| Oracle® Database Object-Relational Developer's Guide 11g Release 2 (11.2) Part Number E11822-04 |
|
|
PDF · Mobi · ePub |
| Oracle® Database Object-Relational Developer's Guide 11g Release 2 (11.2) Part Number E11822-04 |
|
|
PDF · Mobi · ePub |
In an Oracle database, you can create object types with SQL data definition language (DDL) commands, and you can manipulate objects with SQL data manipulation language (DML) commands. From there, you can use many Oracle application programming environments and tools that have built-in support for Oracle Objects.
This chapter discusses the following topics:
Oracle SQL data definition language (DDL) provides the following support for object types:
Defining object types, nested tables, and arrays
Specifying privileges
Specifying table columns of object types
Creating object tables
Oracle SQL DML provides the following support for object types:
Querying and updating objects and collections
Manipulating REFs
See Also:
For a complete description of Oracle SQL syntax, see Oracle Database SQL Language ReferenceSQL Developer provides a visual development environment for database developers and DBAs to create and manipulate database schema objects including Oracle Objects, and to run reports, monitor performance and perform many other database-related tasks using a rich graphical user interface.
See Also:
Oracle Database Oracle SQL Developer User's GuideObject types and subtypes can be used in PL/SQL procedures and functions in most places where built-in types can appear.
The parameters and variables of PL/SQL functions and procedures can be of object types.
You can implement the methods associated with object types in PL/SQL. These methods (functions and procedures) reside on the server as part of a user's schema.
See Also:
For a complete description of PL/SQL, see the Oracle Database PL/SQL Language ReferenceOCI is a set of C library functions that applications can use to manipulate data and schemas in an Oracle database. OCI supports both traditional 3GL and object-oriented techniques for database access, as explained in the following sections.
An important component of OCI is a set of calls to manage a workspace called the object cache. The object cache is a memory block on the client side that allows programs to store entire objects and to navigate among them without additional round trips to the server.
The object cache is completely under the control and management of the application programs using it. The Oracle server has no access to it. The application programs using it must maintain data coherency with the server and protect the workspace against simultaneous conflicting access.
OCI provides functions to
Access, manipulate and manage objects in the object cache by traversing pointers or REFs.
Convert Oracle dates, strings and numbers to C data types.
Manage the size of the object cache's memory.
OCI improves concurrency by allowing individual objects to be locked. It improves performance by supporting complex object retrieval.
OCI developers can use the object type translator to generate the C data types corresponding to a Oracle object types.
See Also:
Oracle Call Interface Programmer's Guide for more information about using objects with OCITraditionally, 3GL programs manipulate data stored in a relational database by executing SQL statements and PL/SQL procedures. Data is usually manipulated on the server without incurring the cost of transporting the data to the client(s). OCI supports this associative access to objects by providing an API for executing SQL statements that manipulate object data. Specifically, OCI enables you to:
Execute SQL statements that manipulate object data and object type schema information
Pass object instances, object references (REFs), and collections as input variables in SQL statements
Return object instances, REFs, and collections as output of SQL statement fetches
Describe the properties of SQL statements that return object instances, REFs, and collections
Describe and execute PL/SQL procedures or functions with object parameters or results
Synchronize object and relational functionality through enhanced commit and rollback functions
In the object-oriented programming paradigm, applications model their real-world entities as a set of inter-related objects that form graphs of objects. The relationships between objects are implemented as references. An application processes objects by starting at some initial set of objects, using the references in these initial objects to traverse the remaining objects, and performing computations on each object. OCI provides an API for this style of access to objects, known as navigational access. Specifically, OCI enables you to:
Cache objects in memory on the client machine
Dereference an object reference and pin the corresponding object in the object cache. The pinned object is transparently mapped in the host language representation.
