| Oracle® Database Administrator's Guide 11g Release 2 (11.2) Part Number E25494-02 |
|
|
PDF · Mobi · ePub |
| Oracle® Database Administrator's Guide 11g Release 2 (11.2) Part Number E25494-02 |
|
|
PDF · Mobi · ePub |
To use the Scheduler, you create Scheduler objects. Schema objects define the what, when, and where for job scheduling. Scheduler objects enable a modular approach to managing tasks. One advantage of the modular approach is that objects can be reused when creating new tasks that are similar to existing tasks.
The principal Scheduler object is the job. A job defines the action to perform, the schedule for the action, and the location or locations where the action takes place. Most other scheduler objects are created to support jobs.
Note:
The Oracle Scheduler job replaces theDBMS_JOB package, which is still supported for backward compatibility. This chapter assumes that you are only using Scheduler jobs. If you are using both at once, or migrating from DBMS_JOB to Scheduler jobs, see Appendix A, "Support for DBMS_JOB in Oracle Database 11g Release 2."The Scheduler objects include:
Each of these objects is described in detail later in this section.
Because Scheduler objects belong to schemas, you can grant object privileges on them. Some Scheduler objects, including job classes, windows, and window groups, are always created in the SYS schema, even if the user is not SYS. All other objects are created in the user's own schema or in a designated schema.
See Also:
A program object (program) describes what is to be run by the Scheduler. A program includes:
An action: For example, the name of a stored procedure, the name of an executable found in the operating system file system (an "external executable"), or the text of a PL/SQL anonymous block.
A type: STORED_PROCEDURE, PLSQL_BLOCK, or EXTERNAL, where EXTERNAL indicates an external executable.
Number of arguments: The number of arguments that the stored procedure or external executable accepts.
A program is a separate entity from a job. A job runs at a certain time or because a certain event occurred, and invokes a certain program. You can create jobs that point to existing program objects, which means that different jobs can use the same program and run the program at different times and with different settings. With the right privileges, different users can use the same program without having to redefine it. Therefore, you can create program libraries, where users can select from a list of existing programs.
If a stored procedure or external executable referenced by the program accepts arguments, you define these arguments in a separate step after creating the program. You can optionally define a default value for each argument.
See Also:
"Jobs" for an overview of jobs
A schedule object (schedule) specifies when and how many times a job is run. Schedules can be shared by multiple jobs. For example, the end of a business quarter may be a common time frame for many jobs. Rather than defining an end-of-quarter schedule each time a new job is defined, job creators can point to a named schedule.
There are two types of schedules:
time schedules
With time schedules, you can schedule jobs to run immediately or at a later time. Time schedules include a start date and time, optional end date and time, and optional repeat interval.
event schedules
With event schedules, you can specify that a job executes when a certain event occurs, such as inventory falling below a threshold or a file arriving on a system. For more information on events, see "Using Events to Start Jobs".
See Also:
"Creating Schedules"A job object (job) is a collection of metadata that describes a user-defined task. It defines what must be executed (the action), when (the one-time or recurring schedule or a triggering event), where (the destinations), and with what credentials. A job has an owner, which is the schema in which it is created.
You define where a job runs by specifying a one or more destinations. Destinations are also Scheduler objects and are described later in this section. If you do not specify a destination, it is assumed that the job runs on the local database.
You specify the job action in one of the following ways:
By specifying as a job attribute the database program unit or external executable to be run. This is known as specifying the job action inline.
By specifying as a job attribute the name of an existing program object (program), that specifies the database program unit or external executable to be run. The job owner must have the EXECUTE privilege on the program or the EXECUTE ANY PROGRAM system privilege.
A job that runs a database program unit is known as a database job. A job that runs an external executable is known as an external job.
You specify the job schedule in one of the following ways:
By setting attributes of the job object to define start and end dates and a repeat interval, or to define an event that starts the job. This is known as specifying the schedule inline.
By specifying as a job attribute the name of an existing schedule object (schedule), which defines start and end dates and a repeat interval, or defines an event.
You specify the job destinations in one of the following ways:
By specifying as a job attribute a single named destination object. In this case, the job runs on one remote location.
By specifying as a job attribute a named destination group, which is equivalent to a list of remote locations. In this case, the job runs on all remote locations.
