR, or VARCHAR2 attribute.
The number of digits in the fractional part of the datetime field. It can be a number between 0 and 9. This property is used only for TIMESTAMP, TIMESTAMP WITH TIME ZONE, and TIMESTAMP WITH LOCAL TIME ZONE data types.
This setting prevents data from moving to a target even though it is mapped to do so. If you select Yes (default), then the data reaches the mapped target.
This setting prevents the selected attribute data from moving to a target even though it is mapped to do so. If you select Yes (default), then the data reaches the mapped target attribute. If all columns of a unique key are not mapped, then the unique key is not used to construct the match condition. If no columns of a unique key are mapped, then an error is displayed. If a column (not a key column) is not mapped, then it is not used in loading.
This setting updates a data target row only if there is a match between the source attribute and mapped target attribute. If a match is found, then an update occurs on the row. If you set this property to Yes (default), then the attribute is used as a matching attribute. If you use this setting, then all the key columns must be mapped. If there is only one unique key defined on the target entity, then use constraints to override this setting.
You can specify an update operation to be performed when a matching row is located. An update operation is performed on the target attribute using the data of the source attribute. Table 25-6 lists the update operations that you can specify and describes the update operation logic.
| Operation | Example | Result If Source Value = 5 and Target Value = 10 |
|---|---|---|
|
= |
TARGET = SOURCE |
TARGET = 5 |
|
+= |
TARGET = SOURCE + TARGET |
TARGET = 15 (5 + 10) |
|
-= |
TARGET = TARGET - SOURCE |
TARGET = 5 (10 - 5) |
|
=- |
TARGET = SOURCE - TARGET |
TARGET = negative 5 (5 - 10) |
|
*= |
TARGET = SOURCE * TARGET |
TARGET = 50 (5 * 10) |
|
/= |
TARGET = TARGET / SOURCE |
TARGET = 2 (10 / 5) |
|
=/ |
TARGET = SOURCE / TARGET |
TARGET = 0.5 (5 /10) |
|
||= |
TARGET = TARGET || SOURCE |
TARGET = 105 (10 concatenated with 5) |
|
=|| |
TARGET = SOURCE || TARGET |
TARGET = 510 (5 concatenated with 10) |
Deletes a data target row only if there is a match between the source attribute and mapped target attribute. If a match is found, then a delete operation occurs on the row. If you set this property to Yes (default), then the attribute is used as a matching attribute. Constraints can override this setting.
Select Chunking Number column for an attribute to use that attribute as the chunking attribute. This property is applicable only for parallel chunking.
The Constant operator enables you to define constant values. You can place constants anywhere in any PL/SQL or ABAP mapping.
The Constant operator produces a single output group that contains one or more constant attributes. Oracle Warehouse Builder initializes constants at the beginning of the execution of the mapping.
For example, use a Constant operator to load the value of the current system date into a Table operator. In the Expression Builder, select the public transformation SYSDATE from the list of predefined transformations.
For more information about public transformations, see Chapter 4, "Overview of Transforming Data".
To define a Constant operator in a PL/SQL or ABAP mapping:
Drop a Constant operator onto the Mapping Editor canvas.
Right-click the Constant operator and select Open.
The Constant Editor dialog box is displayed.
On the Output tab, create an output attribute by clicking the blank cell in the Attribute column and entering the name of the output attribute.
The default data type assigned is NUMERIC. You can modify the data type and any other parameters associated with it such as length, precision, and so on.
Enter the expression associated with the output attribute.
Use the Expression field for an output attribute to enter the expression. Or, click the Ellipsis button to the right of the Expression field to use the Expression Builder dialog box to define an expression.
The length, precision, and scale properties assigned to the output attribute must match the values returned by the expressions defined in the mapping. For VARCHAR, CHAR, or VARCHAR2 data types, enclose constant string literals within single quotation marks, such as, 'my_string'.
Click OK to close the Constant Editor dialog box.
The Construct Object operator enables you to create SQL object data types (object types and collection types), PL/SQL object types, and cursors in a mapping by using the individual attributes that they comprise.
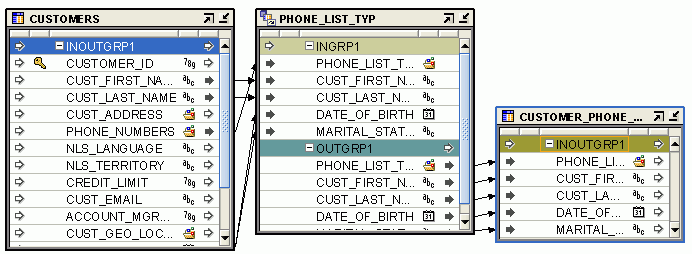
For example, you can use a Construct Object operator to create a SQL object type that is used to load data into a table that contains a column whose data type is an object type. You can also use this operator to create the payload that loads data into an advanced queue. This operator also enables you to construct a SYS.REFCURSOR object.
The Construct Object operator has one input group and one output group. The input group represents the individual attributes that comprise the object type. The output of the Construct Object operator is an object type that is created using the individual attributes. In a mapping, the data type of the output attribute of the Construct Object operator should match the target attribute to which it is being mapped.
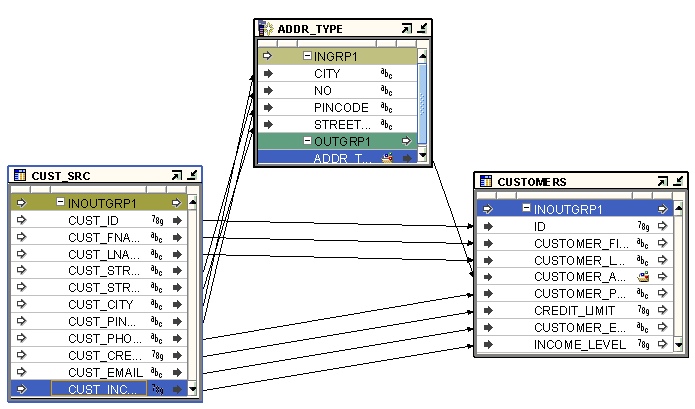
Figure 25-1 displays a mapping that uses a Construct Object operator. The source table CUST_SRC uses separate attributes to store each component of the customer address. But the target table CUSTOMERS uses an object type to store the customer address. To load data from the CUST_SRC table into the CUSTOMERS table, the customer address should be an object type whose signature matches that of the customer address in CUSTOMERS. The Construct Object operator takes the individual attributes from CUST_SRC, that store the customer address as input, and constructs an object type. The Construct Object operator is bound to the user-defined data type CUST_ADDR stored in the workspace.
