| Oracle® Warehouse Builder Data Modeling, ETL, and Data Quality Guide 11g Release 2 (11.2) Part Number E10935-05 |
|
|
PDF · Mobi · ePub |
| Oracle® Warehouse Builder Data Modeling, ETL, and Data Quality Guide 11g Release 2 (11.2) Part Number E10935-05 |
|
|
PDF · Mobi · ePub |
This chapter describes the data profiling features of Oracle Warehouse Builder and how to use them, with Oracle Warehouse Builder ETL or with other ETL tools.
This chapter contains the following topics:
"Tuning the Data Profiling Process for Better Profiling Performance"
"Data Watch and Repair (DWR) for Oracle Master Data Management (MDM)"
Data profiling enables you to assess the quality of your source data before you use it in data warehousing or other data integration scenarios.
Data profiling analyzes the content, structure, and relationships within data to uncover patterns and rules, inconsistencies, anomalies, and redundancies.
Data profiling can be usefully applied to any source in a data integration or warehousing scenario, and to master data stores in MDM scenarios. It is also useful for any scenario involving a new source, because it enables the discovery of information beyond the basic metadata defined in the data dictionary.
Oracle Warehouse Builder data profiling can support the following source types:
Oracle databases
Data sources accessed through Oracle gateways or ODBC
Flat file sources
To profile flat files, you must import them into Oracle Warehouse Builder, create external tables based on the flat files, and then profile the external tables.
SAP R/3 and other ERP application sources
Note:
Data profiling does not support sources accessed through JDBC.Oracle Warehouse Builder data profiling and the rest of the data quality features also derive value from and add value to Oracle Warehouse Builder ETL in the following ways:
Oracle Warehouse Builder data quality can automatically generate data cleansing logic based on data rules. The cleansing processes are implemented by automatically created ETL mappings, with the same functionality as other ETL mappings. Deployment, execution and scheduling for data cleansing processes is identical to other mappings. Developers familiar with Oracle Warehouse Builder ETL features can, for example, tune performance on data cleansing processes, look at the generated code, and so on, as with any ETL mappings. Where custom data cleansing and correction logic is required, it can be implemented in PL/SQL.
Metadata about data profiling results, represented as data rules, can be bound to the profiled data objects, and those rules are then available in any context in which the profiled objects are used in ETL.
For example, Oracle Warehouse Builder ETL can use data rules in ETL logic to implement separate data flows for compliant and noncompliant rows in a table. Noncompliant rows can be routed through any data cleansing, correction or augmentation logic available in the database, transformed using ordinary mapping operators, or simply logged in the error table. All required logic for the different options for handling noncompliant rows is automatically generated, for any Oracle Warehouse Builder mapping in which a data rule is used.
The data profiling features of Oracle Warehouse Builder also use the infrastructure of Oracle Warehouse Builder ETL to connect to data sources, access the data to be profiled, and move intermediate profiling results into a scratch area called a profiling workspace.
Oracle Warehouse Builder data profiling and data quality can be used alongside any third-party ETL solution or hand-coded ETL solution. In such scenarios, the usage model is:
Leave your existing ETL solution in place
In Oracle Warehouse Builder, create a workspace and locations so that you can connect to your data sources.
Create a data profile, add the objects to be profiled, and set any profiling parameters.
Run your profiling jobs
Explore the results in the Data Profile Editor
Derive data rules based on the profiling results, understand better and document patterns in your data.
See "Performing Data Profiling" for details on how to perform these tasks.
You can also use the data cleansing and correction features of Oracle Warehouse Builder alongside third party ETL solutions. See Chapter 21, "Data Cleansing and Correction with Data Rules" for details on data cleansing and correction, and Chapter 20, "Monitoring Quality with Data Auditors and Data Rules" for details on data auditing.
The Data Profile Editor provides the primary user interface for most of the data profiling, data rules and data cleansing functionality of Oracle Warehouse Builder. From the Data Profile Editor, you can:
Set up and run data profiling, that is, attribute analysis and structural analysis of selected objects.
Generate a new target schema based on the profile analysis and source table rules, where all of the data is compliant with the data rules applied to objects in the profile.
Automatically generate mappings and transformations that perform data correction based on your data rules and selected cleansing strategies.
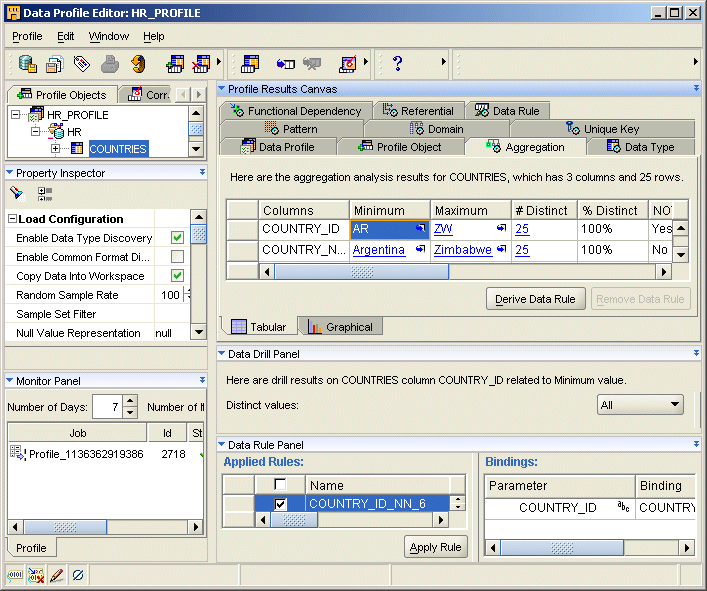
Figure 18-1 displays the Data Profile Editor.
The Data Profile Editor consists of the following:
Menu Bar
Toolbars
Object Tree
Property Inspector
Monitor Panel
Profile Results Canvas
Data Drill Panel
Data Rule Panel
Refer to the online help for detailed information about the contents of each panel.
Data profiling is resource intensive and profile execution times can be quite long, especially on large data volumes. Profiling the entire contents of one or all of your source systems is not likely to be the most efficient way to produce useful profiling results. An iterative approach, in which initial limited data profiling produces discoveries that are used in deciding what to profile next, is more likely to be effective when faced with a large and complex set of sources to profile.