By not specifying a destination attribute, in which case the job runs locally. The job runs either of the following:
A database program unit on the local database (the database on which the job is created)
An external executable on the local host, depending on the job action type
You specify the job credentials in one of the following ways:
By specifying as a job attribute a named credential object, which contains either of the following:
A database user name and password (for database jobs)
A host operating system user name and password (for external jobs)
The job runs as the user named in the credential.
By allowing the credential attribute of the job to remain NULL, in which case a local database job runs as the job owner, and a local external job runs with default credentials. (See Table 28-1.) The job owner is the schema in which the job was created.
Jobs that run database program units at one or more remote locations are called remote database jobs. Jobs that run external executables at one or more remote locations are called remote external jobs.
After you create a job and enable it, the Scheduler automatically runs the job according to its schedule or when the specified event is detected. You can view the run status of job and its job log by querying data dictionary views. If a job runs on multiple destinations, you can query the status of the job at each destination.
A destination object (destination) defines a location for running a job.
There are two types of destinations:
External destination: Specifies a remote host name and IP address for running a remote external job.
Database destination: Specifies a remote database instance for running a remote database job.
Jobs that run external executables (external jobs) must specify external destinations, and jobs that run database program units (database jobs) must specify database destinations.
If you specify a destination when you create a job, the job runs on that destination. If you do not specify a destination, the job runs locally, on the system on which it is created.
You can also create a destination group, which consists of a list of destinations, and reference this destination group when creating a job. In this case, the job runs on all destinations in the group.
Note:
Destination groups can also include the keywordLOCAL as a group member, indicating that the job also runs on the local host or local database.See Also:
"Groups"No object privileges are required to use a destination created by another user.
The remote location specified in a destination object must have a Scheduler agent running, and the agent must be registered with the database creating the job. The Scheduler agent enables the local Scheduler to communicate with the remote host, start and stop jobs there, and return remote job status to the local database. For complete details, see "Creating Destinations".
You cannot explicitly create external destinations. They are created in your local database when you register a Scheduler agent with that database. The name assigned to the external destination is the name of the agent. You can configure an agent name after you install it, or you can accept the default agent name, which is the first part of the host name (before the first dot separator). For example, if you install an agent on the host dbhost1.us.example.com, the agent name defaults to DBHOST1.
You create database destinations with the DBMS_SCHEDULER.CREATE_DATABASE_DESTINATION procedure.
Note:
If you have multiple database instances running on the local host, you can run jobs on the other instances by creating database destinations for those instances. Thus, "remote" database instances do not necessarily have to reside on remote hosts. The local host must be running a Scheduler agent to support running remote database jobs on these additional instances.A file watcher object (file watcher) defines the location, name, and other properties of a file whose arrival on a system causes the Scheduler to start a job. You create a file watcher and then create any number of event-based jobs or event schedules that reference the file watcher. When the file watcher detects the arrival of the designated file, it raises a file arrival event. The job started by the file arrival event can retrieve the event message to learn about the newly arrived file.
A file watcher can watch for a file on the local system (the same host computer running Oracle Database) or a remote system, provided that the remote system is running the Scheduler agent.
To use file watchers, the database Java virtual machine (JVM) component must be installed.
See "About File Watchers" for more information.
A credential is a user name and password pair stored in a dedicated database object. A job uses a credential to authenticate itself with a database instance or the operating system so that it can run. You use credentials for:
Remote database jobs—The credential contains a database user name and password. The stored procedure or PL/SQL block specified in the remote database job runs as this database user.
External jobs (local or remote)—The credential contains a host operating system user name and password. The external executable of the job then runs with this user name and password.
File watchers—The credential contains a host operating system user name and password. The job that processes the file arrival event uses this user name and password to access the arrived file.
You can query the *_SCHEDULER_CREDENTIALS views to see a list of credentials in the database. Credential passwords are stored obfuscated, and are not displayed in the *_SCHEDULER_CREDENTIALS views.
See Also:
"Creating Credentials"Chains are the means by which you can implement dependency scheduling, in which job starts depend on the outcomes of one or more previous jobs. A chain consists of multiple steps that are combined using dependency rules. The dependency rules define the conditions that can be used to start or stop a step or the chain itself. Conditions can include the success, failure, or completion- or exit-codes of previous steps. Logical expressions, such as AND/OR, can be used in the conditions. In a sense, a chain resembles a decision tree, with many possible paths for selecting which tasks run and when.
In its simplest form, a chain consists of two or more Scheduler program objects (programs) that are linked together for a single, combined objective. An example of a chain might be "run program A followed by program B, and then run program C only if programs A and B complete successfully, otherwise wait an hour and then run program D."