Notify the cache when the pinned object is no longer needed
Fetch a graph of related objects from the database into the client cache in one call
Lock objects
Create, update, and delete objects in the cache
Flush changes made to objects in the client cache to the database
To support high-performance navigational access of objects, OCI runtime provides an object cache for caching objects in memory. The object cache supports references (REFs) to database objects in the object cache, the database objects can be identified (that is, pinned) through their references. Applications do not need to allocate or free memory when database objects are loaded into the cache, because the object cache provides transparent and efficient memory management for database objects.
Also, when database objects are loaded into the cache, they are transparently mapped into the host language representation. For example, in the C programming language, the database object is mapped to its corresponding C structure. The object cache maintains the association between the object copy in the cache and the corresponding database object. Upon transaction commit, changes made to the object copy in the cache are propagated automatically to the database.
The object cache maintains a fast look-up table for mapping REFs to objects. When an application dereferences a REF and the corresponding object is not yet cached in the object cache, the object cache automatically sends a request to the server to fetch the object from the database and load it into the object cache. Subsequent dereferences of the same REF are faster because they become local cache access and do not incur network round-trips. To notify the object cache that an application is accessing an object in the cache, the application pins the object; when it is finished with the object, it unpins it. The object cache maintains a pin count for each object in the cache. The count is incremented upon a pin call and decremented upon an unpin call. When the pin count goes to zero, it means the object is no longer needed by the application. The object cache uses a least-recently used (LRU) algorithm to manage the size of the cache. When the cache reaches the maximum size, the LRU algorithm frees candidate objects with a pin count of zero.
When you build an OCI program that manipulates objects, you must complete the following general steps:
Define the object types that correspond to the application objects.
Execute the SQL DDL statements to populate the database with the necessary object types.
Represent the object types in the host language format.
For example, to manipulate instances of the object types in a C program, you must represent these types in the C host language format. You can do this by representing the object types as C structs. You can use a tool provided by Oracle called the Object Type Translator (OTT) to generate the C mapping of the object types. The OTT puts the equivalent C structs in header (*.h) files. You include these *.h files in the *.c files containing the C functions that implement the application.
Construct the application executable by compiling and linking the application's *.c files with the OCI library.
See Also:
Oracle Call Interface Programmer's Guide for tips and techniques for using OCI program effectively with objectsWhen defining a user-defined constructor in C, you must specify SELF (and you may optionally specify SELF TDO) in the PARAMETERS clause. On entering the C function, the attributes of the C structure that the object maps to are all initialized to NULL. The value returned by the function is mapped to an instance of the user-defined type. Example 4-1 shows how to define a user-defined constructor in C.
Example 4-1 Defining a User-Defined Constructor in C
CREATE LIBRARY person_lib TRUSTED AS STATIC
/
CREATE TYPE person AS OBJECT
( name VARCHAR2(30),
CONSTRUCTOR FUNCTION person(SELF IN OUT NOCOPY person, name VARCHAR2)
RETURN SELF AS RESULT);
/
CREATE TYPE BODY person IS
CONSTRUCTOR FUNCTION person(SELF IN OUT NOCOPY person, name VARCHAR2)
RETURN SELF AS RESULT
IS EXTERNAL NAME "cons_person_typ" LIBRARY person_lib WITH CONTEXT
PARAMETERS(context, SELF, name OCIString, name INDICATOR sb4);
END;/
The SELF parameter is mapped like an IN parameter, so in the case of a NOT FINAL type, it is mapped to (dvoid *), not (dvoid **).
The return value's TDO must match the TDO of SELF and is therefore implicit. The return value can never be null, so the return indicator is implicit as well.
The Oracle Pro*C/C++ precompiler allows programmers to use user-defined data types in C and C++ programs.
Pro*C developers can use the Object Type Translator to map Oracle object types and collections into C data types to be used in the Pro*C application.
Pro*C provides compile time type checking of object types and collections and automatic type conversion from database types to C data types.
