| Oracle® Warehouse Builder Data Modeling, ETL, and Data Quality Guide 11g Release 2 (11.2) Part Number E10935-05 |
|
|
PDF · Mobi · ePub |
| Oracle® Warehouse Builder Data Modeling, ETL, and Data Quality Guide 11g Release 2 (11.2) Part Number E10935-05 |
|
|
PDF · Mobi · ePub |
This chapter discusses the name and address cleansing features of Oracle Warehouse Builder.
This chapter contains the following topics:
"About Name and Address Cleansing in Oracle Warehouse Builder"
"Using the Name and Address Operator to Cleanse and Correct Name and Address Data"
Oracle Warehouse Builder includes name and address cleansing functionality and can integrate with third-party name and address cleansing tools from several vendors. Oracle Warehouse Builder parses the names and addresses, and uses methods specific to this type of data, such as matching common nicknames and abbreviations. You can compare the input data to the data libraries supplied by third-party name and address cleansing software vendors, identify and correct errors and inconsistencies in name and address source data. You can then further augment your records with information such as postal routes and geographic coordinates.
Note:
Oracle Warehouse Builder exposes its name and address cleansing functionality through the Name and Address operator, used in an Oracle Warehouse Builder ETL mapping.Users of third-party ETL products can still use Oracle Warehouse Builder for name and address cleansing, while retaining their existing ETL solution.
Use the third-party ETL tool to load name and address cleansing input data in a staging table, or use an existing table as a source.
Use an Oracle Warehouse Builder ETL mapping to apply name and address cleansing, and load the corrected data into an output table.
Use the third-party ETL tool to pick up the cleansed results from the output table for further processing.
Because the deployed code for the mapping is just a PL/SQL package loaded in the database where the name and address cleansing takes place, this technique can be used from any ETL tool that can call logic from a PL/SQL package.
Also data libraries are not bundled with Oracle Warehouse Builder. Licenses must be purchased directly from third-party vendors.
Note:
The Name and Address operator requires separate licensing and installation of third-party name and address cleansing software. See Oracle Warehouse Builder Installation and Administration Guide.The errors and inconsistencies corrected by the Name and Address operator include variations in address formats, use of abbreviations, misspellings, outdated information, inconsistent data, and transposed names. The operator fixes these errors and inconsistencies by:
Parsing the name and address input data into individual elements.
Standardizing name and address data, using standardized versions of nicknames and business names and standard abbreviations of address components, as approved by the postal service of the appropriate country. Standardized versions of names and addresses facilitate matching and householding, and ultimately help you obtain a single view of your customer.
Correcting address information such as street names and city names. Filtering out incorrect or undeliverable addresses can lead to savings on marketing campaigns.
Augmenting names and addresses with additional data such as gender, postal code, country code, apartment identification, or business and consumer identification. You can use this and other augmented address information, such as census geocoding, for marketing campaigns that are based on geographical location.
Augmenting addresses with geographic information facilitates geography-specific marketing initiatives, such as marketing only to customers in large metropolitan areas (for example, within an n-mile radius of large cities); marketing only to customers served by a company's stores (within an x-mile radius of these stores). Oracle Spatial, an option with Oracle Database, and Oracle Locator, packaged with Oracle Database, are two products that you can use with this feature.
The Name and Address operator also enables you to generate postal reports for countries that support address correction and postal matching. Postal reports often qualify you for mailing discounts. For more information, see "About Postal Reporting".
This example follows a record through a mapping using the Name and Address operator. This mapping also uses a Splitter operator to demonstrate a highly recommended data quality error handling technique.
In this example, the source data contains a Customer table with the row of data shown in Table 22-1.
Table 22-1 Sample Input to Name and Address Operator
| Address Column | Address Component |
|---|---|
|
Name |
Joe Smith |
|
Street Address |
8500 Normandale Lake Suite 710 |
|
City |
Bloomington |
|
ZIP Code |
55437 |
The data contains a nickname, a last name, and part of a mailing address, but it lacks the customer's full name, complete street address, and the state in which he lives. The data also lacks geographic information such as latitude and longitude, that you use to calculate distances for truckload shipping.
This example uses a mapping with a Name and Address operator to cleanse name and address records, followed by a Splitter operator to load the records into separate targets depending on whether they were successfully parsed. This section explains the general steps required to design such a mapping.
To make the listed changes to the sample record:
In the Mapping Editor, begin by adding the following operators to the canvas:
A CUSTOMERS table from which you extract the records. This is the data source. It contains the data in Table 22-1.
A Name and Address operator. This action starts the Name and Address Wizard. Follow the steps of the wizard.
A Splitter operator. For information about using this operator, see "Splitter Operator".
Three target operators into which you load the successfully parsed records, the records with parsing errors, and the records whose addresses are parsed but not found in the postal matching software.
Map the attributes from the CUSTOMERS table to the Name and Address operator ingroup. Map the attributes from the Name and Address operator outgroup to the Splitter operator ingroup.
You are not required to use the Splitter operator, but it provides an important function in separating good records from problematic records.
Define the split conditions for each of the outgroups in the Splitter operator and map the outgroups to the targets.