As an example, you might want to create a chain to combine the different programs necessary for a successful financial transaction, such as validating and approving a loan application, and then funding the loan.
A Scheduler job can point to a chain instead of pointing to a single program object. The job then serves to start the chain. This job is referred to as the chain job. Multiple chain jobs can point to the same chain, and more than one of these jobs can run simultaneously, thereby creating multiple instances of the same chain, each at a different point of progress in the chain.
Each position within a chain is referred to as a step. Typically, after an initial set of chain steps has started, the execution of successive steps depends on the completion of one or more previous steps. Each step can point to one of the following:
A program object (program)
The program can run a database program unit (such as a stored procedure or PL/SQL anonymous block) or an external executable.
Another chain (a nested chain)
Chains can be nested to any level.
An event schedule, inline event, or file watcher
After starting a step that points to an event schedule or that has an inline event specification, the step waits until the specified event is raised. Likewise, a step that references a file watcher inline or that points to an event schedule that references a file watcher waits until the file arrival event is raised. For a file arrival event or any other type of event, when the event occurs, the step completes, and steps that are dependent on the event step can run. A common example of an event in a chain is a user intervention, such an approval or rejection.
Multiple steps in the chain can invoke the same program or nested chain.
For each step, you can specify either a database destination or an external destination on which the step should run. If a destination is not specified, the step runs on the originating (local) database or the local host. Each step in a chain can run on a different destination.
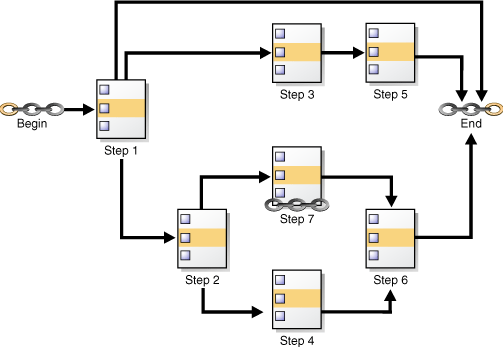
Figure 28-1 shows a chain with multiple branches. In this chain, rules could have been defined as follows:
If Step 1 completes successfully, start Step 2.
If Step 1 fails with error code 20100, start Step 3.
If Step 1 fails with any other error code, end the chain.
Additional rules would govern the running of steps 4, 5, 6, and 7.
While a job pointing to a chain is running, the current state of all steps of the running chain can be monitored. For every step, the Scheduler creates a step job with the same job name and owner as the chain job. Each step job additionally has a step job subname to uniquely identify it. The step job subname is included as the JOB_SUBNAME column in the views *_SCHEDULER_RUNNING_JOBS, *_SCHEDULER_JOB_LOG, and *_SCHEDULER_JOB_RUN_DETAILS, and as the STEP_JOB_SUBNAME column in the *_SCHEDULER_RUNNING_CHAINS views.
See Also:
"Creating and Managing Job Chains"You typically create job classes only when you are in the role of Scheduler administrator.
Job classes provide a way to:
Assign the same set of attribute values to member jobs
Each job class specifies a set of attributes, such as logging level. When you assign a job to a job class, the job inherits those attributes. For example, you can specify the same policy for purging log entries for all payroll jobs.
Set service affinity for member jobs
You can set the service attribute of a job class to a desired database service name. This determines the instances in a Real Application Clusters environment that run the member jobs, and optionally, the system resources that are assigned to member jobs. See "Service Affinity when Using the Scheduler" for more information.
Set resource allocation for member jobs
Job classes provide the link between the Database Resource Manager and the Scheduler, because each job class can specify a resource consumer group as an attribute. Member jobs then belong to the specified consumer group and are assigned resources according to settings in the current resource plan.
Alternatively, you can leave the resource_consumer_group attribute NULL and set the service attribute of a job class to a desired database service name. That service can in turn be mapped to a resource consumer group. If both the resource_consumer_group and service attributes are set, and the designated service maps to a resource consumer group, the resource consumer group named in the resource_consumer_group attribute takes precedence.
See Chapter 27, "Managing Resources with Oracle Database Resource Manager" for more information on mapping services to consumer groups.
Group jobs for prioritization
Within the same job class, you can assign priority values of 1-5 to individual jobs so that if two jobs in the class are scheduled to start at the same time, the one with the higher priority takes precedence. This ensures that you do not have a less important job preventing the timely completion of a more important one.
