| Oracle® Data Mining Concepts 11g Release 2 (11.2) Part Number E16808-06 |
|
|
PDF · Mobi · ePub |
| Oracle® Data Mining Concepts 11g Release 2 (11.2) Part Number E16808-06 |
|
|
PDF · Mobi · ePub |
This chapter presents an overview of Oracle Data Mining predictive analytics, an automated form of predictive data mining.
See Also:
Oracle Data Mining Administrator's Guide for installation instructions
Oracle Database PL/SQL Packages and Types Reference for predictive analytics syntax in PL/SQL
This chapter includes the following sections:
Predictive Analytics is a technology that captures data mining processes in simple routines. Sometimes called "one-click data mining," predictive analytics simplifies and automates the data mining process.
Predictive analytics develops profiles, discovers the factors that lead to certain outcomes, predicts the most likely outcomes, and identifies a degree of confidence in the predictions.
Predictive analytics uses data mining technology, but knowledge of data mining is not needed to use predictive analytics.
You can use predictive analytics simply by specifying an operation to perform on your data. You do not need to create or use mining models or understand the mining functions and algorithms summarized in Chapter 2 of this manual.
The predictive analytics routines analyze the input data and create mining models. These models are trained and tested and then used to generate the results returned to the user. The models and supporting objects are not preserved after the operation completes.
When you use data mining technology directly, you create a model or use a model created by someone else. Usually, you apply the model to new data (different from the data used to train and test the model). Predictive analytics routines apply the model to the same data used for training and testing.
See Also:
"Behind the Scenes" to gain insight into the inner workings of Oracle predictive analyticOracle Data Mining predictive analytics operations are described in Table 3-1.
Table 3-1 Oracle Predictive Analytics Operations
| Operation | Description |
|---|---|
|
|
Explains how the individual attributes affect the variation of values in a target column |
|
|
For each case, predicts the values in a target column |
|
|
Creates a set of rules for cases that imply the same target value |
The Oracle Spreadsheet Add-In for Predictive Analytics provides predictive analytics operations within a Microsoft Excel spreadsheet. You can analyze Excel data or data that resides in an Oracle database.
Figure 3-1 shows the EXPLAIN operation using Microsoft Excel 7.0. EXPLAIN shows the predictors of a given target ranked in descending order of importance. In this example, RELATIONSHIP is the most important predictor, and MARTIAL STATUS is the second most important predictor .
Figure 3-1 EXPLAIN in Oracle Spreadsheet Add-In for Predictive Analytics
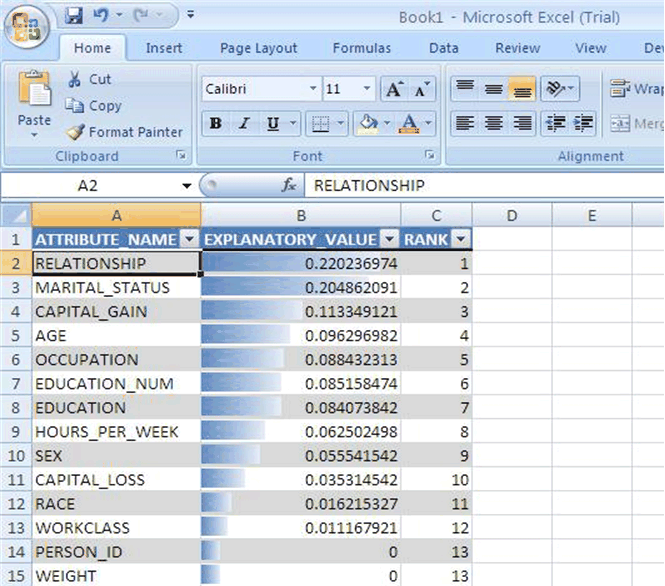
Figure 3-2 shows the PREDICT operation for a binary target. PREDICT shows the actual and predicted classification for each case. It includes the probability of each prediction and the overall predictive confidence for the data set.