Figure 25-1 Construct Object Operator in a Mapping
To define a Construct Object operator in a mapping:
Drag and drop a Construct Object operator onto the Mapping Editor canvas.
Use the Add Construct Object dialog box to create or select an object. For more information about these options, see "Using the Add Operator Dialog Box to Add Operators".
Map the individual source attributes that are used to construct the object to the input group of the Construct Object operator.
Map the output attribute of the Construct Object operator to the target attribute. The data type of the target attribute should be an object type.
The signatures of the output attribute of the Construct Object operator and the target attribute should be the same.
Use the Cube operator to source data from or load data into cubes.
The Cube operator contains a group with the same name as the cube. This group contains an attribute for each of the cube measures. It also contains the attributes for the surrogate identifier and business identifier of each dimension level that the cube references. Additionally, the Cube operator displays one group for each dimension that the cube references.
If you specify an Orphan Management Policy and create an error table for a cube, when you add this cube to a mapping, the Cube operator contains a group called ERROR_<cube_name>. This is an output group that contains attributes that are displayed in the Cube operator details, but not in the Cube operator on the mapping canvas. To create data flows using these attributes, display these attributes on the canvas by selecting the ERROR_<cube_name> group on the canvas and from the Graph menu, selecting Select Display Set, and then All.
You can bind a Cube operator to a cube defined in any Oracle module in the current project. You can also synchronize the Cube operator and update it with changes made to the cube to which it is bound. To synchronize a Cube operator, right-click the Cube operator on the Mapping Editor canvas and select Synchronize.
The Cube operator has the following properties that you can use to load a cube.
Loading Type Use the Loading Type property to specify if you are loading data into the cube or removing data from the cube. Set one of the following values for this property.
INSERT_LOAD
All records from the source data set are inserted into the cube. Oracle recommends that you set this option with orphan management.
LOAD
The records from the source data set are merged into the cube. Thus, if a record that is being loaded from the source exists in the cube, this record is updated. Any records in the source data set that do not exist are inserted.
REMOVE
The records in the cube that match the incoming source records are deleted from the cube.
Target Load Order This property determines the order in which multiple targets within the same mapping are loaded. Oracle Warehouse Builder determines a default order based on the foreign key relationships. You can use this property to overrule the default order.
Enable Source Aggregation Set this property to True to aggregate source data before loading the cube. The source data is grouped by all dimension keys.
The default Aggregation function on cube measure attributes is SUM. You can changed the setting Source Aggregation Function property of the cube measure.
If you set the Orphan Management Policy for the cube to Default Dimension Record and you set the Enable Source Aggregation property of the Cube operator to False, execution errors may occur when the cube table is updated. Thus, in this scenario, Oracle Warehouse Builder displays a warning during cube validation.
Solve the Cube Select YES for this property to aggregate the cube data while loading the cube. This increases the load time, but decreases the query time. The data is first loaded and then aggregated.
Incremental Aggregation Select this option to perform incremental loads. If the cube has been solved earlier, subsequent loads only aggregate the new data.
AW Staged Load If you set AW Staged Load to true, the set-based AW load data is staged into a temporary table before loading into the AW.
AW Truncate Before Load Indicates whether all existing cube values should be truncated before loading the cube. Setting this property to YES truncates existing cube data.
You can set the following properties for attributes in a Cube operator.
Update:Operation This property is only applicable to cubes with a ROLAP implementation and to attributes that represent cube measures.
Specifies the type of update operation for cube measures while loading the cube. The options that you can select are +=, -=, /=,=,=-, =||, and ||=. The default values is = and using this value inserts the source fact records into the cube.
For example, if you set this property to +=, the source attribute value that is mapped to the cube measure is added to the existing measure value. If there are multiple source fact records with the same dimensionality, then ensure that you use an Aggregator operator to aggregate these records before loading them into the cube.
Null Data Value Specifies the value that is interpreted as null by the orphan management policy of the cube. While loading cubes, you can use the "Orphan Tab" of the Cube editor to specify how records with null dimension key values and records with invalid dimension key values are treated.
The default value for this property is NULL.
Use a Data Generator operator to introduce a sequence, record number, or system date into a mapping. You can use a single Data Generator operator to map multiple of these functions.
Recommendation:
For PL/SQL mappings, use a "Constant Operator" or Sequence Operator instead of a Data Generator operator.For mappings with flat file sources and targets, the Data Generator operator connects the mapping to SQL*Loader to generate the data stored in the database record.
The following functions are available:
RECNUM
SYSDATE1
SEQUENCE
Oracle Warehouse Builder can generate data by specifying only sequences, record numbers, system dates, and constants as field specifications. SQL*Loader inserts as many records as are specified by the LOAD keyword.
The Data Generator operator has one output group with predefined attributes corresponding to Record Number, System Date, and a typical Sequence. Use the Data Generator operator to obtain record number, system date, or a sequence. For all other functions, use a Constant operator or Expression operator.
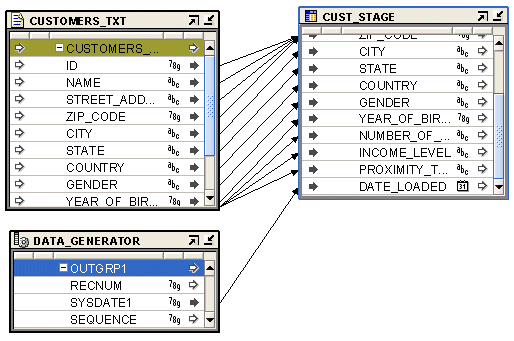
Figure 25-2 shows a mapping that uses the Data Generator operator to obtain the current system date. The data from a flat file CUSTOMERS_TXT is loaded in to a staging table CUST_STAGE. The staging table contains an additional attribute for the date on which the data was loaded. The SYSDATE1 attribute of the Data Generator operator is mapped to the DATE_LOADED attribute of the staging table CUST_STAGE.
To define a Data Generator in a SQL*Loader mapping:
Drop a Data Generator operator onto the Mapping Editor canvas.
Select the SEQUENCE attribute from the Data Generator operator and map it to the target column.
Oracle Warehouse Builder displays the properties of this attribute in the Property Inspector.
In the Expression field, click the Ellipsis button to open the Expression Builder and define an expression.
(Optional) Repeat steps 2 and 3 for the RECNUM attribute.
To set an attribute to the number of the records that the record was loaded from, map from the RECNUM attribute. Records are counted sequentially from the beginning of the first data file, starting with record 1. RECNUM increments as each logical record is assembled. It increments for records that are discarded, skipped, rejected, or loaded. For example, if you use the option SKIP=10, the first record loaded has a RECNUM of 11.
A column mapped from SYSDATE1 gets the current system date, as defined by the SQL SYSDATE function.