Pro*C includes an EXEC SQL syntax to create and destroy objects and offers two ways to access objects in the server:
SQL statements and PL/SQL functions or procedures embedded in Pro*C programs.
An interface to the object cache (described under "Oracle Call Interface (OCI)"), where objects can be accessed by traversing pointers, then modified and updated on the server.
See Also:
For a complete description of the Pro*C precompiler, see Pro*C/C++ Programmer's Guide.For background information on associative access, see "Associative Access in OCI Programs".
Pro*C/C++ offers the following capabilities for associative access to objects:
Support for transient copies of objects allocated in the object cache
Support for transient copies of objects referenced as input host variables in embedded SQL INSERT, UPDATE, and DELETE statements, or in the WHERE clause of a SELECT statement
Support for transient copies of objects referenced as output host variables in embedded SQL SELECT and FETCH statements
Support for ANSI dynamic SQL statements that reference object types through the DESCRIBE statement, to get the object's type and schema information
For background information on navigational access, see "Navigational Access in OCI Programs".
Pro*C/C++ offers the following capabilities to support a more object-oriented interface to objects:
Support for dereferencing, pinning, and optionally locking an object in the object cache using an embedded SQL OBJECT DEREF statement
Allowing a Pro*C/C++ user to inform the object cache when an object has been updated or deleted, or when it is no longer needed, using embedded SQL OBJECT UPDATE, OBJECT DELETE, and OBJECT RELEASE statements
Support for creating new referenceable objects in the object cache using an embedded SQL OBJECT CREATE statement
Support for flushing changes made in the object cache to the server with an embedded SQL OBJECT FLUSH statement
The C representation for objects that is generated by the Oracle Type Translator (OTT) uses OCI types whose internal details are hidden, such as OCIString and OCINumber for scalar attributes. Collection types and object references are similarly represented using OCITable, OCIArray, and OCIRef types. While using these opaque types insulates you from changes to their internal formats, using such types in a C or C++ application is cumbersome. Pro*C/C++ provides the following ease-of-use enhancements to simplify use of OCI types in C and C++ applications:
Object attributes can be retrieved and implicitly converted to C types with the embedded SQL OBJECT GET statement.
Object attributes can be set and converted from C types with the embedded SQL OBJECT SET statement.
Collections can be mapped to a host array with the embedded SQL COLLECTION GET statement. Furthermore, if the collection is comprised of scalar types, then the OCI types can be implicitly converted to a compatible C type.
Host arrays can be used to update the elements of a collection with the embedded SQL COLLECTION SET statement. As with the COLLECTION GET statement, if the collection is comprised of scalar types, C types are implicitly converted to OCI types.
The Oracle Type Translator (OTT) is a program that automatically generates C language structure declarations corresponding to object types. OTT makes it easier to use the Pro*C precompiler and the OCI server access package.
See Also:
For complete information about OTT, see Oracle Call Interface Programmer's Guide and Pro*C/C++ Programmer's Guide.The Oracle C++ Call Interface (OCCI) is a C++ API that enables you to use the object-oriented features, native classes, and methods of the C++ programing language to access the Oracle database.
The OCCI interface is modeled on the JDBC interface and, like the JDBC interface, is easy to use. OCCI itself is built on top of OCI and provides the power and performance of OCI using an object-oriented paradigm.
OCI is a C API to the Oracle database. It supports the entire Oracle feature set and provides efficient access to both relational and object data, but it can be challenging to use—particularly if you want to work with complex, object data types. Object types are not natively supported in C, and simulating them in C is not easy. OCCI addresses this by providing a simpler, object-oriented interface to the functionality of OCI. It does this by defining a set of wrappers for OCI. By working with these higher-level abstractions, developers can avail themselves of the underlying power of OCI to manipulate objects in the server through an object-oriented interface that is significantly easier to program.