The following guidelines can increase the usefulness of your data profiling results while reducing profiling time and effort:
Profile sources that impact numerous downstream objects, or where the objects affected are the most important outputs of your system. For example, if a source table contains data that affect the contents of numerous downstream business intelligence reports, then consider profiling that table. If only certain columns are used in downstream targets, then consider using attribute sets to limit profiling to those columns.
Tip:
Use the data lineage and impact analysis features of Oracle Warehouse Builder to identify sources with wide impact in your system. For more information, see Oracle Warehouse Builder Installation and Administration Guide.Profile sources that are more likely to contain erroneous data. For example, customer and order data that are entered manually are more likely to contain errors than product data downloaded from suppliers.
Profile any new source before integrating it into any existing system, especially sources where initial data quality is unknown.
If you have documentation for a source, you may want to define data rules based on that documentation, then specifically profile for compliance with those rules. If this effort reveals noncompliant data, then consider more complete profiling.
Disable types of profiling that are not likely to provide significant results. For example, you may want to perform an initial profiling pass limited to domain discovery or before more advanced and computationally intensive profiling types such as discovering functional dependencies.
Initially, limit profiling to a random sampling of data, rather than profiling the entire contents of a source. After identifying an initial set of data rules, you can profile all rows for compliance with those rules.
For example, consider a data source that contains five tables: CUSTOMERS, REGIONS, ORDERS, PRODUCTS, and PROMOTIONS. You have the following information:
The CUSTOMERS table is known to contain many duplicate and erroneous entries and is used in creating marketing campaigns.
The ORDERS table includes order data transcribed from handwritten forms and telephone orders
The PRODUCTS table contains data downloaded from a trusted supplier, and has a VARCHAR2(4000) column DESCRIPTION that contains free-form text.
The documentation for the source system says that there is a foreign key relationship between the ORDERS and REGIONS tables, but this documentation is several years old and the source systems may have changed.
In such a case, you can limit your initial profiling process as follows:
Profile the CUSTOMERS table before the others, because it is known to contain errors
Exclude the PRODUCTS.DESCRIPTION column from all profiling, because free-form text is not likely to produce useful information in profiling
Use random sampling to profile a limited number of rows from all of the tables
Profile the ORDERS and REGIONS tables to test the foreign key relationship
Later, you can do more profiling based on discoveries in the first passes.
See Also:
"Tuning the Data Profiling Process for Better Profiling Performance" for information about how to tune the data profiling process.You can only profile data stored in Oracle databases, data accessible through Oracle Gateways, and data in SAP systems. You must profile the data stored in a flat file, then create an external table based on this flat file.
You cannot directly profile data that is accessed through JDBC-based connectivity. You must first stage this data in an Oracle Database and then profile it.
Data profiling always uses the default configuration. Customers using multiple configurations should ensure that the default configuration has appropriate settings for profiling.
The profiling workspace location must be an Oracle 10g database or higher.
You cannot profile a source table that contains complex data types if the source module and the data profile are located on different database instances.
Data profiling cannot analyze more than 165 columns of data in each table, view or materialized view at a time. If you profile an object with more than 165 columns, then you must create an attribute set to select a subset of columns to be profiled. See "Using Attribute Sets to Profile a Subset of Columns from a Data Object" for details.
Before profiling data objects, ensure that your project contains the correct metadata for the source objects on which you are performing data profiling.
The objects to be profiled must contain source data. For example, if you are profiling tables stored in a staging area, you must load the staging tables from their sources before executing the profile.
Because data profiling uses mappings to run the profiling, you must ensure that all locations that you are using are registered. Data profiling attempts to register your locations. If, for some reason, data profiling cannot register your locations, you must explicitly register the locations before you begin profiling.
See Also:
Oracle Warehouse Builder Sources and Targets Guide for more information about importing metadata.To prepare for data profiling, you must create one or more data profile objects in your project. Each data profile object is a metadata object in a project. A data profile object stores the following:
The set of objects to be profiled
The types of profiling to perform on this set of objects
Settings such as thresholds that control the profiling operations
Results returned by the most recent execution of data profiling using these settings
Metadata about data corrections generated from profiling results
After you have decided which objects to profile, use the following steps to guide you through the profiling process:
In the Projects Navigator, expand a project node and import all objects to profile into this project.
Under the project into which you imported objects, create a data profile object that contains the objects to be profiled.
Configure the data profile to specify the types of analysis to perform on the data being profiled.
Profile the data to perform the types of analysis specified in the previous step.
See "Profiling Data".
View and analyze the data profiling results.
Based on the profiling results, you can decide to generate schema and data corrections. These corrections are automatically generated by Oracle Warehouse Builder. For more information about automatically generating schema and data corrections, see "Generating Correction Mappings from Data Profiling Results".
You can also derive data rules based on the data profiling results. For more information about deriving data rules based on profiling results, see "Deriving Data Rules From Data Profiling Results".
Once your locations are prepared and the data is available, you must create a data profile object in Design Center. A data profile is a metadata object in the workspace that specifies the set of data objects to profile, the settings controlling the profiling operations, the results returned after you profile the data, and correction information (to use these corrections).
To create a data profile:
From the Projects Navigator, expand the project node in which you want to create a data profile.
Right-click Data Profiles and select New Data Profile.
The Welcome page of the Data Profile Wizard is displayed.
On the Welcome page, click Next.
On the Name and Description page, enter a name and an optional description for the data profile. Click Next.
On the Select Objects page, select the objects to include in the data profile and use the arrows to move them to the Selected list. Click Next.
To select multiple objects, hold down the Ctrl key while selecting objects. You can include tables, views, materialized views, external tables, dimensions, and cubes in your data profile.
If you selected tables, views, or materialized views that contain attribute sets, the Choose Attribute Set dialog box is displayed. The list at the bottom of this dialog box displays the attribute sets defined on the data object.
To profile only the attributes defined in the attribute set, select the attribute set from the list.
To profile all columns in the data object, select <all columns> from the list.
If you selected dimensional objects on the Select Objects page, a warning is displayed informing you that the relational objects bound to these dimensional objects is also added to the profile. Click Yes to proceed.
On the Summary page, review the choices that you made on the previous wizard pages. Click Back to change any selected values. Click Finish to create the data profile.
Oracle Warehouse Builder note dialog is displayed. Click OK to display the Data Profile Editor for the newly created data profile.
The new data profile is added to the Data Profiles node in the navigation tree.
You can, and should, configure a data profile before running it if there are specific types of analysis that you do, or do not, want to run.
