| Oracle® In-Memory Database Cache Introduction 11g Release 2 (11.2.2) Part Number E21631-03 |
|
|
PDF · Mobi · ePub |
| Oracle® In-Memory Database Cache Introduction 11g Release 2 (11.2.2) Part Number E21631-03 |
|
|
PDF · Mobi · ePub |
TimesTen and IMDB Cache ensure the availability, durability, and integrity of data through the following mechanisms:
The TimesTen or IMDB Cache transaction log is used for the following purposes:
Redo transactions if a system failure occurs
Undo transactions that are rolled back
Replicate changes to other TimesTen databases or IMDB Cache databases
Replicate changes to an Oracle database
Enable applications to monitor changes to tables through the XLA interface
The transaction log is stored in files on disk. The end of the transaction log resides in an in-memory buffer.
TimesTen and IMDB Cache write the contents of the in-memory log buffer to disk at every durable commit, at every checkpoint, and at other times defined by the implementation. Applications that cannot tolerate the loss of any committed transactions if a failure occurs should request a durable commit for every transaction that is not read-only. They can do so by setting the DurableCommits general connection attribute to 1 when they connect to the database.
Applications that can tolerate the loss of some recently committed transactions can significantly improve their performance by committing some or all of their transactions nondurably. To do so, they set the DurableCommits general connection attribute to 0 (the default) and typically request explicit durable commits either at regular time intervals or at specific points in their application logic. To request a durable commit, applications call the ttDurableCommit built-in procedure.
Transaction log files are kept until TimesTen or the IMDB Cache declares them to be purgeable. A transaction log file cannot be purged until all of the following actions have been completed:
All transactions writing log records to the transaction log file (or a previous transaction log file) have committed or rolled back.
All changes recorded in the transaction log file have been written to the checkpoint files on disk.
All changes recorded in the transaction log file have been replicated (if replication is used).
All changes recorded in the transaction log file have been propagated to the Oracle database if the IMDB Cache has been configured for that behavior.
All changes recorded in transaction log files have been reported to the XLA applications (if XLA is used).
ODBC provides an autocommit mode that forces a commit after each statement. By default, autocommit is enabled so that an implicit commit is issued immediately after a statement executes successfully. TimesTen recommends that you turn autocommit off so that commits are intentional.
TimesTen issues an implicit commit before and after any data definition language (DDL) statement by default. This behavior is controlled by the DDLCommitBehavior general connection attribute. You can use the attribute to specify instead that DDL statements be executed as part of the current transaction and committed or rolled back along with the rest of the transaction.
Checkpoints are used to keep a snapshot of the database. If a system failure occurs, TimesTen and the IMDB Cache can use a checkpoint file with transaction log files to restore a database to its last transactionally consistent state.
Only the data that has changed since the last checkpoint operation is written to the checkpoint file. The checkpoint operation scans the database for blocks that have changed since the last checkpoint. It then updates the checkpoint file with the changes and removes any transaction log files that are no longer needed.
TimesTen and IMDB Cache provide two kinds of checkpoints:
TimesTen and IMDB Cache create nonblocking checkpoints automatically.
TimesTen and IMDB Cache initiate nonblocking checkpoints in the background automatically. Nonblocking checkpoints are also known as fuzzy checkpoints. The frequency of these checkpoints can be adjusted by the application. Nonblocking checkpoints do not require any locks on the database, so multiple applications can asynchronously commit or roll back transactions on the same database while the checkpoint operation is in progress.
An application can call the ttCkptBlocking built-in procedure to initiate a blocking checkpoint in order to construct a transaction-consistent checkpoint. While a blocking checkpoint operation is in progress, any other new transactions are put in a queue behind the checkpointing transaction. If any transaction is long-running, it may cause many other transactions to be held up. No log is needed to recover from a blocking checkpoint because the checkpoint record contains the information needed to recover.
If a database becomes invalid or corrupted by a system or process failure, every connection to the database is invalidated. When an application reconnects to a failed database, the subdaemon allocates a new memory segment for the database and recovers its data from the checkpoint and transaction log files.