The Oracle C++ Call Interface, OCCI, can be roughly divided into three sets of functionalities, namely:
Associative relational access
Associative object access
Navigational access
The associative relational API and object classes provide SQL access to the database. Through these interfaces, SQL is executed on the server to create, manipulate, and fetch object or relational data. Applications can access any data type on the server, including the following:
Large objects
Objects/Structured types
Arrays
References
The navigational interface is a C++ interface that lets you seamlessly access and modify object-relational data in the form of C++ objects without using SQL. The C++ objects are transparently accessed and stored in the database as needed.
With the OCCI navigational interface, you can retrieve an object and navigate through references from that object to other objects. Server objects are materialized as C++ class instances in the application cache.
An application can use OCCI object navigational calls to perform the following functions on the server's objects:
Create, access, lock, delete, and flush objects
Get references to the objects and navigate through them
See Also:
Oracle C++ Call Interface Programmer's Guide for a complete account of how to build applications with the Oracle C++ APIOracle Objects for OLE (OO4O) provides full support for accessing and manipulating instances of REFs, value instances, variable-length arrays (VARRAYs), and nested tables in an Oracle database server.
On Windows systems, you can use Oracle Objects for OLE (OO4O) to write object-oriented database programs in Visual Basic or other environments that support the COM protocol, such as Excel, ActiveX, and Active Server Pages.
See Also:
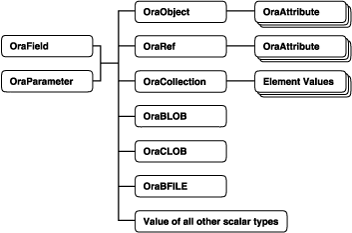
The "Server Objects" chapter of the Oracle Objects for OLE Oracle Objects for OLE Developer's Guide for detailed information and examples on using OO4O with Oracle objectsFigure 4-1 illustrates the containment hierarchy for value instances of all types in OO4O.
Instances of these types can be fetched from the database or passed as input or output variables to SQL statements and PL/SQL blocks, including stored procedures and functions. All instances are mapped to COM Automation Interfaces that provide methods for dynamic attribute access and manipulation. These interfaces may be obtained from:
The value property of an OraField object in a dynaset
The value property of an OraParameter object used as an input or an output parameter in SQL Statements or PL/SQL blocks
An attribute of an object (REF)
An element in a collection (varray or a nested table)
The OraObject interface is a representation of an Oracle embedded object or a value instance. It contains a collection interface (OraAttributes) for accessing and manipulating (updating and inserting) individual attributes of a value instance. Individual attributes of an OraAttributes collection interface can be accessed by using a subscript or the name of the attribute.
The following Visual Basic example illustrates how to access attributes of the Address object in the person_tab table:
Dim Address OraObjectSet Person = OraDatabase.CreateDynaset("select * from person_tab", 0&)Set Address = Person.Fields("Addr").ValueMsgbox Address.ZipMsgbox.Address.CityThe OraRef interface represents an Oracle object reference (REF) as well as referenceable objects in client applications. The object attributes are accessed in the same manner as attributes of an object represented by the OraObject interface. OraRef is derived from an OraObject interface by means of the containment mechanism in COM. REF objects are updated and deleted independent of the context they originated from, such as dynasets. The OraRef interface also encapsulates the functionality for navigating through graphs of objects utilizing the Complex Object Retrieval Capability (COR) in OCI.
See Also:
Oracle Call Interface Programmer's Guide for tips and techniques for using OCI program effectively with objectsThe OraCollection interface provides methods for accessing and manipulating Oracle collection types, namely variable-length arrays (VARRAYs) and nested tables in OO4O. Elements contained in a collection are accessed by subscripts.
The following Visual Basic example illustrates how to access attributes of the EnameList object from the department table:
Dim EnameList OraCollectionSet Person = OraDatabase.CreateDynaset("select * from department", 0&)Set EnameList = Department.Fields("Enames").Value'The following loop accesses all elements of'the EnameList VArrayFor I=1 to I=EnameList.Size Msgbox EnameList(I)Next IJava has emerged as a powerful, modern object-oriented language that provides developers with a simple, efficient, portable, and safe application development platform. Oracle provides various ways to integrate Oracle object features with Java. These interfaces enable you both to access SQL data from Java and to provide persistent database storage for Java objects.