You can configure a data profile at one of the following levels:
The entire profile (all the objects contained in the profile)
An individual object in the data profile
For example, the data profile contains three tables. To perform certain types of analysis on one table, configure this table only.
An attribute within an object
For example, you know that there is only one problematic column in a table and you know that most of the records should conform to values within a certain domain. You can focus your profiling resources on domain discovery and analysis. By narrowing down the type of profiling necessary, you use fewer resources and obtain the results faster.
In the Projects Navigator, right-click the data profile and select Open.
The Data Profile Editor for the data profile is displayed.
Select the level at which you want to set configuration parameters.
To configure the entire data profile, on the Profile Objects tab, select the data profile.
To configure a particular object in the data profile, on the Profile Objects tab, expand the node that represents the data profile. Select the data object by clicking on the data object name.
To configure an attribute within an object in a data profile, on the Profile Objects tab, expand the node that represents the data profile. Expand the data object that contains the attribute and then select the required attribute by clicking the attribute name.
Set the required configuration parameters using the Property Inspector panel.
Configuration parameters are categorized into the following types: Load, Aggregation, Pattern Discovery, Domain Discovery, Relationship Attribute Count, Unique Key Discovery, Functional Dependency Discovery, Row Relationship Discovery, Redundant Column Discovery, and Data Rule Profiling. The following sections provide descriptions for the parameters in each category.
Table 18-1 describes the parameters in this category.
Table 18-1 Description of Load Configuration Parameters
| Configuration Parameter Name | Description |
|---|---|
|
Enable Data Type Discovery |
Set this parameter to true to enable data type discovery for the selected table. |
|
Enable Common Format Discovery |
Set this parameter to true to enable common format discovery for the selected table. |
|
Copy Data Into Workspace |
Set this parameter to true to enable copying of data from the source to the profile workspace. |
|
Random Sample Rate |
This value represents the percent of total rows that is randomly selected during loading. |
|
Always Force a Profile |
Set this parameter to true to force the data profiler to reload and reprofile the data objects. |
|
Sample Set Filter |
This represents the |
|
Null Value Representation |
This value is considered as null value during profiling. You must enclose the value in single quotation marks. The default value is null, which is considered as a database null. |
This category contains the Not Null Recommendation Percentage parameter. If the percentage of null values in a column is less than this threshold percent, then that column is discovered as a possible Not Null column.
Enable Pattern Discovery: Set this parameter to true to enable pattern discovery.
Maximum Number of Patterns: This represents the maximum number of patterns that the profiler gets for the attribute. For example, when you set this parameter to 10, it means that the profiler gets the top 10 patterns for the attribute.
Table 18-2 describes the parameters in this category.
Table 18-2 Description of Domain Discovery Configuration Parameters
| Configuration Parameter Name | Description |
|---|---|
|
Enable Domain Discovery |
Set this parameter to true to enable domain discovery. |
|
Domain Discovery Max Distinct Values Count |
Represents the maximum number of distinct values in a column in order for that column to be discovered as possibly being defined by a domain. Domain discovery of a column occurs if the number of distinct values in that column is at or below the Max Distinct Values Count property, and the number of distinct values as a percentage of total rows is at or below the Max Distinct Values Percent property. |
|
Domain Discovery Max Distinct Values Percent |
Represents the maximum number of distinct values in a column, expressed as a percentage of the total number of rows in the table, in order for that column to be discovered as possibly being defined by a domain. Domain Discovery of a column occurs if the number of distinct values in that column is at or below the Max Distinct Values Count property, and the number of distinct values as a percentage of total rows is at or below the Max Distinct Values Percent property. |
|
Domain Value Compliance Min Rows Count |
Represents the minimum number of rows for the given distinct value in order for that distinct value to be considered as compliant with the domain. Domain Value Compliance for a value occurs if the number of rows with that value is at or above the Min Rows Count property, and the number of rows with that value as a percentage of total rows is at or above the Min Rows Percent property. |
|
Domain Value Compliance Min Rows Percent |
Represents the minimum number of rows, expressed as a percentage of the total number of rows, for the given distinct value in order for that distinct value to be considered as compliant with the domain. Domain Value Compliance for a value occurs if the number of rows with that value is at or above the Min Rows Count property, and the number of rows with that value as a percentage of total rows is at or above the Min Rows Percent property. |
This category contains the Maximum Attribute Count parameter that represents the maximum number of attributes for unique key, foreign key, and functional dependency profiling.
Enable Unique Key Discovery: Set this parameter to true to enable unique key discovery.
Minimum Uniqueness Percentage: This is the minimum percentage of rows that must satisfy a unique key relationship.
Enable Functional Dependency Discovery: Set this parameter to true to enable functional dependency discovery.
Minimum Functional Dependency Percentage: This is the minimum percentage of rows that must satisfy a functional dependency relationship.
Enable Relationship Discovery: Set this parameter to true to enable foreign key discovery.
Enable Soundex Relationship Discovery: Set this parameter to true to enable soundex relationship discovery for columns with string data types. You must ensure that these attributes are part of relationship discovery.
Minimum Relationship Percentage: This is the minimum percentage of rows that must satisfy a foreign key relationship.
Minimum Soundex Relationship Percentage: This is the minimum percentage of rows that must satisfy a soundex relationship. Values with the same soundex value are considered the same.
Enable Redundant Columns Discovery: Set this parameter to true to enable redundant column discovery to a foreign key-unique key pair.
Minimum Redundancy Percentage: This is the minimum percentage of rows that are redundant.
This category contains the Enable Materialized View Creation parameter. Set this parameter to true to create materialized views for each column in every table of the data profile. This enhances query performance during drill down.
This category contains the Enable Data Rule Profiling for Table parameter. Set this parameter to true to enable data rule profiling for the selected table. This setting is only applicable for a table, and not for an individual attribute.
Data profiling is achieved by performing deep scans of the selected objects. This can be a time-consuming process, depending on the number of objects and the type of profiling that you run. However, profiling is run as an asynchronous job, and the Design Center client can be closed during this process. As with ETL jobs, you see the job running in the job monitor. Oracle Warehouse Builder prompts you when the profiling job is complete.
After you have created a data profile, you can open it in the Data Profile Editor to profile the data or review profile results from a previous run. The objects that you selected when creating the profile are displayed in the object tree of the Data Profile Editor. You can add objects to the profile by selecting Profile and then Add.