Figure 22-1 shows a mapping designed for this example. The data is mapped from the CUSTOMERS source table to the Name and Address operator, and then to the Splitter operator. The Splitter operator separates the successfully parsed records from those that have errors. The output from OUTGRP1 is mapped to the CUSTOMERS_GOOD target. The split condition for OUTGRP2 is set such that records whose Is Parsed flag is False are loaded to the NOT_PARSED target. That is, the Split Condition for OUTGRP2 is set as INGRP1.ISPARSED='F'. The Records in the REMAINING_RECORDS group are successfully parsed, but their addresses are not found by the postal matching software. These records are loaded to the PARSED_NOT_FOUND target.
Figure 22-1 Name and Address Operator Used with a Splitter Operator in a Mapping
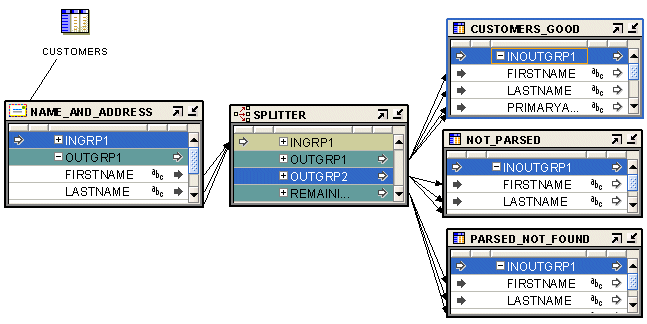
If you run the mapping designed in this example, the Name and Address operator standardizes, corrects, and completes the address data from the source table. In this example, the target table contains the address data as shown in Table 22-2. Compare it with the input record from Table 22-1 .
Table 22-2 Sample Output from Name and Address Operator
| Address Column | Address Component |
|---|---|
|
First Name Standardized |
JOSEPH |
|
Last Name |
SMITH |
|
Primary Address |
8500 NORMANDALE LAKE BLVD |
|
Secondary Address |
STE 710 |
|
City |
BLOOMINGTON |
|
State |
MN |
|
Postal Code |
55437-3813 |
|
Latitude |
44.849194 |
|
Longitude |
-093.356352 |
|
Is Parsed |
True |
|
Is Good Name |
True |
|
Is Good Address |
True |
|
Is Found |
True |
|
Name Warning |
False |
|
Street Warning |
False |
|
City Warning |
False |
In this example, the following changes were made to the input data:
Joe Smith was separated into separate columns for First_Name_Standardized and Last_Name.
Joe was standardized into JOSEPH and Suite was standardized into STE.
Normandale Lake was corrected to NORMANDALE LAKE BLVD.
The first portion of the postal code, 55437, was augmented with the ZIP+4 code to read 55437-3813.
Latitude and longitude locations were added.
The records were tested in various ways, and the good records were directed to a different target from the ones that have problems.
All address lists used to produce mailings for discounted automation postal rates must be matched by postal report-certified software. Certifications depend on the third-party vendors of name and address software and data. The certifications may include the following:
United States Postal Service: Coding Accuracy Support System (CASS)
Canada Post: Software Evaluation and Recognition Program (SERP)
Australia Post: Address Matching Approval System (AMAS)
The Coding Accuracy Support System (CASS) was developed by the United States Postal Service (USPS) in cooperation with the mailing industry. The system provides mailers a common platform to measure the quality of address-matching software, focusing on the accuracy of five-digit ZIP Codes, ZIP+4 Codes, delivery point codes, and carrier route codes applied to all mail. All address lists used to produce mailings for automation rates must be matched by CASS-certified software.
To meet USPS requirements, the mailer must submit a CASS report in its original form to the USPS.
Canada Post developed a testing program called Software Evaluation and Recognition Program (SERP), which evaluates software packages for their ability to validate, or validate and correct, mailing lists to Canada Post requirements. Postal programs that meet SERP requirements are listed on the Canada Post Web site.
Canadian postal customers who use Incentive Lettermail, Addressed Admail, and Publications Mail must meet the Address Accuracy Program requirements. Customers can obtain a Statement of Accuracy by comparing their databases to Canada Post's address data.
The Address Matching Approval System (AMAS) was developed by Australia Post to improve the quality of addressing. It provides a standard by which to test and measure the ability of address-matching software to:
Correct and match addresses against the Postal Address File (PAF).
Append a unique Delivery Point Identifier (DPID) to each address record, which is a step toward barcoding mail.
AMAS enables companies to develop address matching software which:
Prepares addresses for barcode creation
Ensures quality addressing
Enables qualification for discounts on PreSort letters lodgements
PreSort Letters Service prices are conditional upon customers using AMAS Approved Software with Delivery Point Identifiers (DPIDs) being current against the latest version of the PAF.
A declaration that the mail was prepared appropriately must be made when using the Presort Lodgement Document, available from post offices.
For each attribute that you select for Name or Address cleansing, you must specify an input role to indicate the type of data that is stored in the source attribute. Oracle Warehouse Builder provides a set of predefined input roles from which you can select the most suitable one for your data.
For example, the Employees table contains the columns last_name and city. You can select the Last Name and City respectively for these columns.
Table 22-3 describes the input roles for the Name and Address Operator.