JDBC (Java Database Connectivity) is a set of Java interfaces to the Oracle server. Oracle provides tight integration between objects and JDBC. You can map SQL types to Java classes with considerable flexibility.
Oracle JDBC:
Allows access to objects and collection types (defined in the database) in Java programs through dynamic SQL.
Translates types defined in the database into Java classes through default or customizable mappings.
Version 2.0 of the JDBC specification supports object-relational constructs such as user-defined (object) types. JDBC materializes Oracle objects as instances of particular Java classes. Using JDBC to access Oracle objects involves creating the Java classes for the Oracle objects and populating these classes. You can either:
Let JDBC materialize the object as a STRUCT. In this case, JDBC creates the classes for the attributes and populates them for you.
Manually specify the mappings between Oracle objects and Java classes; that is, customize your Java classes for object data. The driver then populates the customized Java classes that you specify, which imposes a set of constraints on the Java classes. To satisfy these constraints, you can choose to define your classes according to either the SQLData interface or the ORAData interface.
See Also:
For complete information about JDBC, see the Oracle Database JDBC Developer's Guide and Reference.SQLJ provides access to server objects using SQL statements embedded in the Java code:
You can use user-defined types in Java programs.
You can use JPublisher to map Oracle object and collection types into Java classes to be used in the application.
The object types and collections in the SQL statements are checked at compile time.
See Also:
For complete information about SQLJ, see the Oracle Database Java Developer's Guide.Oracle SQLJ supports either strongly typed or weakly typed Java representations of object types, reference types (REFs), and collection types (varrays and nested tables) to be used in iterators or host expressions.
Strongly typed representations use a custom Java class that corresponds to a particular object type, REF type, or collection type and must implement the interface oracle.sql.ORAData. The Oracle JPublisher utility can automatically generate such custom Java classes.
Weakly typed representations use the class oracle.sql.STRUCT (for objects), oracle.sql.REF (for references), or oracle.sql.ARRAY (for collections).
Oracle JPublisher is a utility that generates Java classes to represent the following user-defined database entities in your Java program:
Database object types
Database reference (REF) types
Database collection types (varrays or nested tables)
PL/SQL packages
JPublisher enables you to specify and customize the mapping of database object types, reference types, and collection types (varrays or nested tables) to Java classes, in a strongly typed paradigm.
See Also:
Oracle Database JPublisher User's GuideOracle lets you map Oracle object types, reference types, and collection types to Java classes and preserve all the benefits of strong typing. You can:
Use JPublisher to automatically generate custom Java classes and use those classes without any change.
Subclass the classes produced by JPublisher to create your own specialized Java classes.
Manually code custom Java classes without using JPublisher if the classes meet the requirements stated in Oracle Database JPublisher User's Guide.
We recommend that you use JPublisher and subclass when the generated classes do not do everything you need.
When you run JPublisher for a user-defined object type, it automatically creates the following:
A custom object class to act as a type definition to correspond to your Oracle object type
This class includes getter and setter methods for each attribute. The method names are of the form getXxx() and setXxx() for attribute xxx.
Also, you can optionally instruct JPublisher to generate wrapper methods in your class that invoke the associated Oracle object methods executing in the server.
A related custom reference class for object references to your Oracle object type
This class includes a getValue() method that returns an instance of your custom object class, and a setValue() method that updates an object value in the database, taking as input an instance of the custom object class.
When you run JPublisher for a user-defined collection type, it automatically creates the following:
A custom collection class to act as a type definition to correspond to your Oracle collection type
This class includes overloaded getArray() and setArray() methods to retrieve or update a collection as a whole, a getElement() method and setElement() method to retrieve or update individual elements of a collection, and additional utility methods.