To profile data using a data profile:
Expand the Data Profiles node in the Projects Navigator, right-click a data profile, and select Open.
The Data Profile Editor opens the selected data profile.
If you have not done so, configure the data profile as described in "Configuring Data Profiles".
From the Profile menu, select Profile.
If this is the first time you are profiling data, the Data Profile Setup dialog box is displayed. Enter the details of the profiling workspace. For more information about the information to be entered, click Help.
Oracle Warehouse Builder begins preparing metadata for profiling. The progress window containing the name of the object being created to profile the data is displayed. After the metadata preparation is complete, the Profiling Initiated dialog box is displayed, informing you that the profiling job has started.
On the Profiling Initiated dialog box, click OK.
Once the profiling job starts, the data profiling is asynchronous, and you can continue working or even close the Design Center. Your profiling process continues to run until it is completed.
View the status of the profiling job in the Monitor panel of the Data Profile Editor.
You can continue to monitor the progress of your profiling job in the Monitor panel. After the profiling job is complete, the status displays as complete.
After the profiling is complete, the Retrieve Profile Results dialog box is displayed, and you are prompted to refresh the results. Click Yes to retrieve the data profiling results and display them in the Data Profile Editor.
Note:
Data profiling results are overwritten on subsequent profiling executions.After the profile operation is complete, you can open the data profile in the Data Profile Editor to view and analyze the results. The profiling results contain a variety of analytical and statistical information about the data profiled. You can immediately drill down into anomalies and view the data that caused them. You can then determine what data must be corrected.
To view the profile results:
Select the data profile in the navigation tree, right-click, and select Open.
The Data Profile Editor opens and displays the data profile.
If you have previous data profiling results displayed in the Data Profile Editor, refresh the view when prompted so that the latest results are shown.
The results of the profiling are displayed in the Profile Results Canvas.
Minimize the Data Rule and Monitor panels by clicking on the arrow symbol in the upper-left corner of the panel.
This maximizes your screen space.
Select objects in the Profile Objects tab of the object tree to focus the results on a specific object.
The profiling results for the selected object are displayed using the following tabs of the Profile Results Canvas.
You can switch between various objects in the data profile. The tab that you had selected for the previous object remains selected.
The Data Profile tab contains general information about the data profile. Use this tab to store any notes or information about the data profile.
The Profile Object tab contains two subtabs: Object Data and Object Notes. The Object Data tab lists the data records in the object you have selected in the Profile Objects tab of the object tree. The number of rows that were used in the sample is listed. You can use the buttons along the top of the tab to run a query, get more data, or add a WHERE clause.
The Aggregation tab displays all the essential measures for each column, such as minimum and maximum values, number of distinct values, and null values. Some measures are available only for specific data types. These include the average, median, and standard deviation measures. Information can be viewed from either the Tabular or Graphical subtabs.
Table 18-3 describes the various measurement results available in the Aggregation tab.
Table 18-3 Aggregation Results
| Measurement | Description |
|---|---|
|
Column |
Name of the column, within the profiled data object, for which data profiling determined the aggregation measures |
|
Minimum |
Minimum value for the inherent database ordering for the column |
|
Maximum |
Maximum value for the inherent database ordering of the column |
|
# Distinct |
Total number of distinct values for the column |
|
% Distinct |
Percentage of distinct values in the column over the entire row set |
|
Not Null |
Indicates if a NOT NULL constraint is defined in the database for the column |
|
Recommended NOT NULL |
Indicates if data profiling results recommend that the column enable null values. A value of Yes represents a recommendation that this column should not enable null values |
|
# Nulls |
Total number of null values for the column |
|
%Nulls |
Percentage of null values, for the column, over the entire row set |
|
Six Sigma |
Number of null values (defects) to the total number of rows in the table (opportunities) |
|
Average |
Average value, for the column, in the entire row set |
|
Median |
Median value, for the column, in the entire row set |
|
Std Dev |
Standard deviation for the column |
A hyperlinked value in the aggregation results grid indicates that you can click the value to drill down into the data. It enables you to analyze the data in the sample that produced this result.
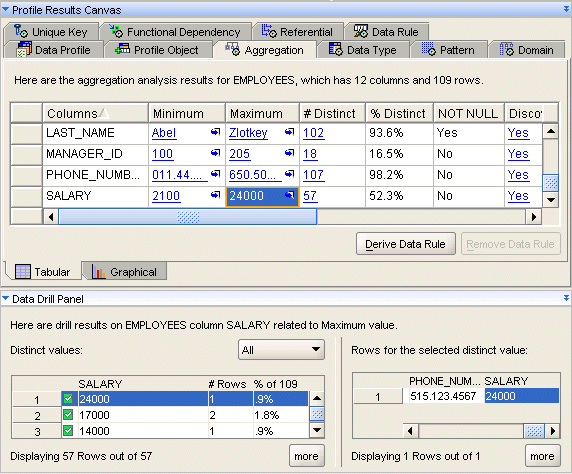
For example, if you scroll to the SALARY column, shown in Figure 18-2, and click the value in the Maximum cell showing 24000, the Data Drill Panel at the bottom changes to show you all the distinct values in this column with counts on the left. On the right, the Data Drill can zoom into the value that you select from the distinct values and display the full record where these values are found.
The graphical analysis displays the results in a graphical format. You can use the graphical toolbar to change the display. You can also use the Column and Property menus to change the displayed data object.
The Data Type tab provides profiling results about data types. This includes metrics such as length for character data types and the precision and scale for numeric data types. For each data type that is discovered, the data type is compared to the dominant data type found in the entire attribute and the percentage of rows that follows the dominant measure is listed.
One example of data type profiling would be finding a column defined as VARCHAR that stores only numeric values. Changing the data type of the column to NUMBER would make storage and processing more efficient.