The target column must be of type CHAR or DATE. If the column is of type CHAR, then the date is loaded in the format dd-mon-yy. If the system date is loaded into a DATE column, then you can access it in the time format and the date format. A new system date/time is used for each array of records inserted in a conventional path load and for each block of records loaded during a direct path load.
Map the SEQUENCE attribute to the target column to generate sequence numbers for the column. The SEQUENCE keyword ensures a unique value for a column. SEQUENCE increments for each record that is loaded or rejected. It does not increment for records that are discarded or skipped.
The default sequence generated is SEQUENCE (COUNT). You can edit the sequence expression in the property expression, but you must provide the syntax.
The combination of column name and the SEQUENCE function is a complete column specification. Table 25-7 lists the options available for sequence values.
Table 25-7 Sequence Value Options
| Value | Description |
|---|---|
|
COUNT |
The sequence starts with the number of records in the table plus the increment |
|
integer |
Specifies the beginning sequence number |
|
MAX |
The sequence starts with the current maximum value for the column plus the increment. |
|
incr |
The value that the sequence number is to increment after a record is loaded or rejected |
If records are rejected during loading, the sequence of inserts is preserved despite data errors. For example, if four rows are assigned sequence numbers 10, 12, 14, and 16 in a column, and the row with 12 is rejected, the valid rows with assigned numbers 10, 14, and 16, not 10, 12, 14 are inserted. When you correct the rejected data and reinsert it, you can manually set the columns to match the sequence.
Use the Dimension operator to source data from or load data into dimensions and Slowly Changing Dimensions.
The Dimension operator contains one group for each level in the dimension. The groups use the same name as the dimension levels. The level attributes of each level are listed under the group that represents the level.
You cannot map a data flow to the surrogate identifier attribute or the parent surrogate identifier reference attribute of any dimension level. Oracle Warehouse Builder automatically populates these columns when it loads a dimension.
You can bind and synchronize a Dimension operator with a dimension stored in the workspace. To avoid errors in the generated code, ensure that the workspace dimension is deployed successfully before you deploy the mapping that contains the Dimension operator. To synchronize a Dimension operator with the workspace dimension, right-click the dimension on the Mapping Editor canvas and select Synchronize.
If you specify an Orphan Management Policy and create an error table for a dimension, when you add this dimension to a mapping, the Dimension operator contains a group called ERROR_<dimension_name>. This is an output group that contains attributes that are displayed in the dimension operator details, but not in the Dimension operator on the mapping canvas. To create data flows using these attributes, display these attributes on the canvas by selecting the ERROR_<dimension_name> group on the canvas and from the Graph menu, selecting Select Display Set, and then All.
To use a Dimension operator in a mapping:
Drag and drop a Dimension operator onto the Mapping Editor canvas.
Oracle Warehouse Builder displays the Add Dimension dialog box.
Use the Add Dimension dialog box to select a dimension.
Alternatively, you can combine Steps 1 and 2 into one single step. In the Mapping Editor, navigate to the Projects Navigator. Select the dimension and drag and drop it onto the Mapping Editor canvas.
Map the attributes from the Dimension operator to the target, or map attributes from the source to the Dimension operator.
Use the Property Inspector to set options that define additional details about loading or removing data from a dimension or Slowly Changing Dimension.
You can set properties at the following three levels: operator, group that represents each level in the dimension, and level attribute. The following sections describe the Dimension operator properties. The properties are categorized as follows: "AW Properties", "Dimension Properties", "Error Table", "History Logging Properties", and "Orphan Management Policies".
Target Load Order Specifies the order in which multiple targets within the same mapping are loaded. Oracle Warehouse Builder determines a default order based on the foreign key relationships. Use this property to overrule the default order.
AW Name Represents the name of the analytic workspace in which the dimension data is stored.
Aw Staged Load This property is applicable to MOLAP dimensions only. Select this option to stage the set-based load data into a temporary table before loading into the analytic workspace.
Each group in the Dimension operator represents a dimension level. You can set the following properties for each dimension level:
Extracting Type: Represents the extraction operation to be performed when the dimension is used as a source. Select Extract Current Only (Type 2 Only) to extract current records only from a Type 2 SCD. This property is valid only for Type 2 SCDs. Select Extract All to extract all records from the dimension or SCD.
Default Expiration Time of Open Record: This property is applicable to Type 2 SCDs only. It represents a date value that is used as the expiration time of a newly created open record. The default value is NULL.
Note:
If you set the Commit Control property to Manual, ensure that you set the Automatic Hints Enable property to false. Otherwise, your mapping may not run correctly.Aw Truncate Before Load This property is applicable to MOLAP dimensions only. It indicates whether all existing dimension data should be truncated before loading fresh data. Set this property to YES to truncate any existing dimension data before you load fresh data.
Loading Type Represents the type of operation to be performed on the dimension. The options that you can select are as follows:
LOAD: Select this value to load data into the dimension or Slowly Changing Dimension.
REMOVE: Select this value to delete data from the dimension or Slowly Changing Dimension.
While you are loading or removing data, a lookup is performed to determine if the source record exists in the dimension. The matching is performed by the natural key identifier. If the record exists, then a REMOVE operation removes existing data. A LOAD operation updates existing data and then loads new data.
When you remove a parent record, the child records have references to a nonexistent parent.
Type 2 Extract/Remove Current Only This property is applicable only to Type 2 SCDs. Use this property to specify which records are to be extracted or removed. You can set the following values for this property:
YES: When you are extracting data from the Type 2 SCD, only the current record that matches the business identifier in the source data is extracted. When you are removing data from a Type 2 SCD, only the current record that matches the business identifier in the source data is closed (expiration date is set either to SYSDATE or to the date defined in the "Default Expiration Time of Open Record" property).
In a Type 2 SCD that uses a snowflake implementation, you cannot remove a record if it has child records.
NO: When you are extracting data from a Type 2 SCD, all the records, including historical records, that match the business identifier from the source data are extracted from the dimension.
When you are removing data from the Type 2 SCD, all records, including historical records, that match the business identifier in the source data set are deleted.
DML Error Table Name Represents the name of the table that stores DML errors associated with the dimension. To log DML errors, you must enable DML error logging for the dimension. For more information about DML error logging, see "Using DML Error Logging".
Error Table Name Represents the name of the error table that stores logical errors caused by enforcing data profiling and orphan management. If you specify a value for the Error Table Name property of a dimension, then the Error Table Name property of the Dimension operator associated with this dimension displays the same name and you cannot edit the name. Else, specify the name if the error table.
Truncate Error Table(s) This property is applicable to error tables only and not to DML error tables. Set this property to Yes to truncate error tables very time they are used.