Table 22-3 Name and Address Operator Input Roles
| Input Role | Description |
|---|---|
|
Pass Through |
Any attribute that requires no processing |
|
First Name |
First name, nickname, or shortened version of the first name. |
|
Middle Name |
Middle name or initial. Use when there is only one middle name, or for the first of several middle names (for example, "May" in Ethel May Roberta Louise Mertz). |
|
Middle Name 2 |
Second middle name (for example, "Roberta" in Ethel May Roberta Louise Mertz) |
|
Middle Name 3 |
Third middle name (for example, "Louise" in Ethel May Roberta Louise Mertz) |
|
Last Name |
Last name or surname. |
|
First Part Name |
First part of the Person name, including:
Use when these components are contained in one source column. |
|
Last Part Name |
Last part of Person Name, including:
Use when these components are all contained in one source column. |
|
Pre Name |
Information that precedes and qualifies the name (for example, Ms., Mr., or Dr.) |
|
Post Name |
Generation or other information qualifying the name (for example, Jr. or Ph.D.) |
|
Person |
Full person name, including:
Use when these components are all contained in one source column. |
|
Person 2 |
Designates a second person if the input includes multiple personal contacts |
|
Person 3 |
Designates a third person if the input includes multiple personal contacts |
|
Firm Name |
Name of the company or organization |
|
Primary Address |
Box, route, or street address, including:
This does not include the Unit Designator or the Unit Number. |
|
Secondary Address |
The second part of the street address, including:
For example, in a secondary address of Suite 2100, the Unit Designator is STE (a standardization of "Suite") and the Unit Number is 2100. |
|
Address |
Full address line, including:
Use when these components share one column. |
|
Address 2 |
Generic address line |
|
Neighborhood |
Neighborhood or barrio, common in South and Latin American addresses. |
|
Locality Name |
The city (shi) or island (shima) in Japan. |
|
Locality 2 |
The ward (ku) in Japan. |
|
Locality 3 |
The district (machi) or village (mura) in Japan |
|
Locality 4 |
The subdistrict (aza, bu, chiwari, or sen) in Japan |
|
City |
Name of city |
|
State |
Name of state or province |
|
Postal Code |
Postal code, such as a ZIP code in the United States or a postal code in Canada |
|
Country Name |
Full country name |
|
Country Code |
The ISO 3166-1993 (E) 2-character or 3-character country code. For example, US or USA for United States; CA or CAN for Canada |
|
Last Line |
Last address line, including:
Use when these components are all contained in one source column. |
|
Last Line 2 |
For Japanese adaptors, specifies additional line information that appears after an address |
|
Line1... Line10 |
Use for free-form name, business, personal, and address text of any type. These roles do not provide the parser with any information about the data content. Whenever possible, use the discrete input roles provided instead. |
Use output components to define attributes that stores data cleansed by the Name and Address operator. Any attributes with an input role of Pass Through are automatically displayed as output components. You can define additional output components to store cleansed data.
Categories of Output Components
Output components are grouped in the following categories:
The Pass Through output component is for any attribute that requires no processing. When you create a Pass Through input role, the corresponding Pass Through output component is created automatically. You cannot edit a Pass Through output component, but you can edit the corresponding input role.
Table 22-4 describes the Name output components. Many components can be used multiple times to process a record, as noted in the table. For example, in records with two occurrences of Firm Name, you can extract both by adding two output attributes. Assign one as the First instance, and the other as the Second instance.
Table 22-4 Name Output Components
| Subfolder | Output Component | Description |
|---|---|---|
|
None |
Pre Name |
Title or salutation appearing before a name (for example, Ms. or Dr.). Can be used multiple times. |
|
None |
First Name Standardized |
Standard version of first name; for example, Theodore for Ted or James for Jim. Can be used multiple times. |
|
None |
Middle Name Standardized |
Standardized version of the middle name; for example, Theodore for Ted or James for Jim. Use when there is only one middle name, or for the first of several middle names. Can be used multiple times. |
|
None |
Middle Name 2 Standardized |
Standardized version of the second middle name; for example, Theodore for Ted or James for Jim. Can be used multiple times. |
|
None |
Middle Name 3 Standardized |
Standardized version of the third middle name; for example, Theodore for Ted or James for Jim. Can be used multiple times. |
|
None |
Post Name |
Name suffix indicating generation; for example, Sr., Jr., or III. Can be used multiple times. |
|
None |
Other Post Name |
Name suffix indicating certification, academic degree, or affiliation; for example, Ph.D., M.D., or R.N. Can be used multiple times. |
|
None |
Title |
Personal title, for example, Manager. Can be used multiple times. |
|
None |
Name Designator |
Personal name designation; for example, ATTN (to the attention of) or C/O (care of). Can be used multiple times. |
|
None |
Relationship |
Information related to another person; for example, Trustee For. Can be used multiple times. |
|
None |
SSN |
Social security number |
|
None |
Email Address |
E-mail address |
|
None |
Phone Number |
Telephone number |
|
None |
Name/Firm Extra |
Extra information associated with the firm or personal name |
|
None |
Person |
First name, middle name, and last name. Can be used multiple times. |
|
Person |
First Name |
The first name found in the input name. Can be used multiple times. |
|
Person |
Middle Name |
Middle name or initial. Use this for a single middle name, or for the first of several middle names; for example, "May" in Ethel May Roberta Louise Mertz. Can be used multiple times. |
|
Person |
Middle Name 2 |
Second middle name; for example, "Roberta" in Ethel May Roberta Louise Mertz. Can be used multiple times. |
|
Person |
Middle Name 3 |
Third middle name; for example, "Louise" in Ethel May Roberta Louise Mertz. Can be used multiple times. |
|
Person |
Last Name |
Last name or surname. Can be used multiple times. |
|
Derived |
Gender |
Probable gender:
Can be used multiple times. |
|
Derived |
Person Count |
Number of persons that the record references; for example, a record with a Person name of "John and Jane Doe" has a Person Count of 2. |
|
Business |
Firm Name |
Name of the company or organization, including divisions. Can be used multiple times. |
|
Business |
Firm Count |
Number of firms referenced in the record. Can be used multiple times. |
|
Business |
Firm Location |
Location within a firm; for example, Accounts Payable |
Table 22-5 describes the Address output components. In records with dual addresses, you can specify which line is used as the Normal Address (and thus assigned to the Address component) and which is used as the Dual Address for many output components, as noted in the table.
