| Oracle® Warehouse Builder Concepts 11g Release 2 (11.2) Part Number E10581-04 |
|
|
PDF · Mobi · ePub |
| Oracle® Warehouse Builder Concepts 11g Release 2 (11.2) Part Number E10581-04 |
|
|
PDF · Mobi · ePub |
This section discusses data quality management and data profiling. Through data management capabilities, Oracle Warehouse Builder ensures consistent, dependable data quality. Data profiling is the first step for any organization to improve information quality and provide better decisions.
This section contains these topics:
Oracle Warehouse Builder offers a set of features that assist you in creating data systems that provide high quality information to your business users. With Oracle Warehouse Builder you can implement a process that assesses, designs, transforms, and monitors data quality. The aim of building a data warehouse is to have an integrated, single source of data that is necessary to make business decisions. Since the data is usually sourced from multiple disparate systems, it is important to ensure that the data is standardized and cleansed before loading into the data warehouse.
Using Oracle Warehouse Builder for data management provides the following benefits:
Provides an end-to-end data quality solution
Enables you to include data quality and data profiling as an integral part of your data integration process.
Stores metadata regarding the quality of your data alongside your data definitions.
Automatically generates the mappings that you can use to correct data. These mappings are based on the business rules that you choose to apply to your data and decisions you make on how to correct data.
The rest of this section is devoted to discussing the phases of implementing and using data quality processes.
Ensuring data quality involves the following phases:
Figure 8-1 shows the phases involved in providing high quality information to your business users.
Figure 8-1 Phases Involved in Providing Quality Information
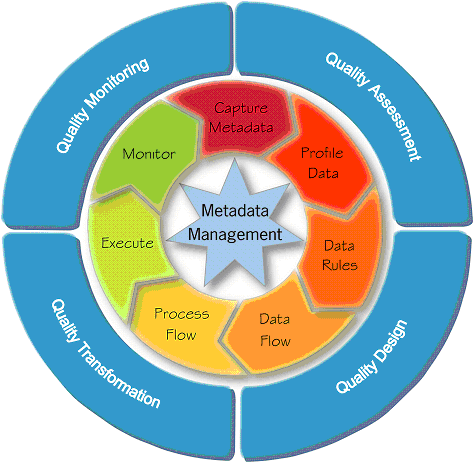
In the quality assessment phase, you determine the quality of the source data. The first step in this phase is to import the source data, which could be stored in different sources, into Oracle Warehouse Builder. You can import metadata and data from both Oracle and non-Oracle sources.
After you load the source data, you use data profiling to assess its quality. Data profiling is the process of uncovering data anomalies, inconsistencies, and redundancies by analyzing the content, structure, and relationships within the data. The analysis and data discovery techniques form the basis for data monitoring. For a quick summary of data profiling, see "Data Profiling: Assessing Data Quality".
The quality design phase consists of designing your quality processes. You can specify the legal data within a data object or legal relationships between data objects using data rules. For more information about data rules, see "Data Rules: Enforcing Data Quality".
As part of the quality design phase, you also design the transformations that ensure data quality. These transformations could be mappings that are generated by Oracle Warehouse Builder equals data profiling or mappings you create. The quality transformation phase consists of running the correction mappings you designed to correct the source data.
Data monitoring is the process of examining warehouse data over time and alerting you when the data violates business rules set for the data. For more information about data monitoring, see "Data Auditors: Monitoring Data Quality".
Data profiling enables you to assess the quality of your source data before you use it in data integration scenarios and systems. Oracle Warehouse Builder provides the Data Profile Wizard to guide you through creating a data profile, and the Data Profile Editor to configure and manage data profiles. Because data profiling is integrated with the ETL features in Oracle Warehouse Builder and other data quality features, such as data rules and built-in cleansing algorithms, you can also generate data cleansing mappings and schema correction scripts. It enables you to automatically correct any inconsistencies, redundancies, and inaccuracies in both the data and metadata.
Data profiling enables you to discover many important things about your data. Some common findings include:
A domain of valid product codes
A range of product discounts
Columns that hold the pattern of an e-mail address
A one-to-many relationship between columns
Anomalies and outliers within columns
Relations between tables even if they are not documented in the database
To begin the process of data profiling, you first use the Data Profile Wizard to create a data profile from within the Design Center. You then use the Data Profile Editor to run data profiling on the objects contained in the data profile, and to create correction tables and mappings.
See Also:
These topics in Oracle Warehouse Builder Data Modeling, ETL, and Data Quality Guide:A data rule is a definition of valid data values and relationships, which determine legal data within a table or legal relationships between tables. Data rules can be applied to tables, views, dimensions, cubes, materialized views, and external tables. They are used in many situations including data profiling, data and schema cleansing, and data auditing.