Default Effective Time of Initial Record This property is applicable to Type 2 SCDs only. It represents the default value assigned as the effective time for the initial load of a particular dimension record. The default value set for this property is SYSDATE.
Default Effective Time of Open Record This property is applicable to Type 2 SCDs only. It represents the default value set for the effective time of the open records, after the initial record. The default value of this property is SYSDATE. This value should not be modified.
Default Expiration Time of Open Record This property is applicable to Type 2 SCDs only. It represents a date value that is used as the expiration time of a newly created open record for all the levels in the dimension. The default value is NULL.
Support Multiple History Loading This property is applicable only to Type 2 SCDs. Select this option to load multiple rows for a particular business identifier during a single load operation. Then you select this option, the mapping is run in row-based non-bulk mode.
To load multiple records for a particular business identifier, ensure that the effective date of the Type 2 levels are loaded from a source or transformation operator.
Typically, this situation would arise when your dimension records change multiple times within during the period between two dimension updates. For example, you update your dimension only once per day, but there are multiple changes to a dimension record within that day.
Support Out of Order History Loading This property is applicable only to Type 2 SCDs. Setting this property to true enables you to load out-of-order changes to historical records in consecutive data loads.
You can also use this property with "Support Multiple History Loading". However, using this property has a performance overhead.
Type 2 Gap This property is applicable to Type 2 SCDs only. It represents the time interval between the expiration time of an old record and the effective time of the current record when a record is versioned.
When the value of a triggering attribute is updated, the current record is closed and a new record is created with the updated values. Because the closing of the old record and opening of the current record occur simultaneously, it is useful to have a time interval between the expiration time of the old record and the effective time of the open record, instead of using the same value for both.
Type 2 Gap Units This property is applicable for Type 2 SCDs only. It represents the unit of time used to measure the gap interval represented in the Type2 Gap property. The options are: Seconds, Minutes, Hours, Days, and Weeks. The default value is Seconds.
Create Default Level Records Indicates if default level records should be created for the dimension to which the Dimension operator is bound. Set this property to Yes to create default rows for the business identifier and surrogate identifier of the dimension.
The values used by the default record depend on the orphan management policy that you selected for the dimension to which the Dimension operator is bound. If you specified No Maintenance as the orphan management policy of the dimension, then use the Default Value property of the attributes in each level of Dimension operator to specify the values that the default record should use. If you set the orphan management policy of the dimension to Default Parent and specified the attribute values to be used for the default record, then these values are automatically displayed in the Default Value property of the attributes and these values are used for the default records. If you do not specify default values for the attributes in the dimension levels, then the default records are created using NULL values.
You can use this property to generate default records for time dimensions too. Time dimensions do not have an Orphan tab where you can use to set the orphan management policy. But, must use a time dimension with a cube that has its orphan management policy set to a value other than No Maintenance, you can generate default records for the time dimension by setting the Default Value property of the level attributes and then setting the Create Default Level Records property of the time dimension to Yes.
LOAD Policy for Invalid Keys Represents the orphan management policy to be used to load records that contain an invalid parent record. The options are No Maintenance, Default Parent, and Reject Orphan.
LOAD Policy for NULL Keys Represents the orphan management policy to be used to load records that contain a NULL parent key reference. The options are No Maintenance, Default Parent, and Reject Orphan.
Record Error Rows Select Yes to store orphan records contained in the source data set that is used to load the dimension in the error table. The error table is represented by the "Error Table Name" property.
The Expand Object operator enables you to expand an object type and obtain the individual attributes that comprise the object type.
You can bind and synchronize an Expand Object operator with a workspace object type. To avoid generation errors in the mapping, ensure that you deploy the workspace object type before you deploy the mapping.
The Expand Object operator has one input group and one output group. The input group represents the object type to expand to obtain its individual attributes. When you bind an Expand Object operator to a workspace object, the output group of the operator contains the individual attributes that comprise the object type.
To successfully deploy a mapping that contains an Expand Object operator, ensure that the following conditions are satisfied.
The schema that contains the source tables must be on the same instance as the warehouse schema.
The warehouse schema is granted the SELECT privilege on the source tables.
The warehouse schema is granted the EXECUTE privilege on all the object types and nested tables used in the Expand Object operator.
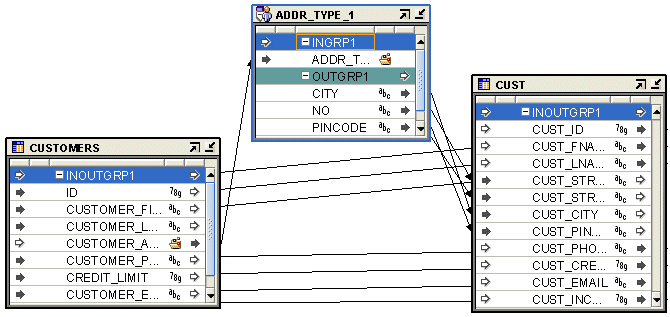
Figure 25-3 displays a mapping that uses an Expand Object operator. The source table CUSTOMERS contains a column CUSTOMER_ADDRESS of data type ADDR_TYPE, a SQL object type. But the target table CUST contains four different columns, of Oracle built-in data types, that store each component of the customer address. To obtain the individual attributes of the column CUSTOMER_ADDRESS, create an Expand Object operator that is bound to the object type ADDR_TYPE. You then map the CUSTOMER_ADDRESS column to the input group of an Expand Object operator. The output group of the Expand Object operator contains the individual attributes of the column CUSTOMER_ADDRESS. Map these output attributes to the target operator.
To define an Expand Object operator in a mapping:
Drag and drop an Expand Object operator onto the Mapping Editor canvas.
Use the Add Expand Object dialog box to create or select an object. For more information about these options, see "Using the Add Operator Dialog Box to Add Operators".
Map the source attribute that is expanded to the input group of the Expand Object operator.
The signature of the input object type should be same as that of the Expand Object operator.
Map the output attributes of the Expand Object operator to the target attributes.
The External Table operator enables you to source data stored in external tables in the workspace. You can then load the external table data into another workspace object or perform transformations on the data. For example, you can source data stored in an external table, transform the data using mapping operators, and then load the data into a dimension or a cube.
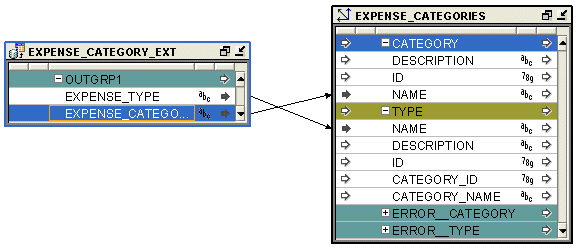
Figure 25-4 displays a mapping that uses the External Table operator. The External Table operator EXPENSE_CATEGORY_EXT is bound to the external table of the same name in the workspace. The data stored in this external table is used to load the dimension EXPENSE_CATEGORIES.