Table 18-4 describes the various measurement results available in the Data Type tab.
| Measurement | Description |
|---|---|
|
Columns |
Name of the column, within the data object, for which data type analysis was performed |
|
Documented Data Type |
Data type of the column in the source object |
|
Dominant Data Type |
From analyzing the column values, data profiling determines that this is the dominant (most frequent) data type. |
|
% Dominant Data Type |
Percentage of total number of rows where column value has the dominant data type |
|
Documented Length |
Length of the data type in the source object |
|
Minimum Length |
Minimum length of the data stored in the column |
|
Maximum Length |
Maximum length of the data stored in the column |
|
Dominant Length |
From analyzing the column values, data profiling determines that this is the dominant (most frequent) length. |
|
% Dominant Length |
Percentage of total number of rows where column value has the dominant length |
|
Documented Precision |
Precision of the data type in the source object |
|
Minimum Precision |
Minimum precision for the column in the source object |
|
Maximum Precision |
Maximum precision for the column in the source object |
|
Dominant Precision |
From analyzing the column values, data profiling determines that this is the dominant (most frequent) precision |
|
% Dominant Precision |
Percentage of total number of rows where column value has the dominant precision |
|
Documented Scale |
Scale specified for the data type in the source object |
|
Minimum Scale |
Minimum scale of the data type in the source object |
|
Maximum Scale |
Maximum scale of the data type in the source object |
|
Dominant Scale |
From analyzing the column values, data profiling determines that this is the dominant (most frequent) scale. |
|
% Dominant Scale |
Percentage of total number of rows where column value has the dominant scale |
The Domain tab displays results about the possible set of values that exist in a certain attribute. Information can be viewed from either the Tabular or Graphical subtabs.
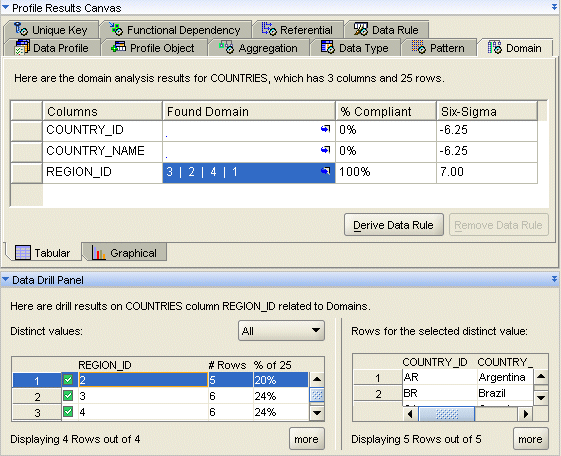
Figure 18-3 displays the Domain tab of the Data Profile Editor.
The process of discovering a domain on a column involves two phases. First, the distinct values in the column are used to determine whether that column might be defined by a domain. Typically, there are few distinct values in a domain. Then, if a potential domain is identified, the count of distinct values is used to determine whether that distinct value is compliant with the domain. The properties that control the threshold for both phases of domain discovery can be set in the Property Inspector.
If you find a result to know more about, drill down and use the Data Drill panel to view details about the cause of the result.
For example, a domain of four values was found for the column REGION_ID: 3,2,4, and 1. To see which records contributed to this finding, select the REGION_ID row and view the details in the Data Drill panel.
Table 18-5 describes the various measurement results available in the Domain tab.
| Measurement | Description |
|---|---|
|
Column |
Name of the column for which domain discovery was performed |
|
Found Domain |
The discovered domain values |
|
% Compliant |
The percentage of all column values that are compliant with the discovered domain values |
|
Six Sigma |
The Six Sigma value for the domain results |
The Pattern tab displays information discovered about patterns within the attribute. Pattern discovery is the profiler's attempt at generating regular expressions for data that it discovered for a specific attribute. Non-English characters are not supported in the pattern discovery process.
Table 18-6 describes the various measurement results available in the Pattern tab.
| Measurement | Description |
|---|---|
|
Columns |
Name of the column for which pattern results were discovered |
|
Dominant Character Pattern |
The most frequently discovered character pattern or consensus pattern |
|
% Compliant |
The percentage of rows whose data pattern agrees with the dominant character pattern |
|
Dominant Word Pattern |
The most frequently discovered word character pattern or consensus pattern |
|
% Compliant |
The percentage of rows whose data pattern agrees with the dominant word pattern |
|
Common Format |
Name, Address, Date, Boolean, Social Security Number, E-mail, URL. This is the profiler's attempt to add semantic understanding to the data that it sees. Based on patterns and some other techniques, it tries to determine which domain bucket a certain attribute's data belongs to. |
|
% Compliant |
The percentage of rows whose data pattern agrees with the consensus common format pattern |
The Unique Key tab provides information about the existing unique keys that were documented in the data dictionary, and possible unique keys or key combinations that were detected by the data profiling operation. The uniqueness % is shown for each. The unique keys that have No in the Documented column are the ones that are discovered by data profiling.
For example, a phone number is unique in 98% of the records. It can be a unique key candidate, and you can then cleanse the noncompliant records. You can also use the drill-down feature to view the cause of the duplicate phone numbers in the Data Drill panel. Table 18-7 describes the various measurement results available in the Unique Key tab.
| Measurement | Description |
|---|---|
|
Unique Key |
The discovered unique key |
|
Documented |
Indicates if a unique key on the column exists in the data dictionary. A value of Yes indicates that a unique key exists in the data dictionary. A value of No indicates that the unique key was discovered because of data profiling. |
|
Discovered |
From analyzing the column values, data profiling determines whether a unique key should be created on the column listed in the Local Attribute(s) column. |
|
Local Attribute(s) |
The name of the column in the data object that was profiled |
|
# Unique |
The number of rows, in the source object, in which the attribute represented by Local Attribute is unique |
|
% Unique |
The percentage of rows, in the source object, for which the attribute represented by Local Attribute is unique |
|
Six Sigma |
Number of null values (defects) to the total number of rows in the table (opportunities) |
The Functional Dependency tab displays information about the attribute or attributes that seem to depend on or determine other attributes. Information can be viewed from either the Tabular or Graphical subtabs. You can use the Show list to change the focus of the report. Unique keys defined in the database are not discovered as functional dependencies during data profiling.
Table 18-8 describes the various measurement results available in the Functional Dependency tab.
Table 18-8 Functional Dependency Results
| Measurement | Description |
|---|---|
|
Determinant |
Name of the attribute that is found to determine the attribute listed under Dependent |
|
Dependent |
Name of the attribute that is found to be determined by the value of another attribute |
|
# Defects |
Number of values in the Determinant attribute that were not determined by the Dependent attribute |
|
% Compliant |
Percentage of values that are compliant with the discovered dependency |
|
Six Sigma |
Six Sigma value |
|
Type |
Type of functional dependency. Possible values are unidirectional or bidirectional |
For example, if you select Only 100% dependencies from the Show list, the information shown is limited to absolute dependencies. If you have an attribute that is always dependent on another attribute, then it is recommended that it be a candidate for a reference table. Suggestions are shown in the Type column. Removing the attribute into a separate reference table normalizes the schema.