The metadata for a data rule is stored in the workspace. To use a data rule, you apply the data rule to a data object. For example, you could create a data rule called gender_rule, which could specify that valid values are 'M' and 'F'. You could then apply this data rule to the emp_gender column of the Employees table. Applying the data rule ensures that the values stored for the emp_gender column are either 'M' or 'F'. You can view the details of the data rule bindings on the Data Rule tab of the Data Object Editor for the Employees table.
A data rule can be derived from the results of data profiling, or it can be created using the Data Rule Wizard or OMB*Plus scripting commands.
Oracle Warehouse Builder provides a way to create custom data auditors, which are processes that provide data monitoring by validating data against a set of data rules to determine which records comply and which do not. Data auditors gather statistical metrics on how well the data in a system complies with a rule by auditing and marking how many errors are occurring against the audited data. The monitoring process builds on your data profiling and data quality initiatives.
Data auditors have thresholds that allow you to create logic because too many non-compliant records can divert the process flow into an error or notification stream. Based on this threshold, the process can choose actions. In addition, the audit results can be captured and stored for analysis purposes.
Data auditors can be deployed and executed ad-hoc, but they are typically run to monitor the quality of the data in an operational environment like a data warehouse or ERP system. Therefore, they can be added to a process flow and scheduled. When run, the data auditor sets several output values. One of these output values is called the audit result.
Data auditors also set the actual measured values such as Error Percent and Six Sigma values. Data auditors are a very important tool in ensuring that data quality levels are up to the standards set by the users of the system. It also helps determine spikes in bad data allowing events to the tied to these spikes.
See Also:
These topics in Oracle Warehouse Builder Data Modeling, ETL, and Data Quality Guide for procedures for using data auditors:Using the data profiling features in Oracle Warehouse Builder enables you to:
Profile data from any source or combination of sources that Oracle Warehouse Builder can access.
Explore data profiling results in tabular or graphical format.
Drill down into the actual data related to any profiling result.
Derive data rules, either manually or automatically, based on the data profiling results.
Derive quality indexes such as six-sigma valuations.
Profile or test any data rules you want to verify before putting in place.
See Also:
"Performing Data Profiling" in Oracle Warehouse Builder Data Modeling, ETL, and Data Quality Guide for detailed information and proceduresThe selection of data objects determines which aspects of that data that you can profile and analyze.
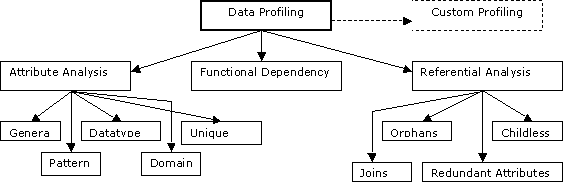
Data profiling offers these main types of analysis:
Figure 8-2 displays a representation of the types of data profiling and how you can perform each type.
Attribute analysis seeks to discover both general and detailed information about the structure and content of data stored within a given column or attribute.
Attribute analysis consists of:
Pattern analysis attempts to discover patterns and common types of records by analyzing the string of data stored in the attribute. It generates several regular expressions that match many of the values in the attribute, and reports the percentages of the data that follows each candidate regular expression. Oracle Warehouse Builder can also search for data that conforms to common regular expressions, such as dates, e-mail addresses, telephone numbers and Social Security numbers.
Table 8-1 shows a sample attribute, Job Code, that could be used for pattern analysis.
Table 8-1 Sample Columns Used for Pattern Analysis
| Job ID | Job Code |
|---|---|
|
7 |
337-A-55 |
|
9 |
740-B-74 |
|
10 |
732-C-04 |
|
20 |
43-D-4 |
Table 8-2 shows the possible results from pattern analysis, where D represents a digit and X represents a character. After looking at the results and knowing that it is company policy for all job codes be in the format of 999-A-99, you can derive a data rule that requires all values in this attribute to conform to this pattern.
Domain analysis identifies a domain or set of commonly used values within the attribute by capturing the most frequently occurring values. For example, the Status column in the Customers table is profiled and the results reveal that 90% of the values are among the following values: "MARRIED", "SINGLE", "DIVORCED". Further analysis and drilling down into the data reveal that the other 10% contains misspelled versions of these words with few exceptions. Configuration of the profiling determines when something is qualified as a domain; therefore, be sure to review the configuration before accepting domain values. You can then let Oracle Warehouse Builder derive a rule that requires the data stored in this attribute to be one of the three values that were qualified as a domain.