Figure 25-4 External Table Operator in a Mapping
To create a mapping that contains an External Table operator:
Drag and drop an External Table operator onto the Mapping Editor canvas.
Oracle Warehouse Builder displays the Add External Table dialog box.
Use the Add External Table dialog box to create or select an external table. For more information about these options, see "Using the Add Operator Dialog Box to Add Operators".
Map the attributes from the output group of the External Table operator to the target operator or the intermediate transformation operator.
You can introduce information external to Oracle Warehouse Builder as input into a mapping using a Mapping Input Parameter.
For example, you can use a Mapping Input Parameter operator to pass SYSDATE to a mapping that loads data to a staging area. Use the same Mapping Input Parameter operator to pass the timestamp to another mapping that loads the data to a target.
When you generate a mapping, a PL/SQL package is created. Mapping input parameters become part of the signature of the main procedure in the package.
The Mapping Input Parameter operator has a cardinality of one. It creates a single row set that can be combined with another row set as input to the next operator.
Each Mapping Input Parameter operator becomes an output attribute in the Mapping Input Parameter operator. These output attributes can then be used by connecting them to other operators within the Mapping Editor.
When you define the Mapping Input Parameter operator, you specify a data type and an optional default value.
To define a Mapping Input Parameter operator in a mapping:
Drag and drop a Mapping Input Parameter operator onto the Mapping Editor canvas.
Right-click the Mapping Input Parameter operator and select Open Details.
The Mapping Input Parameter Editor is displayed.
Select the Output Attributes link on the left, to display the Output Attributes tab.
To add an output attribute, click a blank field in the Attribute column and provide a name for the output attribute. Also specify details such as data type, length, precision, scale, and seconds description for the attribute, as applicable.
You can rename the attributes and define the data type and other attribute properties.
Click OK to close the Mapping Input Parameter Editor.
Connect the output attribute of the Mapping Input Parameter operator to an attribute in the target operator.
Figure 25-5 displays the mapping that uses a Mapping Input Parameter operator.
Figure 25-5 Mapping Editor Showing A Mapping Input Parameter
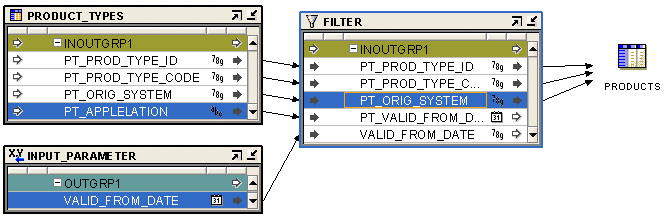
Use a single Mapping Output Parameter operator to send values out of a PL/SQL mapping to applications external to Oracle Warehouse Builder.
A Mapping Output Parameter operator is not valid for a SQL*Loader mapping. When you generate a mapping, a PL/SQL package is created. Mapping Output Parameters become part of the signature of the main procedure in the package.
The Mapping Output Parameter operator has only one input group and no output groups. You can have only one Mapping Output Parameter operator in a mapping. Only attributes that are not associated with a row set can be mapped into a Mapping Output Parameter operator. For example, constant, input parameter, output from a premapping process, or output from a post process can all contain attributes that are not associated with a row set.
To define a Mapping Output Parameter operator in a mapping:
Drag and drop a Mapping Output Parameter operator onto the Mapping Editor canvas.
Right-click the Mapping Output Parameter operator and select Open Details.
The Mapping Output Parameter Editor is displayed.
Click the Input Attributes tab link on the left to display the Input Attributes page.
To add an input attribute, click a blank field in the Attribute column and provide a name for the input attribute. Also specify details such as data type, length, precision, scale, and seconds description for the attribute, as applicable.
You can rename the attributes and define the data type and other attribute properties.
Click OK to close the Mapping Output Parameter editor.
Connect the input attribute of the Mapping Output Parameter operator to an attribute in the target operator.
Figure 25-6 displays an example of a Mapping Output Parameter operator used in a mapping.
Figure 25-6 Mapping Editor Showing An Output Parameter Operator
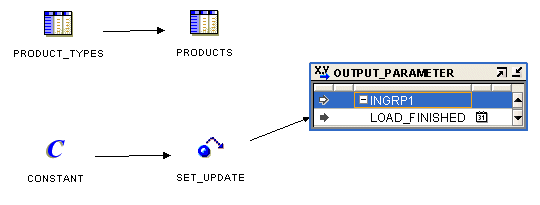
The Materialized View operator enables you to source data from or load data into a materialized view stored in the workspace.
For example, you can use the data stored in a materialized view to load a cube. The Materialized View operator has one I/O group called INOUTGRP1. You cannot add additional groups to this operator, but you can add attributes to the existing I/O group.
You can bind and synchronize a Materialized View operator to a workspace materialized view. The workspace materialized view must be deployed before the mapping that contains the Materialized View operator is generated to avoid errors in the generated code package.
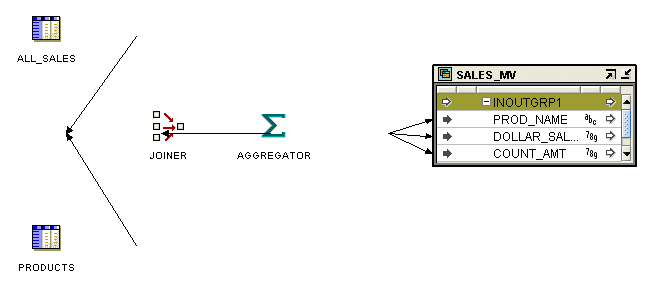
Figure 25-7 displays a mapping that uses a Materialized View operator. The data from the two source tables PRODUCTS and ALL_SALES is joined using a Joiner operator. This data is then aggregated using an Aggregator operator. The aggregated data is used to load the materialized view SALES_MV.
Figure 25-7 Mapping that Contains a Materialized View Operator
To create a mapping that contains a Materialized View operator:
Drag and drop a Materialized View operator onto the Mapping Editor canvas.
Oracle Warehouse Builder displays the Add Materialized View dialog box.
Use the Add Materialized View dialog box to create or select a materialized view. For more information about these options, see "Using the Add Operator Dialog Box to Add Operators".
Map the attributes of the Materialized View operator.
If you are using the Materialized View operator as a target, connect the source attributes to the Materialized View operator attributes. If you are using the materialized view as a source, then connect the Materialized View operator attributes to the target.