The Functional Dependency tab also has a Graphical subtab so that you can view information graphically. You can select a dependency and property from the lists to view graphical data.
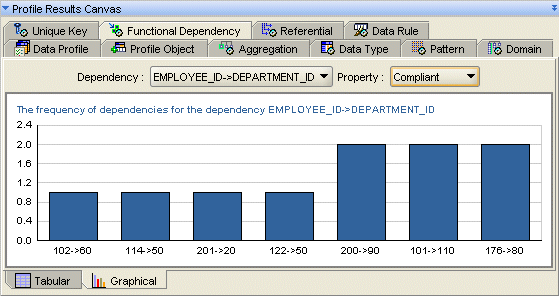
For example, in Figure 18-4, you select the dependency where EMPLOYEE_ID seems to determine DEPARTMENT_ID (EMPLOYEE_ID -> DEPARTMENT_ID). Oracle Warehouse Builder determines that most EMPLOYEE_ID values determine DEPARMENT_ID. By switching the Property to Non-Compliant, you can view the exceptions to this discovery.
Figure 18-4 Graphical Functional Dependency
The Referential tab displays information about foreign keys that were documented in the data dictionary, and relationships discovered during profiling. For each relationship, you can see the level of compliance. Information can be viewed from both the Tabular and Graphical subtabs. In addition, two other subtabs are available only in the Referential tab: Joins and Redundant Columns.
Table 18-9 describes the various measurement results available in the Referential tab.
Table 18-9 Referential Results
| Measurement | Description |
|---|---|
|
Relationship |
Name of the relationship |
|
Type |
Type of relationship. The possible values are Row Relationship and Foreign Key. |
|
Documented |
Indicates if a foreign key exists on the column in the data dictionary Yes indicates that a foreign key on the column exists in the data dictionary. No indicates that the foreign key was discovered because of data profiling. |
|
Discovered |
From analyzing the column values, data profiling determines whether a foreign key should be created on the column represented by Local Attribute(s). |
|
Local Attribute(s) |
Name of the attribute in the source object |
|
Remote Key |
Name of the key in the referenced object to which the local attribute refers |
|
Remote Attribute(s) |
Name of the attributes in the referenced object |
|
Remote Relation |
Name of the object that the source object references |
|
Remote Module |
Name of the module that contains the referenced object |
|
Cardinality Range |
Range of the cardinality between two attributes. For example, the Data profiling finds a row relationship between the |
|
# Orphans |
Number of orphan rows in the source object |
|
% Compliant |
Percentage of values that are compliant with the discovered dependency |
|
Six Sigma |
Number of null values (defects) to the total number of rows in the table (opportunities) |
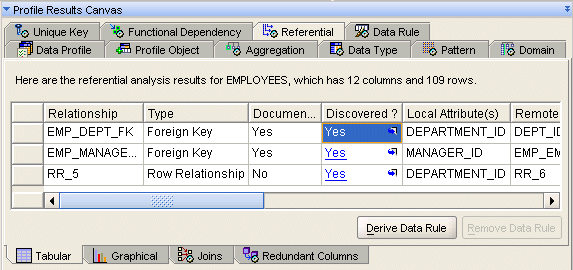
For example, you are analyzing two tables for referential relationships: the Employees table and the Departments table. Using the Referential data profiling results shown in Figure 18-5, you discover that the DEPARTMENT_ID column in the Employees table is related to DEPARTMENT_ID column in the Departments table 98% of the time. You can then click the hyperlinked Yes in the Discovered column to view the rows that did not follows the discovered foreign key relationship.
You can also select the Graphical subtab to view information graphically. This view is effective for viewing noncompliant records, such as orphans. To use the Graphical subtab, make a selection from the Reference and Property lists.
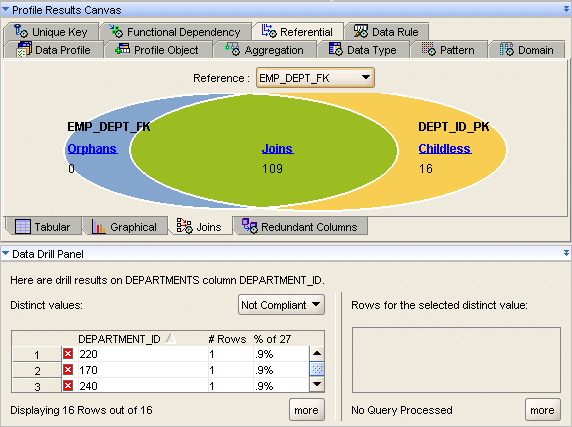
The Joins subtab displays a join analysis on the reference selected in the Reference list. The results show the relative size and exact counts of the three possible outcomes for referential relationships: joins, orphans, and childless objects.
For example, both the EMPLOYEES and DEPARTMENTS tables contain a DEPARTMENT_ID column. There is a one-to-many relationship between the DEPARTMENT_ID column in the DEPARTMENTS table and the DEPARTMENT_ID column in the EMPLOYEES table. The Joins represent the values that have values in both tables. Orphans represent values that are only present in the EMPLOYEES table and not the DEPARTMENTS table. And Childless values are present in the DEPARTMENTS table and not the EMPLOYEES table. You can drill into values on the diagram to view more details in the Data Drill panel.
Figure 18-6 displays the Joins subtab of the Referential tab.
The Redundant Columns subtab displays information about columns in the child table that are also contained in the primary table. Redundant column results are only available when perfectly unique columns are found during profiling.
For example, consider two tables EMP and DEPT, shown in Table 18-10 and Table 18-11, having the following foreign key relationship: EMP.DEPTNO (fk) = DEPT.DEPTNO (uk).
| Employee Number | Dept. No | Location |
|---|---|---|
|
100 |
1 |
CA |
|
200 |
2 |
NY |
|
300 |
3 |
MN |
|
400 |
1 |
CA |
|
500 |
1 |
CA |
In this example, the Location column in the EMP table is a redundant column, because you can get the same information from the join.
The Data Rule tab displays the data rules that are defined because of data profiling for the table selected in the object tree. The details for each data rule include the following:
Rule Name: Represents the name of the data rule.
Rule Type: Provides a brief description about the type of data rule.
Origin: Represents the origin of the data rule. For example, a value of Derived indicates that the data rule is derived.
% Compliant: Percent of rows that follows the data rule.