Figure 3-2 PREDICT in Oracle Spreadsheet Add-In for Predictive Analytics
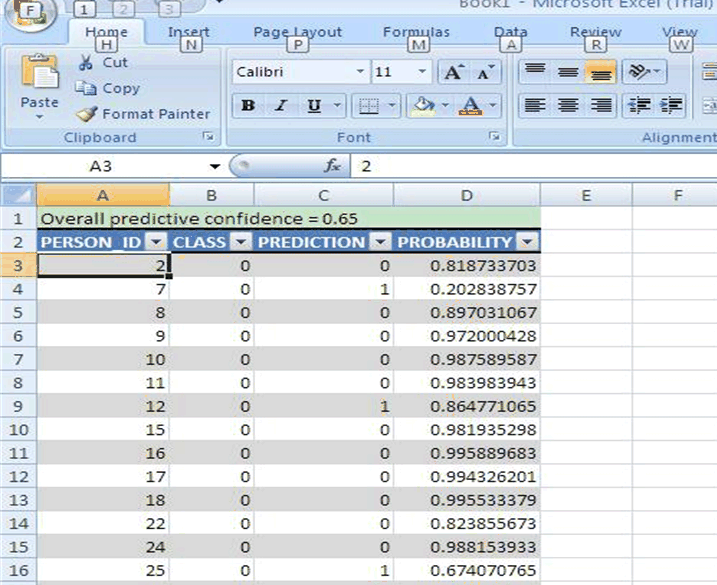
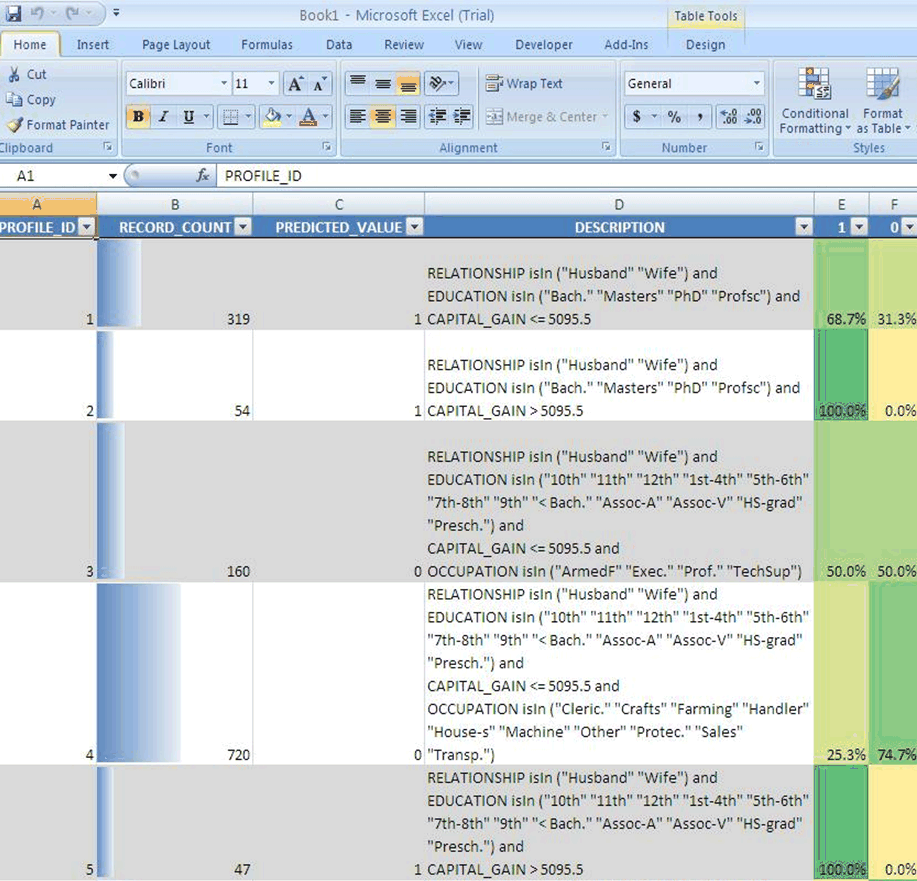
Figure 3-3 shows the PROFILE operation. This example shows five profiles for a binary classification problem. Each profile includes a rule, the number of cases to which it applies, and a score distribution. Profile 1 describes 319 cases. Its members are husbands or wives with bachelors, masters, Ph.D., or professional degrees; they have capital gains <= 5095.5. The probability of a positive prediction for this group is 68.7%; the probability of a negative prediction is 31.3%.
Figure 3-3 PROFILE in Oracle Spreadsheet Add-In for Predictive Analytics
You can download the latest version of the Spreadsheet Add-In from the Oracle Technology Network.
Oracle Data Mining implements predictive analytics in the DBMS_PREDICTIVE_ANALYTICS PL/SQL package. The following SQL DESCRIBE statement shows the predictive analytics procedures with their parameters.