Data type analysis enables you to discover information about the data types found in the attribute. This type of analysis reveals metrics such as minimum and maximum character length values, scale and precision ranges. In some cases, the database column is of data type VARCHAR2, but the values in this column are all numbers. Then you may want to ensure that you only load numbers. Using data type analysis, you can have Oracle Warehouse Builder derive a rule that requires all data stored within an attribute to be of the same data type.
Unique key analysis provides information to assist you in determining whether an attribute is a unique key. It does this by looking at the percentages of distinct values that occur in the attribute. You might determine that attributes with a minimum of 70% distinct values should be flagged for unique key analysis. For example, using unique key analysis you could discover that 95% of the values in the EMP_ID column are unique. Further analysis of the other 5% reveals that most of these values are either duplicates or nulls. You could then derive a rule that requires that all entries into the EMP_ID column be unique and not null.
Functional dependency analysis reveals information about column relationships. It enables you to search for things such as one attribute determining another attribute within an object.
Table 8-3 shows the contents of the Employees table in which the attribute Dept. Location is dependent on the attribute Dept. Number. The attribute Dept. Number is not dependent on the attribute Dept. Location.
Referential analysis attempts to detect aspects of your data objects that refer to other objects. The purpose behind this type of analysis is to provide insight into how the object you are profiling is related or connected to other objects. Because you are comparing two objects in this type of analysis, one is often referred to as the parent object and the other as the child object. Some common things detected include orphans, childless objects, redundant objects, and joins. Orphans are values that are found in the child object, but not found in the parent object. Childless objects are values that are found in the parent object, but not found in the child object. Redundant attributes are values that exist in both the parent and child objects.
Table 8-4 and Table 8-5 show the contents of two tables that are candidates for referential analysis. Table 8-4, "Employees Table (Child)" is the child object, which inherits from Table 8-5, "Department Table (Parent)", the parent object.
Table 8-4 Employees Table (Child)
| ID | Name | Dept. Number | City |
|---|---|---|---|
|
10 |
Alison |
17 |
NY |
|
20 |
Rochnik |
23 |
SF |
|
30 |
Meijer |
23 |
SF |
|
40 |
Jones |
15 |
SD |
Referential analysis of these two objects would reveal that Dept. Number 15 from the Employees table is an orphan and Dept. Numbers 18, 20, and 55 from the Department table are childless. It would also reveal a join on the Dept. Number column.
Based on these results, you could derive referential rules that determine the cardinality between the two tables.
In addition to attribute analysis, functional dependency analysis, and referential analysis, Oracle Warehouse Builder offers data rule profiling. Data rule profiling enables you to create rules to search for profile parameters within or between objects.
This is very powerful as it enables you to validate rules that apparently exist and are defined by the business users. By creating a data rule, and then profiling with this rule you can verify if the data actually complies with the rule, and whether the rule needs amending or the data needs cleansing.
For example, the HR department might define a rule that states that Income = Salary + Bonus for the Employee table shown in Table 8-6. You can then catch errors such as the one for employee Alison.
Table 8-6 Sample Employee Table
| ID | Name | Salary | Bonus | Income |
|---|---|---|---|---|
|
10 |
Alison |
1000 |
50 |
1075 (error) |
|
20 |
Rochnik |
1000 |
75 |
1075 |
|
30 |
Meijer |
300 |
35 |
335 |
|
40 |
Jones |
1200 |
500 |
1700 |
See Also:
"Data Cleansing and Correction with Data Rules" in Oracle Warehouse Builder Data Modeling, ETL, and Data Quality Guide.Oracle Warehouse Builder provides Six Sigma results and metrics embedded within the other data profiling results to provide a standardized approach to data quality.
See Also:
"Viewing Profile Results" under "Performing Data Profiling" in Oracle Warehouse Builder Data Modeling, ETL, and Data Quality Guide for information on Six Sigma resultsSix Sigma is a methodology that attempts to standardize the concept of quality in business processes. It achieves this goal by statistically analyzing the performance of business processes. The goal of Six Sigma is to improve the performance of these processes by identifying the defects, understanding them, and eliminating the variables that cause these defects.
Six Sigma metrics give a quantitative number for the number of defects for each 1,000,000 opportunities. The term "opportunities" can be interpreted as the number of records. The perfect score is 6.0. The score of 6.0 is achieved when there are only 3.4 defects for each 1,000,000 opportunities. The score is calculated using the following formula:
Defects Per Million Opportunities (DPMO) = (Total Defects / Total Opportunities) * 1,000,000
Defects (%) = (Total Defects / Total Opportunities)* 100%
Yield (%) = 100 - %Defects
Process Sigma = NORMSINV(1-((Total Defects) / (Total Opportunities))) + 1.5
where NORMSINV is the inverse of the standard normal cumulative distribution.