Table 22-5 Address Output Components
| Subfolder | Output Component | Description |
|---|---|---|
|
None |
Address |
Full address line, including:
Can be used as the Normal Address or the Dual Address. |
|
None |
Primary Address |
Box, route, or street address, including:
Does not include the output components Unit Designator or Unit Number. Can be used as the Normal Address or the Dual Address. |
|
Primary Address |
Street Number |
Number that identifies the address, such as a house or building number, sometimes referred to as the primary range. For example, in 200 Oracle Parkway, the |
|
Primary Address |
Pre Directional |
Street directional indicator appearing before the street name; for example, in 100 N University Drive, the |
|
Primary Address |
Street Name |
Name of street. Can be used as the Normal Address or the Dual Address. |
|
Primary Address |
Primary Name 2 |
Second street name, often used for addresses at a street intersection. |
|
Primary Address |
Street Type |
Street identifier; for example, ST, AVE, RD, DR, or HWY. Can be used as the Normal Address or the Dual Address. |
|
Primary Address |
Post Directional |
Street directional indicator appearing after the street name; for example, in 100 15th Ave. S., the |
|
None |
Secondary Address |
The second part of the street address, including:
For example, in a secondary address of Suite 2100, |
|
Secondary Address |
Unit Designator |
Type of secondary address, such as APT or STE. For example, in a secondary address of Suite 2100, |
|
Secondary Address |
Unit Number |
A number that identifies the secondary address, such as the apartment or suite number. For example, in a secondary address of Suite 2100, |
|
Secondary Address |
Non-postal Secondary Address |
A secondary address that is not in official postal format |
|
Secondary Address |
Non-postal Unit Designator |
A unit designator that is not in official postal format |
|
Secondary Address |
Non-postal Unit Number |
A unit number that is not in official postal format |
|
Address |
Last Line |
Final address line, including:
|
|
Last Line |
Neighborhood |
Neighborhood or barrio, common in South and Latin American addresses |
|
Last Line |
City |
Name of city. The U.S. city names may be converted to United States Postal Service preferred names. |
|
Last Line |
City Abbreviated |
Abbreviated city name, composed of 13 characters for the United States |
|
Last Line |
City Abbreviated 2 |
Alternative abbreviation for the city name |
|
Last Line |
Alternate City |
An alternate name for a city that may be referenced by multiple name. In the United States, a city may be referenced by its actual name or the name of a larger urban area. For example, Brighton, Massachusetts may have Boston as an alternate city name. |
|
Last Line |
Locality Code |
The last three digits of the International Mailsort Code, which represents a geographical region or locality within each country. Locality Codes are numeric in the range 000 to 999. |
|
Last Line |
Locality Name |
In the United Kingdom, the following address is assigned Locality Name KNAPHILL: Chobham Rd Knaphill Woking GU21 2TZ |
|
Last Line |
Locality 2 |
The ward (ku) in Japan |
|
Last Line |
Locality 3 |
The district (machi) or village (mura) in Japan |
|
Last Line |
Locality 4 |
The subdistrict (aza, bu, chiwari, or sen) in Japan |
|
Last Line |
County Name |
The name of a county in the United Kingdom, United States, or other country |
|
Last Line |
State |
Name of state or province |
|
Last Line |
Postal Code |
Full postal code with spaces and other nonalphanumeric characters removed |
|
Last Line |
Postal Code Formatted |
Formatted version of postal code that includes spaces and other nonalphanumeric characters, such as dashes |
|
Last Line |
Delivery Point |
A designation used in the United States and Australia.