If two jobs have the same assigned priority value, the job with the earlier start date takes precedence. If no priority is assigned to a job, its priority defaults to 3.
Note:
Job priorities are used only to prioritize among jobs in the same class.There is no guarantee that a high priority job in class A will be started before a low priority job in class B, even if they share the same schedule. Prioritizing among jobs of different classes depends on the current resource plan and on the designated resource consumer group or service name of each job class.
When defining job classes, try to classify jobs by functionality. Consider dividing jobs into groups that access similar data, such as marketing, production, sales, finance, and human resources.
Some of the restrictions to keep in mind are:
A job must be part of exactly one class. When you create a job, you can specify which class the job is part of. If you do not specify a class, the job automatically becomes part of the class DEFAULT_JOB_CLASS.
Dropping a class while there are still jobs in that class results in an error. You can force a class to be dropped even if there are still jobs that are members of that class, but all jobs referring to that class are then automatically disabled and assigned to the class DEFAULT_JOB_CLASS. Jobs belonging to the dropped class that are already running continue to run under class settings determined at the start of the job.
See Also:
"Creating Job Classes"You typically create windows only when you are in the role of Scheduler administrator.
You create windows to automatically start jobs or to change resource allocation among jobs during various time periods of the day, week, and so on. A window is represented by an interval of time with a well-defined beginning and end, such as "from 12am-6am".
Windows work with job classes to control resource allocation. Each window specifies the resource plan to activate when the window opens (becomes active), and each job class specifies a resource consumer group or specifies a database service, which can map to a consumer group. A job that runs within a window, therefore, has resources allocated to it according to the consumer group of its job class and the resource plan of the window.
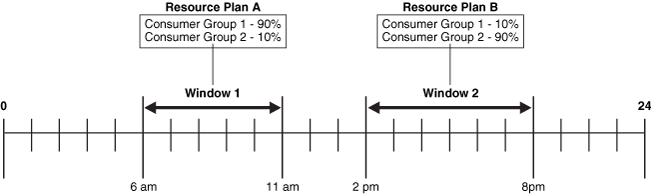
Figure 28-2 shows a workday that includes two windows. In this configuration, jobs belonging to the job class that links to Consumer Group 1 get more resources in the morning than in the afternoon. The opposite is true for jobs in the job class that links to Consumer Group 2.
Figure 28-2 Windows help define the resources that are allocated to jobs
See Chapter 27, "Managing Resources with Oracle Database Resource Manager" for more information on resource plans and consumer groups.
You can assign a priority to each window. If windows overlap, the window with the highest priority is chosen over other windows with lower priorities. The Scheduler automatically opens and closes windows as window start times and end times come and go.
A job can name a window in its schedule_name attribute. The Scheduler then starts the job when the window opens. If a window is already open, and a new job is created that points to that window, the new job does not start until the next time the window opens.
Note:
If necessary, you can temporarily block windows from switching the current resource plan. For more information, see "Enabling Oracle Database Resource Manager and Switching Plans", or the discussion of theDBMS_RESOURCE_MANAGER.SWITCH_PLAN package procedure in Oracle Database PL/SQL Packages and Types Reference.See Also:
"Creating Windows"Although Oracle does not recommend it, windows can overlap.
Because only one window can be active at one time, the following rules are used to determine which window is active when windows overlap:
If windows of the same priority overlap, the window that is active will stay open. However, if the overlap is with a window of higher priority, the lower priority window will close and the window with the higher priority will open. Jobs currently running that had a schedule naming the low priority window may be stopped depending on the behavior you assigned when you created the job.
If, at the end of a window, there are multiple windows defined, the window with the highest priority opens. If all windows have the same priority, the window that has the highest percentage of time remaining opens.
An open window that is dropped automatically closes. At that point, the previous rule applies.
Whenever two windows overlap, an entry is written in the Scheduler log.
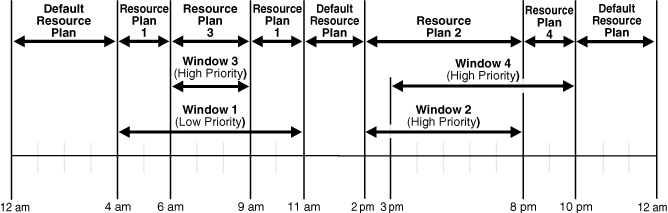
Figure 28-3 illustrates a typical example of how windows, resource plans, and priorities might be determined for a 24 hour schedule. In the following two examples, assume that Window1 has been associated with Resource Plan1, Window2 with Resource Plan2, and so on.