When you perform data profiling, the number of defects and anomalies discovered are shown as Six Sigma metrics. For example, if data profiling finds that a table has a row relationship with a second table, the number of records in the first table that do not adhere to this row-relationship can be described using the Six Sigma metric.
Six Sigma metrics are calculated for the following measures in the Data Profile Editor:
Aggregation: For each column, the number of null values (defects) to the total number of rows in the table (opportunities).
Domains: For each column, the number of values that do not follows the documented domain (defects) to the total number of rows in the table (opportunities).
Referential: For each row relationship, the number of values that does not follows the remote key to the total number of rows in the table.
Functional Dependency: For each column, the number of values that are redundant (defects) to the total number of rows in the table (opportunities).
Unique Key: For each unique key, the number of values that does not follows the documented unique key (defects) to the total number of rows in the table (opportunities).
Oracle Warehouse Builder enables you to automatically create corrected data objects and correction mappings based on the results of data profiling. On top of these automated corrections that make use of the underlying Oracle Warehouse Builder architecture for data quality, you can create your own data quality mappings to correct and cleanse source data.
See Also:
"Overview of Automatic Data Correction and Data Rules" in Oracle Warehouse Builder Data Modeling, ETL, and Data Quality GuideWhen you perform data profiling, Oracle Warehouse Builder generates corrections for the objects that you profiled. You can then decide to create corrected objects based on results of data profiling. The corrections are in the form of data rules that can be bound to the corrected object.
See Also:
"Generating Corrections Based on Data Profiling Results" in Oracle Warehouse Builder Data Modeling, ETL, and Data Quality Guide.You can perform the following types of corrections on source data objects:
Schema correction creates scripts that you can use to create a corrected set of source data objects with data rules applied to them. The corrected data objects adhere to the data rules derived from the results of data profiling.
The correction tables have names that are prefixed with TMP__. For example, when you profile the EMPLOYEES table, the correction table is called TMP__EMPLOYEES.
Data correction is the process of creating correction mappings to remove anomalies and inconsistencies in the source data before loading it into the corrected data objects. Correction mappings enforce the data rules defined on the data objects. While moving data from the old "dirty" tables in the profile source tables into the corrected tables, these mappings correct records that does not follow the data rules.
The name of the correction mapping is the object name prefixed with M_. For example, the correction mapping for the EMPLOYEE table is called M_EMPLOYEE.
To perform data correction on source data, you specify the following information:
See Also:
"Data Cleansing and Correction with Data Rules" in Oracle Warehouse Builder Data Modeling, ETL, and Data Quality Guide for complete procedures.Based on the data profiling results, Oracle Warehouse Builder derives a set of data rules that you can use to cleanse the source data. You can automatically generate corrections based on these data rules by performing data correction actions.
For each data rule derived equals data profiling, you must choose a correction action that specifies how data values that are not accepted due to data rule enforcement should be handled. The correction actions you can choose are:
Ignore: The data rule is ignored and, therefore, no values are rejected based on this data rule.
Report: The data rule is run only after the data has been loaded for reporting purposes. It is similar to the Ignore option, except that a report is created that contains the values that do not adhere to the data rules. This action can be used for some rule types only.
Cleanse: The values rejected by this data rule are moved to an error table where cleansing strategies are applied. When you select this option, you must specify a cleansing strategy.
Cleansing Strategies for Data Correction
When you decide to automatically generate corrected objects based on data profiling results, you must specify how inconsistent data from the source should be cleansed before being stored in the corrected object. To do the same, you specify a cleansing strategy for each data rule that is applied to the correction object. Error tables are used to store the records that do not conform to the data rule.
The cleansing strategy you use depends on the type of data rule and the rule configuration.
See Also:
These topics in Oracle Warehouse Builder Data Modeling, ETL, and Data Quality Guide :"Generating Corrections Based on Data Profiling Results" for details about strategies and procedures
"Cleansing and Transforming Source Data Based on Data Profiling Results" for procedures on deploying corrections
Oracle Warehouse Builder provides general-purpose data matching and merging capabilities that can be applied to any type of data, including data deduplication features. Matching determines which records refer to the same logical data. Oracle Warehouse Builder provides a variety of match rules to compare records. Match rules range from a simple exact match to sophisticated algorithms that can discover and correct common data entry errors. Merging consolidates matched records into a single consolidated "golden standard" record based on survivorship rules called merge rules that you select or define for creating a merged value for each column.
See Also :
"Matching, Merging, and Deduplication" in Oracle Warehouse Builder Data Modeling, ETL, and Data Quality Guide for complete procedures.
|
Copyright © 2000, 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|