|
|
Last Line |
Country Code |
The ISO 3166-1993 (E) 2-character country code, as defined by the International Organization for Standardization; for example, "US" for United States or 'CA' for Canada. |
|
Last Line |
Country Code 3 |
The ISO 3166-1993 (E) 3-character country code, as defined by the International Organization for Standardization; for example, "USA" for United States, "FRA" for France, or "UKR" for Ukraine. |
|
Last Line |
Country Name |
The full country name |
|
Address |
Address 2 |
A second address line, typically used for Hong Kong addresses that have both a street address and a building or floor address |
|
Address |
Last Line 2 |
Additional information that appears after an address in Japan |
|
Other Address Line |
Box Name |
The name for a post office box address; for example, for "PO Box 95", the Box Name is "PO BOX". Can be used as the Normal Address or the Dual Address. |
|
Other Address Line |
Box Number |
The number for a post office box address; for example, for "PO Box 95", the Box Number is "95". Can be used as the Normal Address or the Dual Address. |
|
Other Address Line |
Route Name |
Route name for a rural route address. For an address of "Route 5 Box 10", the Route Name is "RTE" (a standardization of "Route"). Can be used as the Normal Address or the Dual Address. |
|
Other Address Line |
Route Number |
Route number for a rural route address. For an address of "Route 5 Box 10", the Route Number is "5". Can be used as the Normal Address or the Dual Address. |
|
Other Address Line |
Building Name |
Building name, such as "Cannon Bridge House". Building names are common in the United Kingdom. |
|
Other Address Line |
Complex |
Building, campus, or other complex. For example, USS John F. Kennedy Shadow Green Apartments Cedarvale Gardens Concordia College You can use the Instance field in the Output Components dialog box to specify which complex should be returned if an address has multiple complex. |
|
Other Address Line |
Miscellaneous Address |
Miscellaneous address information. In records with multiple miscellaneous fields, you can extract them by specifying which instance to use in the Output Components page. |
|
Geography |
Latitude |
Latitude in degrees north of the equator: Positive for north of the equator; negative for south (always positive for North America) |
|
Geography |
Longitude |
Longitude in degrees east of the Greenwich Meridian: positive for east of GM; negative for west (always negative for North America) |
|
Geography |
Geo Match Precision |
Indicates how closely the location identified by the latitude and longitude matches the address |
Twenty components are open for vendor-specified usage.
Table 22-6 describes the Error Status output components. See "Handling Errors in Name and Address Data" for usage notes about the Error Status components.
Table 22-6 Error Status Output Components
| Subfolders | Output Component | Description |
|---|---|---|
|
Name and Address |
Is Good Group |
Indicates whether the name group, address group, or name and address group was processed successfully.
Using this flag with another flag, such as the |
|
Name and Address |
Is Parsed |
Indicates whether the name or address was parsed:
Check the status of warning flags such as |
|
Name and Address |
Parse Status |
Postal matching software parse status code |
|
Name and Address |
Parse Status Description |
Text description of the postal matching software parse status |
|
Name Only |
Is Good Name |
Indicates whether the name was parsed successfully:
|
|
Name Only |
Name Warning |
Indicates whether the parser found unusual or possibly erroneous data in a name:
|
|
Address Only |
Is Good Address |
Indicates whether the address was processed successfully:
Use this component when you have a mix of records from both postal-matched and non-postal-matched countries. |
|
Address Only |
Is Found |
Indicates whether the address is listed in the postal matching database for the country indicated by the address:
This flag is true only if all of the other "Found" flags are true. If postal matching is available, then this flag is the best indicator of record quality. |
|
Address Only: Is Found |
City Found |
T = The postal matcher found the city; otherwise, F. |
|
Address Only: Is Found |
Street Name Found |
T = The postal matcher found the street name; otherwise, F. |
|
Address Only: Is Found |
Street Number Found |
T = The postal matcher found the street number within a valid range of numbers for the named street, otherwise, F. |
|
Address Only: Is Found |
Street Components Found |
T = The postal matcher found the street components, such as the Pre Directional or Post Directional; otherwise, F. |
|
Address Only: Is Found |
Non-ambiguous Match Found |
Indicates whether the postal matcher found a matching address in the postal database:
|
|
Address Only |
City Warning |
T = The parser found unusual or possibly erroneous data in a city; otherwise, F. |
|
Address Only |
Street Warning |
T = The parser found unusual or possibly erroneous data in a street address; otherwise, F. |
|
Address Only |
Is Address Verifiable |
T = Postal matching is available for the country of the address; otherwise, F. F does not indicate whether a postal matching database is installed for the country in the address. It only indicates that matching is not available for a particular address. |
|
Address Only |
Address Corrected |
Indicates whether the address was corrected in any way during matching. Standardization is not considered correction in this case.
|
|
Address Only: Address Corrected |
Postal Code Corrected |
T = The postal code was corrected during matching, possibly by the addition of a postal extension; otherwise, F. |
|
Address Only: Address Corrected |
City Corrected |
T = The city name was corrected during matching; otherwise, F. Postal code input is used to determine the city name preferred by the postal service. |
|
Address Only: Address Corrected |
Street Corrected |
T = The street name was corrected during matching; otherwise, F. Some correct street names may be changed to an alternate name preferred by the postal service. |
|
Address Only: Address Corrected |
Street Components Corrected |
T = One or more street components, such as |
|
Address Only |
Address Type |
Type of address. The following are common examples; actual values vary with vendors of postal matching software:
|
|
Address Only |
Parsing Country |
Country parser that was used for the final parse of the record |
Table 22-7 describes the output components that are specific to a particular country.