Figure 28-3 Windows and Resource Plans (Example 1)
In Figure 28-3, the following occurs:
From 12AM to 4AM
No windows are open, so a default resource plan is in effect.
From 4AM to 6AM
Window1 has been assigned a low priority, but it opens because there are no high priority windows. Therefore, Resource Plan 1 is in effect.
From 6AM to 9AM
Window3 will open because it has a higher priority than Window1, so Resource Plan 3 is in effect.
From 9AM to 11AM
Even though Window1 was closed at 6AM because of a higher priority window opening, at 9AM, this higher priority window is closed and Window1 still has two hours remaining on its original schedule. It will be reopened for these remaining two hours and resource plan will be in effect.
From 11AM to 2PM
A default resource plan is in effect because no windows are open.
From 2PM to 3PM
Window2 will open so Resource Plan 2 is in effect.
From 3PM to 8PM
Window4 is of the same priority as Window2, so it does not interrupt Window2 and Resource Plan 2 is in effect.
From 8PM to 10PM
Window4 will open so Resource Plan 4 is in effect.
From 10PM to 12AM
A default resource plan is in effect because no windows are open.
Figure 28-4 illustrates another example of how windows, resource plans, and priorities might be determined for a 24 hour schedule.
Figure 28-4 Windows and Resource Plans (Example 2)
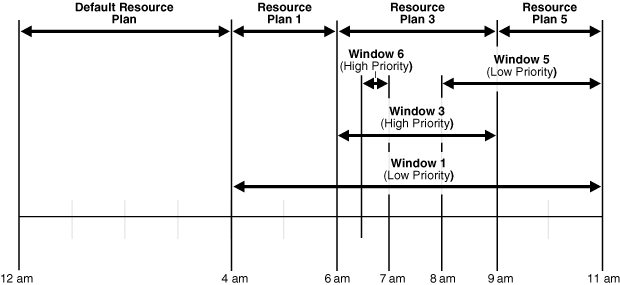
In Figure 28-4, the following occurs:
From 12AM to 4AM
A default resource plan is in effect.
From 4AM to 6AM
Window1 has been assigned a low priority, but it opens because there are no high priority windows, so Resource Plan 1 is in effect.
From 6AM to 9AM
Window3 will open because it has a higher priority than Window1. Note that Window6 does not open because another high priority window is already in effect.
From 9AM to 11AM
At 9AM, Window5 or Window1 are the two possibilities. They both have low priorities, so the choice is made based on which has a greater percentage of its duration remaining. Window5 has a larger percentage of time remaining compared to the total duration than Window1. Even if Window1 were to extend to, say, 11:30AM, Window5 would have 2/3 * 100% of its duration remaining, while Window1 would have only 2.5/7 * 100%, which is smaller. Thus, Resource Plan 5 will be in effect.
A group designates a list of Scheduler objects. Instead of passing a list of objects as an argument to a DBMS_SCHEDULER package procedure, you create a group that has those objects as its members, and then pass the group name to the procedure.
There are three types of groups:
Database destination groups: Members are database destinations, for running remote database jobs.
External destination groups: Members are external destinations, for running remote external jobs.
Window groups: Members are Scheduler windows.
All members of a group must be of the same type and each member must be unique.
You create a group with the DBMS_SCHEDULER.CREATE_GROUP procedure.
When you want a job to run at multiple destinations, you create a database destination group or external destination group and assign it to the destination_name attribute of the job. Specifying a destination group as the destination_name attribute of a job is the only valid way to specify multiple destinations for the job.
You typically create window groups only when you are in the role of Scheduler administrator.
You can group windows for ease of use in scheduling jobs. If a job must run during multiple time periods throughout the day, week, and so on, you can create a window for each time period, and then add the windows to a window group. You can then set the schedule_name attribute of the job to the name of this window group, and the job executes during all the time periods specified by the windows in the window group.
For example, if you had a window called "Weekends" and a window called "Weeknights," you could add these two windows to a window group called "Downtime." The data warehousing staff could then create a job to run queries according to this Downtime window group—on weeknights and weekends—when the queries could be assigned a high percentage of available resources.
If a window in a window group is already open, and a new job is created that points to that window group, the job is not started until the next window in the window group opens.
|
Copyright © 2001, 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|