# Defects: Number of rows that do not follows the data rule.
The data rules on this tab reflect the active data rules in the Data Rule panel. You do not directly create data rules on this tab.
Attribute sets enable you to restrict a data profiling operation to a subset of columns from a table, view, or materialized view.
Reasons to use an attribute set include:
You can decrease profiling time by excluding columns for which you do not need profiling results.
Data profiling can only profile up to 165 columns from a table, view, or materialized view at a time. You can use an attribute set to select a set of 165 or fewer columns to profile from the object.
Data profiling using attribute sets, consists of the following high-level steps:
Performing data profiling
See "Profiling Data" for more information about profiling data.
Reviewing data profiling results
See "Viewing Profile Results" for more information about viewing profiling results.
Use the following steps to define an attribute set in a table, view, or materialized view.
In the Projects Navigator, double-click the table, view, or materialized view.
The editor for the selected object is opened.
Select the Attribute Sets tab.
In the Attribute Sets section, click a blank area in the Name column, enter the name of the attribute set you want to create, and press the Enter key.
Select the name of the attribute set created in Step 3.
The Attributes of the selected attribute set section displays the attributes in the data object.
Select Include for all the attributes included in the attribute set.
Save your changes by clicking Save on the toolbar.
In the Projects Navigator, right-click the Data Profiles node and select New Data Profile.
The Welcome page of the Create Data Profile Wizard is displayed.
On the Welcome page, click Next.
On the Name and Description page, enter a name and an optional description for the data profile. Click Next.
On the Select Objects page, select the data object to profile and use the shuttle arrows to move the data object to the Selected list.
When the selected data object contains attribute sets, the Choose Attribute Set dialog box is displayed.
On the Choose Attribute Set dialog box, select the attribute set to profile and click OK.
On the Select Objects page, click Next.
On the Summary page, review the options you chose on the previous wizard pages and click Finish.
The data profile is created and added to the navigator tree.
Once you create a data profile, you can use the Data Profile Editor to modify its definition. You can either modify profile settings or add to and remove from a data profile. To add objects, you can use either the menu bar options or the Select Objects tab of the Edit Data Profile dialog box.
To edit a data profile:
In the Projects Navigator, right-click the data profile and select Open.
The Data Profile Editor is displayed.
From the Edit menu, select Properties.
The Edit Data Profile dialog box is displayed.
On the Edit Data Profile dialog box, edit any of the following properties of the data profile and click OK.
To modify the name or description of the data profile, on the Name tab, select the name or description and enter the new value.
To add or remove objects, on the Select Objects tab, use the arrows to add objects to or remove objects from the data profile.
To change the location that is used as the data profiling staging area, use the Data Locations tab.
Use the arrows to move the new location to the Selected Locations section. Ensure that you select New Configuration Default to set this location as the default profiling location for the data profile.
Note:
If you modify the profiling location after you have performed data profiling, the previous profiling results are lost.To add data objects to a data profile:
Right-click the data profile in the Projects Navigator and select Open.
The Data Profile Editor is displayed.
From the Profile menu, select Add.
The Add Profile Tables dialog box is displayed.
On the Add Profile Tables dialog box, select the objects to add to the data profile. Use the arrows to move them to the Selected section.
You can select multiple objects by holding down the Ctrl key and selecting objects.
Data profiling is a processor and I/O intensive process, and the execution time for profiling ranges from a few minutes to a few days. You can achieve the best possible data profiling performance by ensuring that the following conditions are satisfied:
Your database is set up correctly for data profiling.
The appropriate data profiling configuration parameters are used when you perform data profiling.
You can configure a data profile to optimize data profiling results. Use the configuration parameters to configure a data profile.
See Also:
"Configuring Data Profiles" for details about configuring data profiles and the configuration parameters that you can set.Use the following guidelines to make your data profiling process faster:
Perform only the types of analysis that you require.
If you know that certain types of analysis are not required for the objects that you are profiling, use the configuration parameters to turn off these types of data profiling.
Limit the amount of data profiled.
Use the WHERE clause and Sample Rate configuration parameters.
If the source data for profiling is stored in an Oracle Database, it is recommended that the source schema should be located on the same database instance as the profile workspace. You can do this by installing the profiling workspace into the same Oracle Database instance as the source schema location. This avoids using a database link to move data from source to profiling workspace.
To ensure good data profiling performance, the computer that runs Oracle Database must have certain hardware capabilities. In addition, you must optimize the Oracle Database instance on which you are performing data profiling.
For efficient data profiling, consider the following resources:
The computer that runs Oracle Database needs multiple processors. Data profiling has been designed and tuned to take maximum advantage of the parallelism provided by Oracle Database. While profiling large tables (more than 10 million rows), it is highly recommended that you use a multiple processor computer.
Hints are used in queries required to perform data profiling. It picks up the degree of parallelism from the initialization parameter file of the Oracle Database. The default initialization parameter file contains parameters that take advantage of parallelism.
It is important that you ensure a high memory hit ratio during data profiling. You can ensure this by assigning a larger size of the System Global Area. Oracle recommends that the size of the System Global Area be at least 500 megabytes (MB). If possible, configure it to 2 gigabytes (GB) or 3 GB.
For advanced database users, Oracle recommends that you observe the buffer cache hit ratio and library cache hit ratio. Set the buffer cache hit ratio to higher than 95% and the library cache hit ratio to higher than 99%.
The capabilities of the I/O system have a direct impact on the data profiling performance. Data profiling processing frequently performs full table scans and massive joins. Because today's CPUs can easily outdrive the I/O system, you must carefully design and configure the I/O subsystem. Consider the following considerations that aid better I/O performance:
You need a large number of disk spindles to support uninterrupted CPU and I/O cooperation. If you have only a few disks, then the I/O system is not geared toward a high degree of parallel processing. It is recommended to have a minimum of two disks for each CPU.
Configure the disks. Oracle recommends that you create logical stripe volumes on the existing disks, each striping across all available disks. Use the following formula to calculate the stripe width:
MAX(1,DB_FILE_MULTIBLOCK_READ_COUNT/number_of_disks) X DB_BLOCK_SIZE
Here, DB_FILE_MULTIBLOCK_SIZE and DB_BLOCK_SIZE are parameters that you set in your database initialization parameter file. You can also use a stripe width that is a multiple of the value returned by the formula.