Table 22-7 Country-Specific Output Components
| Subfolder | Output Component | Description |
|---|---|---|
|
United States |
ZIP5 |
The 5-digit United States postal code |
|
United States |
ZIP4 |
The 4-digit suffix that is added to the 5-digit United States postal code to further specify location. |
|
United States |
Urbanization Name |
Urban unit name used in Puerto Rico |
|
United States |
LACS Flag |
T = Address requires a LACS conversion and should be submitted to a LACS vendor; otherwise, F. The Locatable Address Conversion System (LACS) provides new addresses when a 911 emergency system has been implemented. The 911 address conversions typically involve changing rural-style addresses to city-style street addresses, but they may involve renaming or renumbering existing city-style addresses. |
|
United States |
CART |
The 4-character USPS Carrier route |
|
United States |
DPBC Check Digit |
Check digit for forming a delivery point bar code |
|
United States |
Automated Zone Indicator |
T = The mail in this zip code is sorted by bar code sorting equipment; otherwise, F. |
|
United States |
Urban Indicator |
T = An address is located within an urban area; otherwise, F. |
|
United States |
Line of Travel |
United States Postal Service (USPS) line of travel |
|
United States |
Line of Travel Order |
United States Postal Service (USPS) line of travel order |
|
United States: Census/Geography |
Metropolitan Statistical Area |
Metropolitan Statistical Area (MSA) number. For example, "0000" indicates that the address does not lie within any MSA, and typically indicates a rural area. |
|
United States: Census/Geography |
Minor Census District |
Minor Census District |
|
United States: Census/Geography |
CBSA Code |
A 5-digit Core-Based Statistical Area (CBSA) code that identifies metropolitan and micropolitan areas. |
|
United States: Census/Geography |
CBSA Descriptor |
Indicates whether the CBSA is metropolitan (population of 50,000 or more) or micropolitan (population of 10,000 to 49,999). |
|
United States: Census/Geography |
FIPS Code |
The complete (state plus county) code assigned to the county by the Federal Information Processing Standard (FIPS). Because FIPS county codes are unique within a state, a complete FIPS Code includes the 2-digit state code followed by the 3-digit county code. |
|
United States: Census/Geography |
FIPS County |
The 3-digit county code as defined by the Federal Information Processing Standard (FIPS). |
|
United States: Census/Geography |
FIPS Place Code |
The 5-digit place code as defined by the Federal Information Processing Standard (FIPS). |
|
United States: Geography |
Census ID |
United States Census tract and block-group number. The first six digits are the tract number; the final digit is the block-group number within the tract. These codes are used for matching to demographic-coding databases. |
|
Canada |
Installation Type |
A type of Canadian postal installation:
For example, for the address, "PO Box 7010, Scarborough ON M1S 3C6," the Installation Type is "STN". |
|
Canada |
Installation Name |
Name of a Canadian postal installation. For example, for the address, "PO Box 7010, Scarborough ON M1S 3C6," the Installation Name is "AGINCOURT". |
|
Hong Kong |
Delivery Office Code |
A mailing code used in Hong Kong. For example, the following address is assigned the Delivery Office Code "WCH": Oracle 39/F The Lee Gardens 33 Hysan Ave Causeway Bay |
|
Hong Kong |
Delivery Beat Code |
A mailing code used in Hong Kong. For example, the following address is assigned the Delivery Beat Code "S06": Oracle 39/F The Lee Gardens 33 Hysan Ave Causeway Bay |
Name and Address parsing, like any other type of parsing, depends on identification of keywords and patterns containing those keywords. Free-form name and address data is sometimes difficult to parse because the keyword set is large and it is never 100% complete. Keyword sets are built by analyzing millions of records, but each new data set is likely to contain some undefined keywords.
Because most free-form name and address records contain common patterns of numbers, single letters, and alphanumeric strings, parsing can often be performed based on just the alphanumeric patterns. However, alphanumeric patterns may be ambiguous, or a particular pattern may not be found. Name and Address parsing errors set parsing status codes that you can use to control data mapping.
Because the criteria for quality vary among applications, numerous flags are available to help you determine the quality of a particular record. For countries with postal matching support, use the Is Good Group flag, because it verifies that an address is a valid entry in a postal database. Also use the Is Good Group flag for U.S. Coding Accuracy Support System (CASS) and Canadian Software Evaluation and Recognition Program (SERP) certified mailings.
Unless you specify postal reporting, an address does not have to be found in a postal database to be acceptable. For example, street intersection addresses or building names may not be in a postal database, but they may still be deliverable. If the Is Good Group flag indicates failure, then additional error flags can help determine the parsing status.
The Is Parsed flag indicates success or failure of the parsing process. If Is Parsed indicates parsing success, then you may still want to check the parser warning flags, which indicate unusual data. You may want to check those records manually.
If Is Parsed indicates parsing failure, you must preserve the original data to prevent data loss.
Use the Splitter operator to map successful records to one target and failed records to another target.
The Name and Address operator accepts one PL/SQL input and generates one PL/SQL output.