During recovery, the latest checkpoint file is read into memory. All transactions that have been committed since the last checkpoint and whose log records are on disk are rolled forward from the appropriate transaction log files. Note that such transactions include all transactions that were committed durably as well as all transactions whose log records aged out of the in-memory log buffer. Uncommitted or rolled-back transactions are not recovered.
For applications that require uninterrupted access to TimesTen data in the event of failures, see "Replication".
The fundamental motivation behind replication is to make data highly available to applications with minimal performance impact. In addition to its role in failure recovery, replication is also useful for distributing application workloads across multiple databases for maximum performance and for facilitating online upgrades and maintenance.
Replication is the process of copying data from a master database to a subscriber database. Replication at each master and subscriber database is controlled by replication agents that communicate through TCP/IP stream sockets. The replication agent on the master database reads the records from the transaction log for the master database. It forwards changes to replicated elements to the replication agent on the subscriber database. The replication agent on the subscriber then applies the updates to its database. If the subscriber agent is not running when the updates are forwarded by the master, the master retains the updates in its transaction log until they can be applied at the subscriber.
You can increase replication throughput by configuring parallel replication at database creation time. Parallel replication is enabled by default. You configure the number of threads for applying updates to subscribers. The updates are transmitted in commit order.
TimesTen recommends the active standby pair configuration for highest availability. It is the only replication configuration that you can use for replicating IMDB Cache.
The rest of this section includes the following topics:
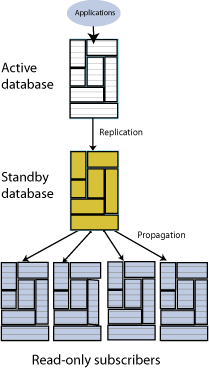
An active standby pair includes an active database, a standby database, optional read-only subscriber databases, and the tables and cache groups that comprise the databases. Figure 6-1 shows an active standby pair.
In an active standby pair, two databases are defined as masters. One is an active database, and the other is a standby database. The active database is updated directly. The standby database cannot be updated directly. It receives the updates from the active database and propagates the changes to read-only subscribers. This arrangement ensures that the standby database is always ahead of the read-only subscribers and enables rapid failover to the standby database if the active database fails.
Only one of the master databases can function as an active database at a specific time. If the active database fails, the role of the standby database must be changed to active before recovering the failed database as a standby database. The replication agent must be started on the new standby database.
If the standby database fails, the active database replicates changes directly to the read-only subscribers. After the standby database has recovered, it contacts the active database to receive any updates that have been sent to the read-only subscribers while the standby was down or was recovering. When the active and the standby databases have been synchronized, then the standby resumes propagating changes to the subscribers.
Active standby replication can be used with IMDB Cache to achieve cross-tier high availability. Active standby replication is available for both read-only and asynchronous writethrough cache groups. When used with read-only cache groups, updates are sent from the Oracle database to the active database. Thus the Oracle database plays the role of the application in this configuration. When used with asynchronous writethrough cache groups, the standby database propagates updates that it receives from the active database to the Oracle database. In this scenario, the Oracle database plays the role of one of the read-only subscribers.
An active standby pair that replicates one of these types of cache groups can perform failover and recovery automatically with minimal chance of data loss. See "Active standby pairs with cache groups" in Oracle TimesTen In-Memory Database Replication Guide.
TimesTen replication architecture is flexible enough to achieve balance between performance and availability. In general, replication can be configured to be unidirectional from a master to one or more subscribers, or bidirectional between two or more databases that serve as both master and subscriber.
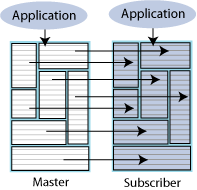
Figure 6-2 shows a unidirectional replication scheme. The application is configured on both hosts so that the subscriber is ready to take over if the master host fails. While the master is up, updates from the application to the master database are replicated to the subscriber database. The application on the subscriber host does not execute any updates against the subscriber database, but may read from that database. If the master fails, the application on the subscriber host takes over the update function and starts updating the subscriber database.
Figure 6-2 Unidirectional replication scheme
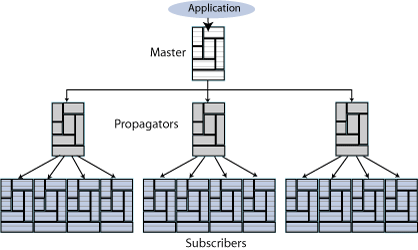
Replication can also be used to copy updates from a master database to many subscriber databases. Figure 6-3 shows a replication scheme with multiple subscribers.