A Queue operator enables you to use advanced queues as sources or targets in mappings.
Some of the most critical tasks in creating and maintaining a data warehouse include refreshing existing data, and adding new data from the operational databases. Use the Queue operator to capture changes made to source objects and send those changes to a staging database or directly to a data warehouse or operational data store.
Note:
You cannot use a Queue operator as a source and target in the same mapping.You have the following options for using a Queue operator:
Define a new Queue operator: Drag a Queue operator from the Palette onto the mapping. The Mapping Editor displays a wizard.
Edit an existing Queue operator: Right-click the Queue operator and select Open Details.
For an example of using a Queue operator, see "LCR Cast Operator".
Whether you are using the operator wizard or the Operator Editor, complete the following tasks:
The tasks that you must perform depend on the payload type of the advanced queue to which the Queue operator is bound. For all payload types, except SYS.ANYDATA, you must select the queue to which the Queue operator should be bound. For a payload type of SYS.ANYDATA, you must complete all the tasks listed.
Use the Select Queue page of the Queue Operator Wizard or the Select page of the Queue Operator Editor to select the advanced queue to which the operator is bound.
The node tree on this page lists the advanced queues in the current project. Select the advanced queue to which your Queue operator should be bound.
Use the Select Source Type page to specify if the queue is used as a real-time queue or a batch queue. Also specify the type of messages that the queue receives.
Select one of the following options to indicate the type of queue:
Real-Time Source
Select this option to indicate that the Queue operator represents a real-time source. Real-time queues enable you to populate source changes to the target objects instantly. All DML changes to the source objects associated with the Queue operator, as specified in "Selecting the Source Object", are instantly added to the AQ.
Mappings that contain real-time sources are called real-time mappings. You must deploy real-time mappings. Subsequently, whenever source changes are added to the queue, Oracle Warehouse Builder automatically runs the mapping and publishes the changes to the target objects.
Batch Source
Select this option to indicate that the Queue operator represents a batch source. Batch mappings populate the target objects with changes from the source only when you explicitly run the mapping.
When you define a batch source, you do not provide any more details in the wizard or editor for a batch source. All the wizard or editor pages related to the other tasks for defining the Queue operator are disabled.
For real-time queues that use a SYS.ANYDATA payload, you must specify the format of the messages in the queue. Select one of the following options to specify the message format:
Oracle Capture Process Message Format
Specifies that the messages received are in the form of LCRs. Oracle Warehouse Builder takes care of capturing DML changes, formatting the changes into LCRs and adding the LCRs to the queue.
For more information about LCRs, see Oracle Streams Concepts and Administration.
When you choose this option, you must specify the source table and the DML operations that must be captured as described in "Selecting the Source Object" and "Specifying the Source Changes to Process".
User-Defined Message Format
Specifies that the messages received by the queue are in a user-defined format. When you choose this option, specify the user-defined type that represents the message format using the Select User-Defined or Primary Type page as described in "Selecting the User-Defined or Primary Type for a Queue Operator".
When your queue uses a user-defined message format, you must specify the user-defined type that represents the message format. Use the User-Defined or Primary Type page to select the user-defined type.
This page contains a node tree that you can to select the user-defined type. The Primary Data Types node lists the primary data types you can select. If your message format uses primary data types, then expand this node and select a primary data type. A separate node is displayed for each Oracle module that contains user-defined types. Expand the required module node and select the user-defined type they represents the queue message format.
Use the Select Source page to specify the source tables for which you want to capture data changes. This page is enabled only if your queue is a real-time source that uses the Oracle capture message format.
The Available Tables section lists the tables for which can capture data changes. Select the tables and use the arrows to move them to the Selected Tables section. You can choose multiple tables by holding down the Ctrl key and selecting the tables.
Use the Source Changes to Process page to specify the DML changes that should be captured for the tables selected on the Select Source page. This page is enabled only if your queue is a real-time source that uses an Oracle Capture Message Format.
The Identify Changes to Process section lists the tables selected on the Select Objects page. For each tables, use the check boxes to the right of the table name to select the DML operations that should be captured. Select Insert for a table to capture any rows inserted in the table. To capture any modifications made to a table, select Update to the right of the table. To capture rows deleted from a table, select Delete to the right of the table name.
A Sequence operator generates sequential numbers that increment for each row.
For example, you can use the Sequence operator to create surrogate keys while loading data into a dimension table. You can connect a Sequence to a target operator input or to the inputs of other types of operators. You can combine the sequence outputs with outputs from other operators.
Because sequence numbers are generated independently of tables, the same sequence can be used for multiple tables. Sequence numbers may not be consecutive, because the same sequence can be used by multiple sessions.
This operator contains an output group containing the following output attributes:
CURRVAL: Generates from the current value
NEXTVAL: Generates a row set of consecutively incremented numbers beginning with the next value
You can bind and synchronize Sequences to a workspace sequence in one of the modules. The workspace sequence must be generated and deployed before the mapping containing the Sequence is deployed to avoid errors in the generated code package. See "Using the Add Operator Dialog Box to Add Operators" for more information.
Generate mappings with sequences using row-based mode. Sequences may be incremented even if rows are not selected. If you want a sequence to start from the last number, then do not run your SQL package in set-based or in set-based with failover operating modes. See "Runtime Parameters" for more information about configuring mode settings.
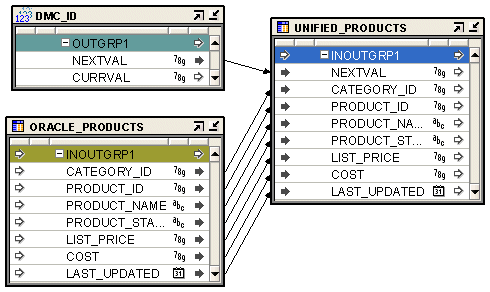
Figure 25-8 shows a mapping that uses a Sequence operator to automatically generate the primary key of a table. The NEXTVAL attribute of the Sequence operator is mapped to an input attribute of the target table UNIFIED_PRODUCTS. The other input attributes from the source table, ORACLE_PRODUCTS, are mapped directly to the target.
Figure 25-8 Sequence Operator in a Mapping
To define a Sequence operator in a mapping:
Drag and drop the Sequence operator onto the Mapping Editor canvas.
Oracle Warehouse Builder displays the Add Sequence dialog box.
Use the Add Sequence dialog box to create or select a sequence. For more information about these options, see "Using the Add Operator Dialog Box to Add Operators".
Connect the required output attribute from the Sequence operator to a target attribute.
The Table operator enables you to source data from and load data into tables stored in the workspace.
You can bind and synchronize a Table operator to a workspace table. To avoid errors in the generated code package, the workspace table must be deployed before the mapping that contains the Table operator is generated.