If you experience timeout errors, you must increase the socket timeout setting of the Name and Address Server. The timeout setting is the number of seconds that the server waits for a parsing request from a mapping before the server drops a connection. The default setting is 600 seconds (10 minutes). After the server drops a connection because of inactivity, subsequent parsing requests fail with a NAS-00021 error.
For most mappings, long time lapses between parsing requests are rare. However, maps operating in row-based mode with a Filter operator may have long time lapses between record parsing requests, because of the inefficiency of filtering records in row-based mode. For this type of mapping, you must increase the socket timeout value to prevent connections from being dropped.
To increase the socket timeout setting, see "Managing the Name and Address Server".
The Name and Address operator has one input group and one output group.
To create a mapping with a Name and Address operator:
Drag and drop the operators representing the source data and the operator representing the cleansed data onto the Mapping Editor canvas:
For example, if your source data is stored in a table, and the cleansed data is stored in another table, drag and drop two Table operators that are bound to the tables onto the canvas.
Drag and drop a Name and Address operator onto the Mapping Editor canvas.
The Name and Address Wizard is displayed.
On the Name page, specify a name and an optional description for the Name and Address operator.
Or, you can retain the default name displayed in the Name field.
On the Definitions page, select values that define the type of source data.
See "Specifying Source Data Details and Setting Parsing Type".
On the Groups page, optionally rename the input and output groups.
The Name and Address operator has one input group, INGRP1, and one output group, OUTGRP1. You cannot edit, add, or delete groups. If the input data requires multiple groups, then create a separate Name and Address operator for each group.
On the Input Connections page, select attributes from any operator in your mapping to copy and map to the Name and Address operator.
To complete the Input Connections page for an operator:
Select complete groups or individual attributes from the Available Attributes panel.
To search for a specific attribute or group by name, type the text in Search for and click Go. To find the next match, click Go again.
Hold the Shift key down to select multiple groups or attributes. To select attributes from different groups, then you must first combine the groups with a Joiner or Set operator.
Note:
If you have not created any operators for the source data, the Available Attributes section is empty.Use the right-arrow button between the two panels to move your selections to the Mapped Attributes panel.
The Mapped Attributes section lists the attributes that is processed by the Name and Address operator.
On the Input Attributes page, assign input roles to each attribute that you selected on the Input Attributes page.
Input roles indicate the type of name and address information that resides in a line of data. Whenever possible, choose discrete roles (such as City, State, and Postal Code) rather than nondiscrete ones (such as Last Line). Discrete roles improve parsing.
See Also:
"Input Role Descriptions"For attributes that have the input role set to Pass Through, specify the data type details using the Data Type, Length, Precision, Scale, and Seconds Precision fields.
On the Output Attributes page, define output attributes that determine how the Name and Address operator handles parsed data. The output attribute properties characterize the data extracted from the parser output.
Any attributes that have the Pass Through input role assigned are automatically listed as output attributes. You can add additional output attributes.
Note:
The attributes for output components with the Pass Through role cannot be changed.To add output attributes:
Click an empty row on the Output tab and enter the attribute name.
You can rename the output attribute by selecting the name and typing the new name.
Click the Ellipsis button on the Output Component field to select an output component for the attribute.
See Also:
"Descriptions of Output Components" for the descriptions of output components.Ensure that you add error handling flags such as Is Parsed, Is Good Name, and Is Good Address. You can use these flags with the Splitter operator to separate good records from the records with errors and load them into different targets.
Specify the data type details for the output attribute using the Data Type, Length, Precision, Scale, and Seconds Precision fields.
For countries that support address correction and postal matching, use the Postal Report page to specify the details for the postal report.
Use the Definitions page or the Definitions tab to provide information about your source data and to specify the type of parsing to be performed on the source data. Set the following values: "Parsing Type", "Primary Country", and "Dual Address Assignment".
Select one of the following parsing types:
Name Only: Select this option when the input data contains only name data. Names can include both personal and business names. Selecting this option instead of the more generic Name and Address option may improve performance and accuracy, depending on the adapter.
Address Only: Select this option when the input data contains only address data and no name data. Selecting this option instead of the more generic Name and Address option may improve performance and accuracy, depending on the adapter.
Name and Address: Select this option when the input data contains both name and address data.
Note:
You can only specify the parsing type when you first add the Name and Address operator to your mapping. You cannot modify the parsing type in the editor.Select the country that best represents the country distribution of your data. The primary country is used by some providers of name and address cleansing software as a hint for the appropriate parser or parsing rules to use on the initial parse of the record. For other name and address service providers, external configuration of their installation controls this behavior.
A dual address contains both a Post Office (PO) box and a street address for the same address record. For records that have dual addresses, your selection determines which address becomes the normal address and which address becomes the dual address. A sample dual address is:
PO Box 2589 4439 Mormon Coulee Rd La Crosse WI 54601-8231
The choice for Dual Address Assignment affects which postal codes are assigned during postal code correction, because the street address and PO box address may correspond to different postal codes.
Street Assignment: The street address is the normal address and the PO Box address is the dual address. It means that the Address component is assigned the street address. In the preceding example, the Address is 4439 MORMON COULEE RD. This choice corrects the postal code to 54601-8220.