To create and maintain logical volumes, you need volume management software such as Veritas Volume Manager or Sun Storage Manager. If you are using Oracle Database 10g or a later and you do not have any volume management software, then you can use the Automatic Storage Management feature of Oracle Database to spread the workload to disks.
Create different stripe volumes for different tablespaces. It is possible that some tablespaces occupy the same set of disks.
For data profiling, the USERS and the TEMP tablespaces are normally used at the same time. Consider placing these tablespaces on separate disks to reduce I/O contention.
Data Watch and Repair (DWR) is a profiling and correction solution designed to assist data governance in Oracle's Master Data Management (MDM) solutions. MDM applications must provide a single consolidated view of data. You must first clean up a system's master data before they can share it with multiple connected entities.
Oracle Warehouse Builder provides data profiling and data correction functionality that enables MDM applications to cleanse and consolidate data. You can use DWR for the following MDM applications:
Customer Data Hub (CDH)
Product Information Management (PIM)
Universal Customer Master (UCH)
Data Watch and Repair (DWR) enables you to analyze, cleanse, and consolidates data stored in MDM databases using the following:
Data profiling
Data profiling data analysis method that enables you to detect and measure defects in your source data.
For more information about data profiling, see "Overview of Data Profiling".
Data rules
Data rules are help ensure data quality by determining the legal data and relationships in the source data. You can import MDM-specific data rules, define your own data rules before you perform data profiling, or derive data rules based on the data profiling results.
For more information about data rules, see "Overview of Data Rules".
Data correction
Data correction enables you to correct any inconsistencies, redundancies, and inaccuracies in both the data and metadata. You can automatically create correction mappings to cleanse source data.
For more information about data correction, see "Overview of Data Rules in ETL and Automatic Data Correction".
DWR enables you to measure crucial business rules regularly. As you discover inconsistencies in the data, you can define and apply new data rules to ensure data quality.
Oracle Warehouse Builder provides a set of data rules that are commonly used in MDM applications. These include the following customer data rules that can be used in both Customer Data Hub (CDH) and Universal customer Master (UCM) applications:
Attribute Completeness
Contact Completeness
Data Type
Data Domain
Restricted Values
Unique Key Discovery
Full Name Standardization
Common Pattern
Name Capitalization
Extended Phone Numbers
International Phone Numbers
No Access List by Name Only
No Access List by Name or SSN
No Email List
For more details about these data rules, refer to the Oracle Watch and Repair for MDM User's Guide.
To use Data Watch and Repair (DWR), you need the following software:
Oracle Database 11g Release 1 (11.1) or later
Oracle Warehouse Builder 11g Release 1 (11.1.0.7) or later
One or more of the following Master Data Management (MDM) applications: Customer Data Hub (CDH), Product Information Management (PIM), or Universal Customer Master (UCH)
For MDM applications that run on an Oracle Database, you can directly use DWR. However, for MDM applications that do not run on an Oracle Database, you must set up a gateway with the third-party database.
Use the following steps to perform Data Watch and Repair (DWR).
Create a location corresponding to the Master Data Management (MDM) application database.
Use the Oracle node under the Databases node in the Locations Navigator. Specify the details of the MDM database such as the user name, password, host name, port, service name, and database version.
In the Projects Navigator, expand the Applications node to display the nodes for the MDM applications.
The CDH node represents Customer Data Hub application, the PIM node to the Product Information Management application, and UCM to Universal Customer Master.
Right-click the node corresponding to the type of MDM application for which you want to perform DWR and select Create CMI Module.
Use the Create Module Wizard to create a module that stores your MDM metadata definitions. Ensure that you select the location you created in step 1 while creating the module.
Import metadata from your MDM application into the module created in step 3. Right-click the module and select Import.
The Metadata Import Wizard is displayed that enables you to import MDM metadata.
Import data rules specific to MDM as described in "Importing MDM Data Rules".
Apply data rules to the MDM application tables as described in "Applying Data Rules to Data Objects".
Applying data rules to tables enables you to determine if your table data complies with the business rules defined using data rules. You can apply data rules you imported in step 5 or other data rules that you created.For more information about creating data rules, see "Creating Data Rules Using the Create Data Rule Wizard".
Create a data profile that includes all tables from the MDM application to profile.
For more information about creating data profiles, see "Creating Data Profiles".
Perform data profiling on the MDM application objects as described in "Profiling Data".
View the data profiling results as described in "Viewing Profile Results".
(Optional) Derive data rules based on data profiling results as described in "Deriving Data Rules From Data Profiling Results".
Data rules derived from data profiling results are automatically applied to the table.
Create correction mappings as described in "Steps to Create Correction Objects".
Correct data and metadata using the correction mappings generated by Oracle Warehouse Builder as described in "Deploying Schema Corrections" and "Deploying Correction Mappings".
Write the corrected data, stored in the correction objects created in step 12, to the MDM application as described in "Writing Corrected Data and Metadata to the MDM Application".
Data rules required for Customer Data Hub (CDH) and Universal Customer Master (UCM) applications are provided in the OWB_HOME/owb/misc/dwr/customer_data_rules.mdl file. To import these data rules, from the File menu, select Import, then Oracle Warehouse Builder Metadata. In the Metadata Import dialog box, select the customer_data_rules.mdl and click OK. For more information about using the Metadata Import dialog, click Help on this page.
The imported data rules are listed in the Globals Navigator, in the MDM Customer Data Rules node under the Public Data Rules node.
The cleansed and corrected data is contained in the correction objects created because of data profiling.
To be more efficient, you can write back only those rows that must be corrected. You can achieve this by modifying the generated correction mapping. Delete the branch that passes through the compliant rows unchanged (this is the branch that contains the minus filter and the minus set operators). Retain only the corrected rows processing branch in the correction mapping.
Use the following steps to write corrected data to the source MDM application:
Create a mapping using the Mapping Editor.
Drag and drop the corrected table on to the Mapping Editor. This represents the source table.
For UCM, drag and drop the interface table that corresponds to the base table with which you are working.
Use the MDM application tools and documentation to determine the base table for a particular interface table.
Map the columns from the corrected table to the interface table.
Deploy and run the mapping to write corrected data to the source MDM application.
Update the base table with changes made to the interface table. You can use Siebel Enterprise Integration Manager (EIM). EIM can be run using the command line or from a Graphical User Interface (GUI).
For more details about using the EIM, see Siebel Enterprise Integration Manager Administration Guide.
|
Copyright © 2000, 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|