SQL> describe dbms_predictive_analytics PROCEDURE EXPLAIN Argument Name Type In/Out Default? ------------------------------ ----------------------- ------ -------- DATA_TABLE_NAME VARCHAR2 IN EXPLAIN_COLUMN_NAME VARCHAR2 IN RESULT_TABLE_NAME VARCHAR2 IN DATA_SCHEMA_NAME VARCHAR2 IN DEFAULT PROCEDURE PREDICT Argument Name Type In/Out Default? ------------------------------ ----------------------- ------ -------- ACCURACY NUMBER OUT DATA_TABLE_NAME VARCHAR2 IN CASE_ID_COLUMN_NAME VARCHAR2 IN TARGET_COLUMN_NAME VARCHAR2 IN RESULT_TABLE_NAME VARCHAR2 IN DATA_SCHEMA_NAME VARCHAR2 IN DEFAULT PROCEDURE PROFILE Argument Name Type In/Out Default? ------------------------------ ----------------------- ------ -------- DATA_TABLE_NAME VARCHAR2 IN TARGET_COLUMN_NAME VARCHAR2 IN RESULT_TABLE_NAME VARCHAR2 IN DATA_SCHEMA_NAME VARCHAR2 IN DEFAULT
Example 3-1 shows how a simple PREDICT operation can be used to find the customers most likely to increase spending if given an affinity card.
The customer data, including current affinity card usage and other information such as gender, education, age, and household size, is stored in a view called MINING_DATA_APPLY_V. The results of the PREDICT operation are written to a table named p_result_tbl.
The PREDICT operation calculates both the prediction and the accuracy of the prediction. Accuracy, also known as predictive confidence, is a measure of the improvement over predictions that would be generated by a naive model. In the case of classification, a naive model would always guess the most common class. In Example 3-1, the improvement is almost 50%.
Example 3-1 Predict Customers Most Likely to Increase Spending with an Affinity Card
DECLARE
p_accuracy NUMBER(10,9);
BEGIN
DBMS_PREDICTIVE_ANALYTICS.PREDICT(
accuracy => p_accuracy,
data_table_name =>'mining_data_apply_v',
case_id_column_name =>'cust_id',
target_column_name =>'affinity_card',
result_table_name =>'p_result_tbl');
DBMS_OUTPUT.PUT_LINE('Accuracy: ' || p_accuracy);
END;
/
Accuracy: .492433267
The following query returns the gender and average age of customers most likely to respond favorably to an affinity card.
SELECT cust_gender, COUNT(*) as cnt, ROUND(AVG(age)) as avg_age
FROM mining_data_apply_v a, p_result_tbl b
WHERE a.cust_id = b.cust_id
AND b.prediction = 1
GROUP BY a.cust_gender
ORDER BY a.cust_gender;
C CNT AVG_AGE
- ---------- ----------
F 90 45
M 443 45
This section provides some high-level information about the inner workings of Oracle predictive analytics. If you know something about data mining, you will find this information to be straight-forward and easy to understand. If you are unfamiliar with data mining, you can skip this section. You do not need to know this information to use predictive analytics.
See Also:
Chapter 2 for an overview of model functions and algorithmsEXPLAIN creates an attribute importance model. Attribute importance uses the Minimum Description Length algorithm to determine the relative importance of attributes in predicting a target value. EXPLAIN returns a list of attributes ranked in relative order of their impact on the prediction. This information is derived from the model details for the attribute importance model.
Attribute importance models are not scored against new data. They simply return information (model details) about the data you provide.
Attribute importance is described in "Feature Selection".
PREDICT creates a Support Vector Machine (SVM) model for classification or regression.
PREDICT creates a Receiver Operating Characteristic (ROC) curve to analyze the per-case accuracy of the predictions. PREDICT optimizes the probability threshold for binary classification models. The probability threshold is the probability that the model uses to make a positive prediction. The default is 50%.
PREDICT returns a value indicating the accuracy, or predictive confidence, of the prediction. The accuracy is the improvement gained over a naive prediction. For a categorical target, a naive prediction would be the most common class, for a numerical target it would be the mean. For example, if a categorical target can have values small, medium, or large, and small is predicted more often than medium or large, a naive model would return small for all cases. Predictive analytics uses the accuracy of a naive model as the baseline accuracy.
The accuracy metric returned by PREDICT is a measure of improved maximum average accuracy versus a naive model's maximum average accuracy. Maximum average accuracy is the average per-class accuracy achieved at a specific probability threshold that is greater than the accuracy achieved at all other possible thresholds.
SVM is described in Chapter 18.
PROFILE creates a Decision Tree model to identify the characteristic of the attributes that predict a common target. For example, if the data has a categorical target with values small, medium, or large, PROFILE would describe how certain attributes typically predict each size.
The Decision Tree algorithm creates rules that describe the decisions that affect the prediction. The rules, expressed in XML as if-then-else statements, are returned in the model details. PROFILE returns XML that is derived from the model details generated by the algorithm.
Decision Tree is described in Chapter 11.
|
Copyright © 2005, 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|