JPublisher-produced custom Java classes in any of these categories implement the ORAData interface and the getFactory() method.
See Also:
The Oracle Database JPublisher User's Guide for more information about using JPublisher.JPublisher enables you to construct Java classes that map to existing SQL types. You can then access the SQL types from a Java application using JDBC.
You can also go in the other direction. That is, you can create SQL types that map to existing Java classes. This capability enables you to provide persistent storage for Java objects. Such SQL types are called SQL types of Language Java, or SQLJ object types. They can be used as the type of an object, an attribute, a column, or a row in an object table. You can navigationally access objects of such types—Java objects—through either object references or foreign keys, and you can query and manipulate such objects from SQL.
You create SQLJ types with a CREATE TYPE statement as you do other user-defined SQL types. For SQLJ types, two special elements are added to the CREATE TYPE statement:
An EXTERNAL NAME phrase, used to identify the Java counterpart for each SQLJ attribute and method and the Java class corresponding to the SQLJ type itself
A USING clause, to specify how the SQLJ type is to be represented to the server. The USING clause specifies the interface used to retrieve a SQLJ type and the kind of storage.
For example:
Example 4-2 Mapping SQL Types to Java Classes
-- Mapping SQL Types to Java Classes example, not sample schema
CREATE TYPE full_address AS OBJECT (a NUMBER);
/
CREATE OR REPLACE TYPE person_t AS OBJECT
EXTERNAL NAME 'Person' LANGUAGE JAVA
USING SQLData (
ss_no NUMBER (9) EXTERNAL NAME 'socialSecurityNo',
name varchar(100) EXTERNAL NAME 'name',
address full_address EXTERNAL NAME 'addrs',
birth_date date EXTERNAL NAME 'birthDate',
MEMBER FUNCTION age RETURN NUMBER EXTERNAL NAME 'age () return int',
MEMBER FUNCTION addressf RETURN full_address
EXTERNAL NAME 'get_address () return long_address',
STATIC function createf RETURN person_t EXTERNAL NAME 'create ()
return Person',
STATIC function createf (name VARCHAR2, addrs full_address, bDate DATE)
RETURN person_t EXTERNAL NAME 'create (java.lang.String, Long_address,
oracle.sql.date) return Person',
ORDER member FUNCTION compare (in_person person_t) RETURN NUMBER
EXTERNAL NAME 'isSame (Person) return int')
/
SQLJ types use the corresponding Java class as the body of the type; you do not specify a type body in SQL to contain implementations of the type's methods as you do with ordinary object types.
How a SQLJ type is represented to the server and stored depends on the interfaces implemented by the corresponding Java class. Currently, Oracle supports a representation of SQLJ types only for Java classes that implement a SQLData or ORAData interface. These are represented to the server and are accessible through SQL. A representation for Java classes that implement the java.io.Serializable interface is not currently supported.
In a SQL representation, the attributes of the type are stored in columns like attributes of ordinary object types. With this representation, all attributes are public because objects are accessed and manipulated through SQL statements, but you can use triggers and constraints to ensure the consistency of the object data.
For a SQL representation, the USING clause must specify either SQLData or ORAData, and the corresponding Java class must implement one of those interfaces. The EXTERNAL NAME clause for attributes is optional.
The SQL statements to create SQLJ types and specify their mappings to Java are placed in a file called a deployment descriptor. Related SQL constraints and privileges are also specified in this file. The types are created when the file is executed.
Below is an overview of the process of creating SQL versions of Java types/classes:
Design the Java types.
Generate the Java classes.
Create the SQLJ object type statements.
Construct the JAR file. This is a single file that contains all the classes needed.
Using the loadjava utility, install the Java classes defined in the JAR file.
Execute the statements to create the SQLJ object types.