Figure 25-8 displays a mapping that uses Table operators as both source and target. Figure 25-2 displays a mapping that uses the Table operator as a target.
To define a Table operator in a mapping:
Drag and drop a Table operator onto the Mapping Editor canvas.
Oracle Warehouse Builder displays the Add Table dialog box.
Use the Add Table dialog box to create or select a table. For more information about these options, see "Using the Add Operator Dialog Box to Add Operators".
Map the attributes of the Table operator.
If you are using the table as a target, connect the source attributes to the Table operator attributes. If you are using the table as a source, then connect the Table operator attributes to the target.
You can enable the Merge Optimization property for Table operators. When set to True, this property optimizes the invocation or execution of expressions and transformations in the MERGE statement.
For example, consider a mapping in which the target table contains a column that is part of the update operation only and is mapped to a transformation. In previous releases, Oracle Warehouse Builder would run the transformation for all rows, including rows that did not require transformation. Beginning in this release, if Merge Optimization is enabled, then Oracle Warehouse Builder calls the transformation only in the update part of the MERGE statement.
Chunking enables you to divide the source data in a mapping into chunks. The chunks are defined by a data partitioning algorithm and each chunk is then processed and loaded into the targets separately.
For more information about chunking, see "About Chunking for PL/SQL Mappings".
To use source data chunking for a Table operator, select the Table operator on the mapping canvas. The Property Inspector displays the properties of the Table operator.
You can perform both serial or parallel chunking. To perform serial chunking, set the "Chunking Enabled" and "Chunk Filter Condition" options under the SCD Updates node. To perform parallel chunking, set the "Chunking Expression" option under the Chunking node.
Select this option to enable serial data chunking for the source table represented by the Table operator.
You can enable data chunking for only certain source tables in a mapping. For example, if your mapping contains three Table operators and you enable data chunking for only one Table operator, the entire mapping functionality is run multiple times, once for each data chunk. However, since the other two tables do not have chunking enabled, these sources provide data rows only during the first iteration of the mapping.
The Chunk Filter Condition enables you to specify the condition used to divide source data into multiple chunks while performing serial chunking. For each iteration, the Chunk Filter Condition filters the source data from the source.
Oracle Warehouse Builder provides a predefined mapping constant, get_chunk_iterator, that must be used in all chunk filter conditions. This is an iteration count that starts at 1 and is incremented for each map execution in the chunk processing. You can set the condition to use a value from the data source.
For example, your filter condition can be get_chunk_iterator = INOUTGRP1.CHUNK_GRP_NUM, where CHUNK_GRP_NUM is an attribute in the source table.
Use Chunking Expression to set the condition used to divide source data into multiple chunks for parallel chunking.
Oracle Warehouse Builder enables you to use temporary tables while extracting and loading data. Temporary tables are useful when you must extract data from remote sources into multiple targets.
Temporary staging tables are typically used in the dimension loading logic that is automatically generated by the Dimension operator submapping expansion. This prevents problems that would be caused by doing lookups on the target table.
The following properties enable you to create temporary tables while performing ETL.
When you set the Is Temp Stage Table property to True, any existing bindings for the Table operator are ignored. A temporary staging table is deployed with the mapping and all loading and extracting operations from this Table operator are performed from the staging table.
The name of the deployed table in the database is based on the operator name, with a unique identifier appended to the name to prevent name conflicts. The table is automatically dropped when the map is dropped or redeployed. Before each execution of the mapping, the table is automatically truncated.
When you set this property to its default value of False, it has no effect.
Use this property to add additional clauses to the DDL statement that is used to create the table. For example, use the following TABLESPACE clause to allocate storage for the temporary table in the MY_TBLSPC tablespace, instead of in the default tablespace: TABLESPACE MY_TBLSPC.
If you do not provide a value for the Extra DDL Clauses property, this property has no effect on the table creation.
Use the Temp Stage Table ID property to specify the internal identifier used for the temporary staging table by the code generator. If any other temporary staging table in the mapping has the same value for the Temp Stage Table ID property, then the same deployed temporary staging table is bound to both operators. It enables multiple usages of the same temporary staging table in the same mapping.
You can perform DML error logging on target tables. Use the property DML Error Table Name of the Table operator to specify the name of the error table that stores errors encountered while performing DML operations on that table. The error table is created when you run the mapping containing the Table operator.
For more information about DML error logging, see "Using DML Error Logging".
In addition to logging DML errors, you can also store logical errors such as data profiling and orphan management errors. Use the Error Table Name property for the Table operator to specify the name of the table that stores logical errors for the repository table associated with the Table operator. If you have specified a name for the Error Table Name property of the table, then the Error Table Name property of the Table operator associated with this table automatically uses the same name.
When you have an object of type nested table or Varray, you can use the Varray Iterator operator to iterate through the values in the table type.
This operator accepts a table type attribute as the source, and generates a value that is of the base element type defined in the nested table or Varray type. If the operator is bound, then reconciliation operations are performed on the operator. Reconciliation operations are not supported for unbound Varray Iterator operators.
You can create the Varray Iterator operator as either a bound operator or an unbound operator. You cannot synchronize or validate an unbound Varray Iterator operator. It has only one input group and one output group. You can have an input group with attributes of other data types. However, there must be at least one table type attribute.
The attributes of the output group are a copy of the attributes of the input group. The only difference is that instead of the table type to which the operator is bound (which is one of the input group attributes), the output group has an attribute that equals the base element type of the input group. The input group is editable. The output group is not editable.
Figure 25-9 displays a mapping that contains a Varray Iterator operator.
Figure 25-9 Varray Iterator Operator in a Mapping
To define a Varray Iterator operator in a mapping:
Drag and drop a Varray Iterator operator onto the Mapping Editor canvas.
Oracle Warehouse Builder displays the Add Varray Iterator dialog box.
From the Add Varray Iterator dialog box, select either an unbound operator or a bound operator.
If you select the unbound operator, then a Varray Iterator operator with no attributes is created. You must create these attributes manually.
If you select the bound operator, then you must select one of the available nested table or Varray types shown in the tree. The output attribute equals the base element.
Click OK.
Map the attributes of the Varray Iterator operator.
For an unbound operator, right-click the unbound Varray Iterator operator on the Mapping Editor canvas and then select Open Details. This opens the Varray Iterator editor dialog box. You can add attributes to the input group by using the Add button. You can only change the data type of the attributes in the output group.
The View operator enables you to source data from or load data into a view stored in the workspace.
You can bind and synchronize a View operator to a workspace view. The workspace view must be deployed before the mapping that contains the View operator is generated to avoid errors in the generated code package.