Figure 6-3 Unidirectional replication to multiple subscribers
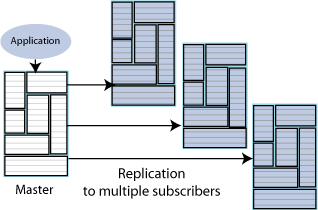
Figure 6-4 shows a propagation configuration. One master propagates updates to three subscribers. The subscribers are also masters that propagate updates to additional subscribers.
Bidirectional replication schemes are used for load balancing. The workload can be split between two bidirectionally replicated databases. There are two basic types of load-balancing configurations:
Split workload where each database bidirectionally replicates a portion of its data to the other database. Figure 6-5 shows a split workload configuration.
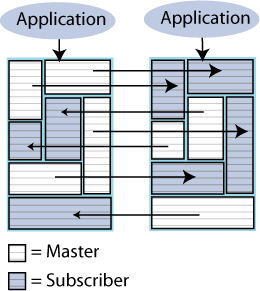
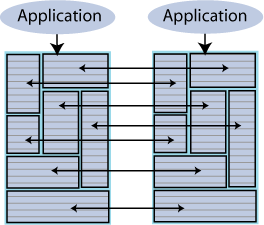
Distributed workload where user access is distributed across duplicate application/database combinations that replicate updates to each other. In a distributed workload configuration, the application has the responsibility to divide the work between the two systems so that replication collisions do not occur. If collisions do occur, TimesTen has a timestamp-based collision detection and resolution capability. Figure 6-6 shows a distributed workload configuration.
Figure 6-6 Distributed workload replication
TimesTen replication is by default an asynchronous mechanism. When using asynchronous replication, an application updates the master database and continues working without waiting for the updates to be received by the subscribers. The master and subscriber databases have internal mechanisms to confirm that the updates have been successfully received and committed by the subscriber. These mechanisms ensure that updates are applied at a subscriber only once, but they are invisible to the application.
Asynchronous replication provides maximum performance, but the application is completely decoupled from the receipt process of the replicated elements on the subscriber. TimesTen also provides two return service options for applications that need higher levels of confidence that the replicated data is consistent between the master and subscriber databases:
The return receipt service synchronizes the application with the replication mechanism by blocking the application until replication confirms that the update has been received by the subscriber replication agent.
The return twosafe service enables fully synchronous replication by blocking the application until replication confirms that the update has been both received and committed on the subscriber.
Note:
Do not use return twosafe service in a distributed workload configuration. This can produce deadlocks.Applications that use the return services trade some performance to ensure higher levels of consistency and reduce the risk of transaction loss between the master and subscriber databases. In the event of a master failure, the application has a higher degree of confidence that a transaction committed at the master persists in the subscribing database. Return receipt replication has less performance impact than return twosafe at the expense of potential loss of transactions.
For replication to make data highly available to applications with minimal performance impact, there must be a way to shift applications from the failed database to its surviving backup as seamlessly as possible.
You can use Oracle Clusterware to manage failures automatically in systems with active standby pairs. Other kinds of replication schemes can be managed with custom and third-party cluster managers. They detect failures, redirect users or applications from the failed database to either a standby database or a subscriber, and manage recovery of the failed database. The cluster manager or administrator can use TimesTen-provided utilities and functions to duplicate the surviving database and recover the failed database.
Subscriber failures generally have no impact on the applications connected to the master databases and can be recovered without disrupting user service. If a failure occurs on a master database, the cluster manager must redirect the application load to a standby database or a subscriber in order to continue service with no or minimal interruption.
You can configure automatic client failover for databases that have active standby pairs with client/server connections. This enables the client to fail over automatically to the server on which the standby database resides.
For more information about logging and checkpointing, see "Transaction Management and Recovery" in Oracle TimesTen In-Memory Database Operations Guide.
For more information about replication, see Oracle TimesTen In-Memory Database Replication Guide.
For more information about automatic client failover, see Oracle TimesTen In-Memory Database Operations Guide.
|
Copyright © 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|