The following are additional notes to consider when mapping of Java classes to SQL types:
You can map a SQLJ static function to a user-defined constructor in the Java class. The return value of this function is of the user-defined type in which the function is locally defined.
Java static variables are mapped to SQLJ static methods that return the value of the corresponding static variable identified by EXTERNAL NAME. The EXTERNAL NAME clause for an attribute is optional with a SQLData or ORAData representation.
Every attribute in a SQLJ type of a SQL representation must map to a Java field, but not every Java field must be mapped to a corresponding SQLJ attribute: you can omit Java fields from the mapping.
You can omit classes: you can map a SQLJ type to a non-root class in a Java class hierarchy without also mapping SQLJ types to the root class and intervening superclasses. Doing this enables you to hide the superclasses while still including attributes and methods inherited from them.
However, you must preserve the structural correspondence between nodes in a class hierarchy and their counterparts in a SQLJ type hierarchy. In other words, for two Java classes j_A and j_B that are related through inheritance and are mapped to two SQL types s_A and s_B, respectively, there must be exactly one corresponding node on the inheritance path from s_A to s_B for each node on the inheritance path from j_A to j_B.
You can map a Java class to multiple SQLJ types as long as you do not violate the restriction in the preceding paragraph. In other words, no two SQLJ types mapped to the same Java class can have a common supertype ancestor.
If all Java classes are not mapped to SQLJ types, it is possible that an attribute of a SQLJ object type might be set to an object of an unmapped Java class. Specifically, to a class occurring above or below the class to which the attribute is mapped in an inheritance hierarchy. If the object's class is a superclass of the attribute's type/class, an error is raised. If it is a subclass of the attribute's type/class, the object is mapped to the most specific type in its hierarchy for which a SQL mapping exists
See Also:
The Oracle Database JPublisher User's Guide for JPublisher examples of object mappingThe ALTER TYPE statement enables you to evolve a type by, for example, adding or dropping attributes or methods.
When a SQLJ type is evolved, an additional validation is performed to check the mapping between the class and the type. If the class and the evolved type match, the type is marked valid. Otherwise, the type is marked as pending validation.
Being marked as pending validation is not the same as being marked invalid. A type that is pending validation can still be manipulated with ALTER TYPE and GRANT statements, for example.
If a type that has a SQL representation is marked as pending evaluation, you can still access tables of that type using any DML or SELECT statement that does not require a method invocation.
You cannot, however, execute DML or SELECT statements on tables of a type that has a serializable representation and has been marked as pending validation. Data of a serializable type can be accessed only navigationally, through method invocations. These are not possible with a type that is pending validation. However, you can still re-evolve the type until it passes validation.
See "Type Evolution".
For SQLJ types having a SQL representation, the same constraints can be defined as for ordinary object types.
Constraints are defined on tables, not on types, and are defined at the column level. The following constraints are supported for SQLJ types having a SQL representation:
Unique constraints
Primary Key
Check constraints
NOT NULL constraints on attributes
Referential constraints
The IS OF TYPE constraint on column substitutability is supported, too, for SQLJ types having a SQL representation. See "Constraining Substitutability".
SQLJ types can be queried just like ordinary SQL object types. Methods called in a SELECT statement must not attempt to change attribute values.
Inserting a row in a table containing a column of a SQLJ type requires a call to the type's constructor function to create a Java object of that type.
The implicit, system-generated constructor can be used, or a static function can be defined that maps to a user-defined constructor in the Java class.
SQLJ objects can be updated either by using an UPDATE statement to modify the value of one or more attributes, or by invoking a method that updates the attributes and returns SELF—that is, returns the object itself with the changes made.
For example, suppose that raise() is a member function that increments the salary field/attribute by a specified amount and returns SELF. The following statement gives every employee in the object table employee_objtab a raise of 1000:
UPDATE employee_objtab SET c=c.raise(1000);
A column of a SQLJ type can be set to NULL or to another column using the same syntax as for ordinary object types. For example, the following statement assigns column d to column c:
UPDATE employee_reltab SET c=d;
When you implement a user-defined constructor in Java, the string supplied as the implementing routine must correspond to a static function. For the return type of the function, specify the Java type mapped to the SQL type.