To define a View operator in a mapping:
Drag and drop a View operator onto the Mapping Editor canvas.
Oracle Warehouse Builder displays the Add View dialog box.
Use the Add View dialog box to create or select a view. For more information about these options, see "Using the Add Operator Dialog Box to Add Operators".
Map the attributes of the View operator.
If you are using the view as a target, connect the source attributes to the View operator attributes. If you are using the view as a source, then connect the View operator attributes to the target.
You can use the View operator to create inline views in a mapping. For inline views, you must set the following operator properties.
Inlined: Select this property to indicate that the operator represents an inline view.
View Query: Use this property to specify the query text for the inline view. The query text must have column aliases that correspond to the operator attribute names.
You can bind a target operator in a mapping to an object in a remote Oracle Database location or a non-Oracle Database location such as SQL Server or DB2 through a Gateway location. Such operators are referred to as Gateway targets. Use database links to access these targets. The database links are created using the locations. SAP targets are not supported, because it is not possible to generate a database link to access SAP tables remotely from an Oracle database.
There are certain restrictions on using remote or Gateway targets in a mapping, as described in the following sections:
The following limitations apply when you use a remote or Gateway target in a mapping:
You cannot set the Loading Type property of the target operator to TRUNCATE/INSERT.
This results in a validation error when you validate the mapping.
For Gateway targets, setting the Loading Type property of the target operator to INSERT/UPDATE produces the same result as setting the loading type to INSERT.
The RETURNING clause is not supported in a DML statement.
The RETURNING clause enables you to obtain the ROWIDs of the rows that are loaded into the target using row-based mode. These ROWIDs are recorded by the run time auditing system. But in a remote or Gateway target, the RETURNING clause is not generated, and nulls are passed to the run time auditing system for the ROWID field.
In set-based mode, you cannot load data from an Oracle database into a remote or Gateway target. All other modes, including set-based failover, are supported.
When you set the Operating Mode property of the target operator to set-based, a run time error occurs.
Row-based bulk processing is not supported.
Note:
Release 11.2.0.3 and onwards, the feature Set Based Failover Row Based has been deprecated.When you use a remote or Gateway target in a mapping, default workarounds are used for certain restricted activities. These workarounds are listed for your information only. You need not explicitly do anything to enable these workarounds.
The default workarounds used for a remote or a Gateway target are as follows:
When you set the loading type of a target to INSERT/UPDATE or UPDATE/INSERT in Oracle9i database and to UPDATE in Oracle Database 11g, a MERGE statement is generated to implement this mapping in set-based mode. But a MERGE statement cannot be run against remote or Gateway targets. Thus, when you use a remote or Gateway target in a mapping, code is generated without a MERGE statement. The generated code equals that generated when the PL/SQL generation mode is set to Oracle8i.
For set-based DML statements that reference a database sequence that loads into a remote or Gateway target, the GLOBAL_NAMES parameter must be set to TRUE. When code is generated for a mapping, this parameter is set to TRUE if the mapping contains a remote or Gateway target.
For a multitable insert to a remote or Gateway target, an INSERT statement is generated per table instead of a multitable insert statement.
While performing bulk inserts on a remote or non-Oracle Database, bulk processing code is not generated. Instead, code that processes one row at a time is generated. The Generate Bulk property of the operator is ignored.
Note:
The loading types used for remote or Gateway targets are the same as the ones used for other Oracle target operators. For more information about the loading type property, see "Loading Types for Oracle Target Operators".The Flat File operator enables you to use flat files as sources or targets in a mapping. The following section describes the usage of Flat File operators.
Use a Flat File operator to extract data from or load data into flat file.
A Flat File operator can be used either as a source or target in a mapping. However, the two are mutually exclusive within the same mapping. There are differences in code generation languages for flat file sources and targets. Subsequently, mappings can contain a mix of flat files, relational objects, and transformations, but with the restrictions discussed later in this section.
You have the following options for Flat File operators:
Using previously imported flat files
Importing and binding new flat files into your mapping
Defining new flat file sources or targets in mappings
To use a Flat File operator in a mapping:
Drag and drop a Flat File operator onto the Mapping Editor canvas.
Use the Add Flat File dialog box to create or select an object. For more information about these options, see "Using the Add Operator Dialog Box to Add Operators".
Map the attributes from the Flat File operator to the target, or map attributes from the source to the Flat File operator.
For examples of using flat files as sources and targets in a mapping, see Chapter 7, "Using SQL*Loader, SAP, and Code Template Mappings".
You can introduce data from a flat file into a mapping using either a Flat File operator or an External Table operator. If you are loading large volumes of data, then loading from a flat file enables you to use the DIRECT PATH SQL*Loader option, which results in better performance.
If you are not loading large volumes of data, you can benefit from many of the relational transformations available in the external table feature.
See Also:
Oracle Warehouse Builder Sources and Targets Guide for a comparison of external tables and flat files.As a source, the Flat File operator acts as the row set generator that reads from a flat file using the SQL*Loader utility. Do not use a Flat File source operator to map to a flat file target or to an external table. When you design a mapping with a Flat File source operator, you can use the following operators:
Other relational target objects, excluding the External Table operator.
Note:
If you use the Sequence, Expression, or Transformation operators, you cannot use the SQL*Loader Direct Load setting as a configuration parameter.When you use a flat file as a source in a mapping, remember to create a directory from the target location to the flat file location for the mapping to deploy successfully.
A mapping with a flat file target generates a PL/SQL package that loads data into a flat file instead of loading data into rows in a table.
Note:
A mapping can contain a maximum of 50 Flat File target operators.You can use an existing flat file with either a single record type or multiple record types. If you use a multiple-record-type flat file as a target, then you can only map to one of the record types. To load all of the record types in the flat file from the same source, then you can drop the same flat file into the mapping as a target again and map to a different record type. For an example, see "Using Direct Path Loading to Ensure Referential Integrity in SQL*Loader Mappings". Alternatively, create a separate mapping for each record type to load.
For more information about creating a new flat file target, see Oracle Warehouse Builder Sources and Targets Guide.
You can set properties for a Flat File operator as either a source or target. You can set "Loading Types for Flat Files" and the "Field Names in the First Row" setting. All other settings are read-only and depend upon how you imported the flat file.
Select a loading type from the list:
Insert: Creates a new target file. If there is an existing target file, then the newly created file replaces the previous file.
Update: Creates a new target file if one does not exist. If there is an existing target file, then that file is appended.
None: No operation is performed on the data in the target file. This setting is useful for testing purposes. All transformations and extractions are run without affecting the target.
Set this property to True to write the field names in the first row of the operator or False if you do not.
|
Copyright © 2000, 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|