PO Box Assignment: The PO Box address is the normal address and the street address is the dual address. It means that the Address component is assigned the Post Office (PO) box address. In the preceding example, the Address is PO BOX 2589. This choice corrects the postal code to 54602-2589.
Closest to Last Line: Whichever address occurs closest to the last line is the normal address; the other is the dual address. It means that the Address component is assigned the address line closest to the last line. In the preceding example, the Address is 4439 MORMON COULEE RD. This choice corrects the postal code to 54601-8220.
This option has no effect for records having a single street or PO box address.
Note:
Dual Address Assignment may not be supported by all name and address cleansing software providers.Country certification varies with different vendors of name and address cleansing software. The most common country certifications are United States, Canada, and Australia. The process provides mailers with a common platform to measure the quality of address-matching software, focusing on the accuracy of postal codes (in the United States, of 5-digit ZIP Codes and ZIP+4 Codes), delivery point codes, and carrier route codes applied to all mail. Some vendors of name and address cleansing software may ignore these parameters and require external setup for generating postal reports. For more information, see "About Postal Reporting".
To specify postal reporting, select Yes in the Postal Report files and then provide values for the fields:
Processor Name: The use of this field varies with vendors of name and address cleansing software. Typically, this value appears on the United States Coding Accuracy Support System (CASS) report.
List Name: An optional reference field that appears on the United States and United Kingdom reports under the List Name section, but is not included in other reports. The list name provides a reference for tracking multiple postal reports (for example, "July 2005 Promotional Campaign").
Processor Address Lines: These address lines may appear on various postal reports. Various name and address cleansing software vendors use these fields differently. They often contain the full address of your company.
An external Name and Address server provides an interface between Oracle Database and third-party name and address processing libraries. This section discusses details of configuring, starting, and stopping the Name and Address server.
The Name and Address operator generates PL/SQL code, which calls the UTL_NAME_ADDR package installed in the Runtime Schema. A private synonym, NAME_ADDR, is defined in the target schema to reference the UTL_NAME_ADDR package. The UTL_NAME_ADDR package calls Java packages, which send processing requests to an external Name and Address server, which then interfaces with third-party Name and Address processing libraries, such as Trillium.
You can use the server property file, NameAddr.properties, to configure server options. This file is located in owb/bin/admin under the Oracle home that you specified when installing the server components. The following code illustrates several important properties with their default settings.
TraceLevel=0 SocketTimeout=180 ClientThreads=4 Port=4040
The TraceLevel property is often changed to perform diagnostics on server communication and view output from the postal matching program parser. Other properties are rarely changed.
TraceLevel: Enables output of file NASvrTrace.log in the owb/bin/admin folder. This file shows all incoming and outgoing data, verifies that your mapping is communicating with the Name and Address server, and that the Name and Address server is receiving output from the service provider. The trace log shows all server input and output and is most useful for determining whether any parsing requests are being made by an executing mapping. Set TraceLevel=1 to enable logging. However, tracing degrades performance and creates a large log file. Set TraceLevel=0 to disable logging for production.
SocketTimeOut: Specifies the number of seconds that the Name and Address server waits for a parsing request before closing the connection. You can increase this time to 1800 (30 minutes) when running concurrent mappings to prevent timing out.
ClientThreads: Specifies the number of threads used to service client connections. One client connection is made for each database session or slave session if a map is parallelized. Most maps are parallelized, and the number of parallel processes is proportional to the number of processors. On a single-processor computer, two parallel processes are spawned for large maps. On a four processor computer, up to eight processes may be spawned. Parallelism may also be controlled by database initialization settings such as Sessions.
For the best performance, set ClientThreads to the maximum number of clients that is connected simultaneously. The actual number of connected clients is recorded in NASvr.log after a map run. You should increase the value of ClientThreads when the number of client connections shown in the log is greater.
When the number of clients exceeds the number of threads, all clients are still serviced because the threads are shared among clients.
Port: Specifies the port on which the server listens and was initially assigned by the installer. This value may be changed if the default port conflicts with another process. If the port is changed, then the port attribute must also be changed in the runtime_schema.nas_connection table to enable the utl_name_addr package to establish a connection.
Whenever you edit the properties file or perform table maintenance, you must stop and restart the Name and Address server for the changes to take effect.
To manually stop the Name and Addresss server:
On Windows, run OWB_HOME/owb/bin/win32/NAStop.bat.
On UNIX, run OWB_HOME/owb/bin/unix/NAStop.sh.
To manually restart the Name and Address Server:
On Windows, run OWB_HOME/owb/bin/win32/NAStart.bat.
On UNIX, run OWB_HOME/owb/bin/unix/NAStart.sh.
Alternatively, you can also automatically restart the Name and Address Server. However, before automatic startup, ensure that you grant the Execute privilege for the script OWB_HOME/owb/bin/unix/NAStart.sh to the OWBSYS schema.
For example, log in to SQL*Plus using the SYS user as SYSBDBA and run the following:
SQL> EXEC DBMS_JAVA.GRANT_PERMISSION( 'OWBSYS', 'SYS:java.io.FilePermission',
'/owb_11g/oracle/owb/bin/unix/NAStart.sh', 'execute' );
Here, /owb_11g is the path in which Oracle Warehouse Builder is installed.
|
Copyright © 2000, 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|