Example 4-3 is an example of a type declaration that involves a user-defined constructor implemented in Java.
Example 4-3 Defining a User-Defined Constructor in Java
-- Defining a User-Defined Constructor in Java example, not sample schema
CREATE TYPE person1_typ AS OBJECT
EXTERNAL NAME 'pkg1.J_Person' LANGUAGE JAVA
USING SQLData(
name VARCHAR2(30),
age NUMBER,
CONSTRUCTOR FUNCTION person1_typ(SELF IN OUT NOCOPY person1_typ, name VARCHAR2,
age NUMBER) RETURN SELF AS RESULT
AS LANGUAGE JAVA
NAME 'pkg1.J_Person.J_Person(java.lang.String, int) return J_Person')
/
DROP TYPE person1_typ FORCE; DROP TYPE person_t FORCE; DROP TYPE full_address FORCE; DROP TYPE person FORCE; DROP LIBRARY person_lib; SPOOL OFF COMMIT;
Oracle JDeveloper is a full-featured, cross-platform, integrated development environment for creating multitier Java applications that is well integrated with Oracle Application Server and Database.
Oracle JDeveloper enables you to develop, debug, and deploy Java client applications, dynamic HTML applications, web and application server components, JavaBean components, and database stored procedures based on industry-standard models.
JDeveloper is also the integrated development environment for ADF and TopLink.
ADF is a framework for building scalable enterprise Java EE applications. Developers can use ADF to build applications where the application data is persisted to Oracle Object tables as well as other schema objects.
XMLType views wrap existing relational and object-relational data in XML formats. These views are similar to object views. Each row of an XMLType view corresponds to an XMLType instance. The object identifier for uniquely identifying each row in the view can be created using an expression such as extract() on the XMLType value.
See Also:
Oracle XML DB Developer's Guide for information and examples on using XML with Oracle objectsThis section describes several Oracle utilities that provide support for Oracle objects.
This section contains these topics:
Export and Import utilities move data into and out of Oracle databases. They also back up or archive data and aid migration to different releases of the Oracle RDBMS.
Export and Import support object types. Export writes object type definitions and all of the associated data to the dump file. Import then re-creates these items from the dump file.
When you import object tables, by default, OIDs are preserved.
See Also:
Oracle Database Utilities for instructions on how to use the Import and Export utilitiesThe definition statements for derived types are exported. On an Import, a subtype may be created before the supertype definition has been imported. In this case, the subtype is created with compilation errors, which may be ignored. The type is revalidated after its supertype is created.
The SQL*Loader utility moves data from external files into tables in an Oracle database. The files may contain data consisting of basic scalar data types, such as INTEGER, CHAR, or DATE, as well as complex user-defined data types such as row and column objects (including objects that have object, collection, or REF attributes), collections, and LOBs. Currently, SQL*Loader supports single-level collections only: you cannot yet use SQL*Loader to load multilevel collections, that is, collections whose elements are, or contain, other collections. SQL*Loader uses control files, which contain SQL*Loader data definition language (DDL) statements, to describe the format, content, and location of the datafiles.
SQL*Loader provides two approaches to loading data:
Conventional path loading, which uses the SQL INSERT statement and a bind array buffer to load data into database tables
Direct path loading, which uses the Direct Path Load API to write data blocks directly to the database on behalf of the SQL*Loader client.
Direct path loading does not use a SQL interface and thus avoids the overhead of processing the associated SQL statements. Consequently, direct path loading generally provides much better performance than conventional path loading.
Either approach can be used to load data of supported object and collection data types.
See Also:
Oracle Database Utilities for instructions on how to use SQL*Loader
|
Copyright © 1996, 2011, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|